LoRA,英文全称Low-Rank Adaptation of Large Language Models,直译为大语言模型的低阶适应,这是微软的研究人员为了解决大语言模型微调而开发的一项技术。 比如,GPT-3有1750亿参数,为了让它能干特定领域的活儿,需要做微调,但是如果直接对GPT-3做微调,成本太高太麻烦了。
LoRA的做法是,冻结预训练好的模型权重参数,然后在每个Transformer(Transforme就是GPT的那个T)块里注入可训练的层,由于不需要对模型的权重参数重新计算梯度,所以,大大减少了需要训练的计算量。 研究发现,LoRA的微调质量与全模型微调相当,要做个比喻的话,就好比是大模型的一个小模型,或者说是一个插件。
根据显卡性能不同,训练一般需要一个到几个小时的时间,这个过程俗称炼丹!
主要步骤有以下这些,话不多说,开整!
1. 显卡
首先是要有显卡了,推荐8G显存以上的N卡。然后就是装GPU驱动,可以参考我以前文章centos中docker使用GPU
2. 训练环境
自从有了docker,我就不喜欢在宿主机上装一堆开发环境了,所以这次就直接使用stable-diffusion-webui带webui打包好的镜像,也方便训练完成以后测试。推荐一下 kestr3l/stable-diffusion-webui 这个镜像,是基于 nvidia/cuda:11.7.1-devel-ubuntu22.04 镜像,本人亲自测试过,可用的。 附一个我用的 docker-compose.yml 文件
version: "3"
services:
sd-webui:
image: kestr3l/stable-diffusion-webui:1.1.0
container_name: sd-webui
restart: always
ports:
- "7860:7860"
- "7861:7861"
ulimits:
memlock: -1
stack: 67108864
shm_size: 4G
deploy:
resources:
limits:
cpus: "8.00"
memory: 16G
reservations:
devices:
- capabilities: [gpu]
volumes:
# 这里主要是方便映射下载的模型文件
- ./models:/home/user/stable-diffusion-webui/models:cached
# 修改容器的默认启动脚本,方便我们手动控制
- ./entrypoint-debug.sh:/usr/local/bin/entrypoint.sh:cached
entrypoint-debug.sh文件内容:
#! /bin/sh
python3
可以去 civitai 下载 stable diffusion 的模型,放到宿主机的 ./models/Stable-diffusion 目录下面,也可以去下载一些LoRA模型丢在./models/Lora 目录下。
模型准备完毕了就可以跑个 stable diffusion 图形化界面试试看, 执行./webui.sh -f --listen 命令,启动之前会下载安装很多依赖包,国内环境不太顺,可以上代理安装。
如果输出以下内容,则表示安装成功:
root@cebe51b82933:/home/user/stable-diffusion-webui# ./webui.sh -f --listen
################################################################
Install script for stable-diffusion + Web UI
Tested on Debian 11 (Bullseye)
################################################################
################################################################
Running on root user
################################################################
################################################################
Repo already cloned, using it as install directory
################################################################
################################################################
Create and activate python venv
################################################################
################################################################
Launching launch.py...
################################################################
./webui.sh: line 168: lspci: command not found
Python 3.10.6 (main, Nov 14 2022, 16:10:14) [GCC 11.3.0]
Commit hash: <none>
Installing requirements for Web UI
Launching Web UI with arguments: --listen
No module 'xformers'. Proceeding without it.
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
Loading weights [fc2511737a] from /home/user/stable-diffusion-webui/models/Stable-diffusion/chilloutmix_NiPrunedFp32Fix.safetensors
Applying cross attention optimization (Doggettx).
Textual inversion embeddings loaded(0):
Model loaded in 16.0s (0.8s create model, 14.9s load weights).
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
打开浏览器访问:http://127.0.0.1:7860 或者 http://内网ip:7860 就可以AI绘画了 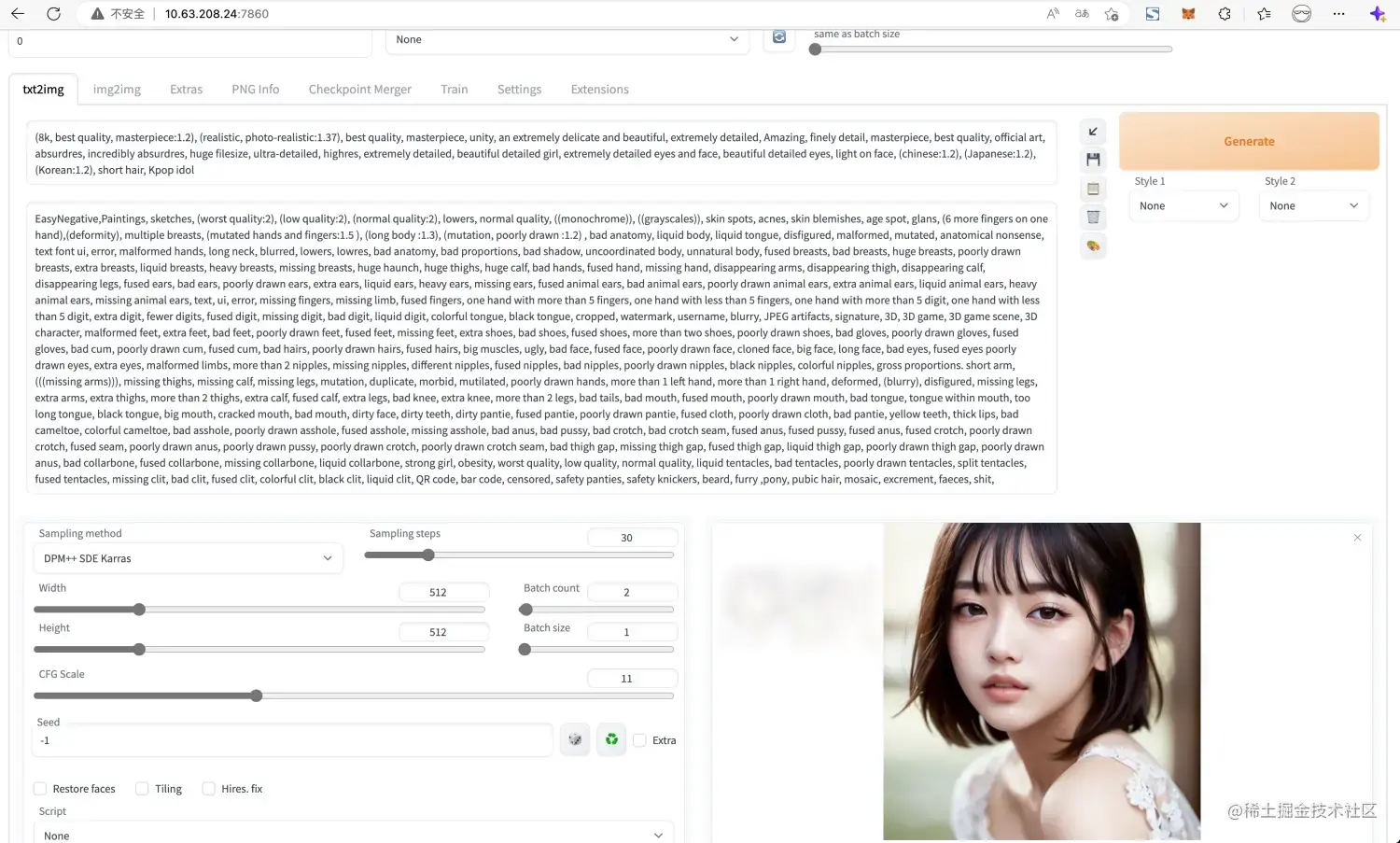


不得不说 chilloutmix_NiPrunedFp32Fix 模型生成的图片是针不戳😍!
3. 安装训练图形化界面
为了降低训练门槛,这里选用的是基于Gradio做的一个WebGui图形化界面,该项目在GitHub上叫Kohya’s GUI。
# 下载项目
git clone https://github.com/bmaltais/kohya_ss.git
# 执行安装脚本
cd kohya_ss
bash ubuntu_setup.sh
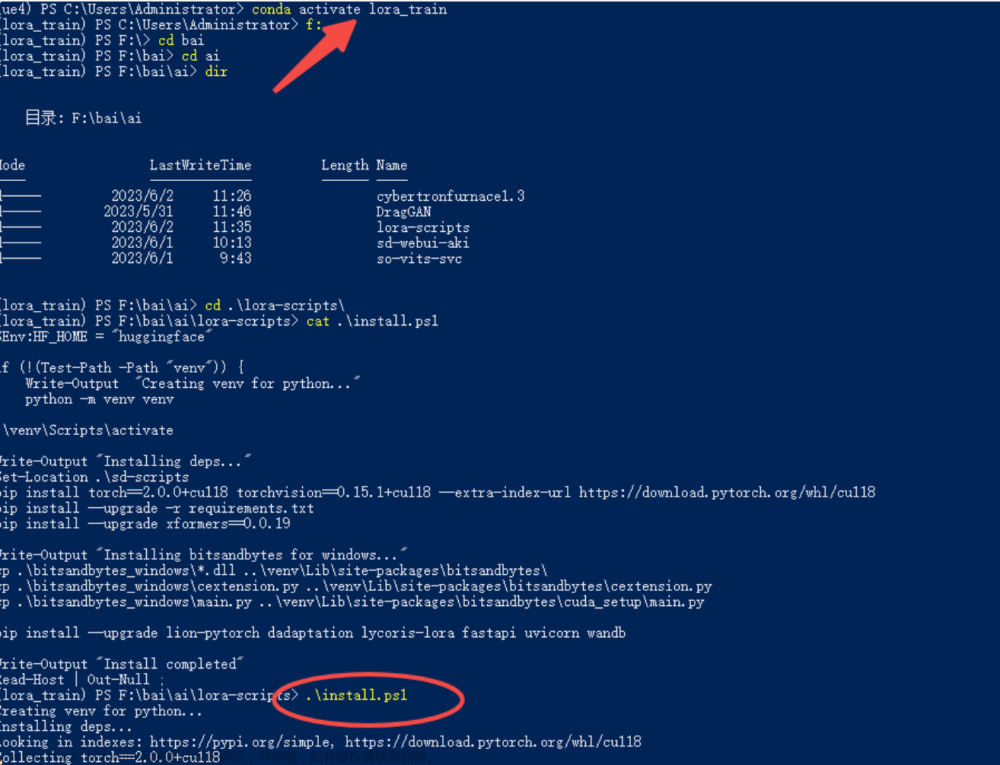
由于是在docker内部执行,ubuntu_setup.sh 脚本可能有问题,所以我一般是直接进入容器,手动单条执行
apt install python3-tk
python3 -m venv venv
source venv/bin/activate
pip install torch==1.12.1+cu116 torchvision==0.13.1+cu116 --extra-index-url https://download.pytorch.org/whl/cu116
pip install --use-pep517 --upgrade -r requirements.txt
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/linux/xformers-0.0.14.dev0-cp310-cp310-linux_x86_64.whl
执行accelerate config命令,生成对应配置文件,选项如下:
(venv) root@cebe51b82933:/home/user/kohya_ss# accelerate config
2023-03-13 06:45:22.678222: I tensorflow/core/platform/cpu_feature_guard.cc:193] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-03-13 06:45:22.922383: E tensorflow/stream_executor/cuda/cuda_blas.cc:2981] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2023-03-13 06:45:23.593040: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer.so.7'; dlerror: libnvinfer.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /usr/local/cuda-11.7/lib64:/usr/local/nvidia/lib:/usr/local/nvidia/lib64
2023-03-13 06:45:23.593158: W tensorflow/stream_executor/platform/default/dso_loader.cc:64] Could not load dynamic library 'libnvinfer_plugin.so.7'; dlerror: libnvinfer_plugin.so.7: cannot open shared object file: No such file or directory; LD_LIBRARY_PATH: /usr/local/cuda-11.7/lib64:/usr/local/nvidia/lib:/usr/local/nvidia/lib64
2023-03-13 06:45:23.593177: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Cannot dlopen some TensorRT libraries. If you would like to use Nvidia GPU with TensorRT, please make sure the missing libraries mentioned above are installed properly.
--------------------------------------------------------------------------------------------------In which compute environment are you running?
This machine
--------------------------------------------------------------------------------------------------Which type of machine are you using?
No distributed training
Do you want to run your training on CPU only (even if a GPU is available)? [yes/NO]:NO
Do you wish to optimize your script with torch dynamo?[yes/NO]:NO
Do you want to use DeepSpeed? [yes/NO]: NO
What GPU(s) (by id) should be used for training on this machine as a comma-seperated list? [all]:all
--------------------------------------------------------------------------------------------------Do you wish to use FP16 or BF16 (mixed precision)?
fp16
accelerate configuration saved at /root/.cache/huggingface/accelerate/default_config.yaml
4. 启动训练图形化界面
执行命令python kohya_gui.py --listen 0.0.0.0 --server_port 7861 --inbrowser --share
(venv) root@cebe51b82933:/home/user/kohya_ss# python kohya_gui.py --listen 0.0.0.0 --server_port 7861 --inbrowser --share
Load CSS...
Running on local URL: http://0.0.0.0:7861
Running on public URL: https://49257631b1b39d3db5.gradio.live
This share link expires in 72 hours. For free permanent hosting and GPU upgrades (NEW!), check out Spaces: https://huggingface.co/spaces
这时候浏览器就可以打开http://127.0.0.1:7861 端口了,界面如下: 
5. 准备要训练的图片
找到你要用来训练的一些图片放到统一文件夹下,建议15张以上,我这里就用汤唯的照片: 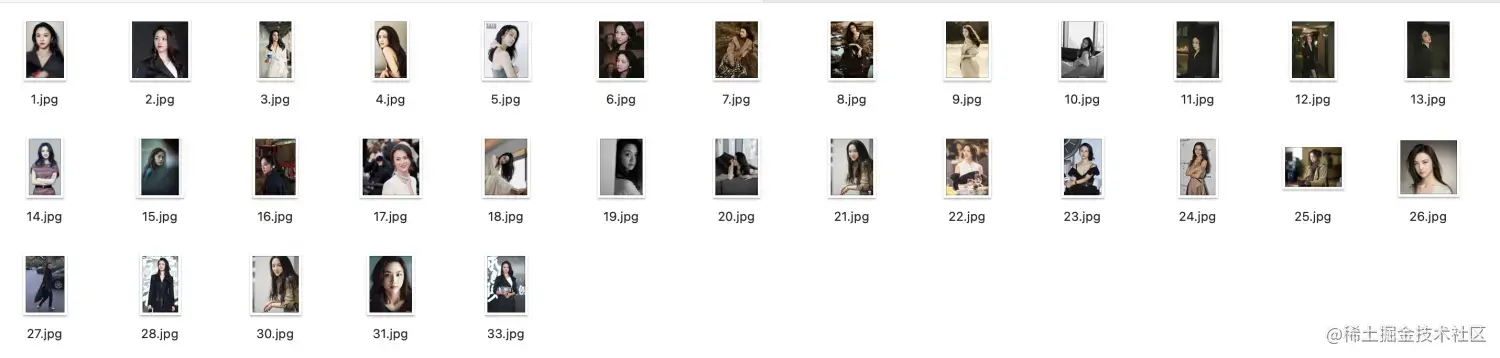
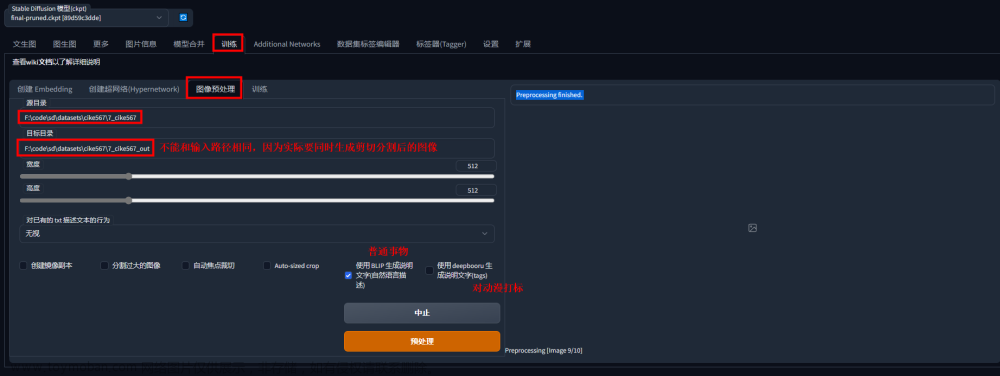
然后打开stable diffusion webui来预处理这些图片: 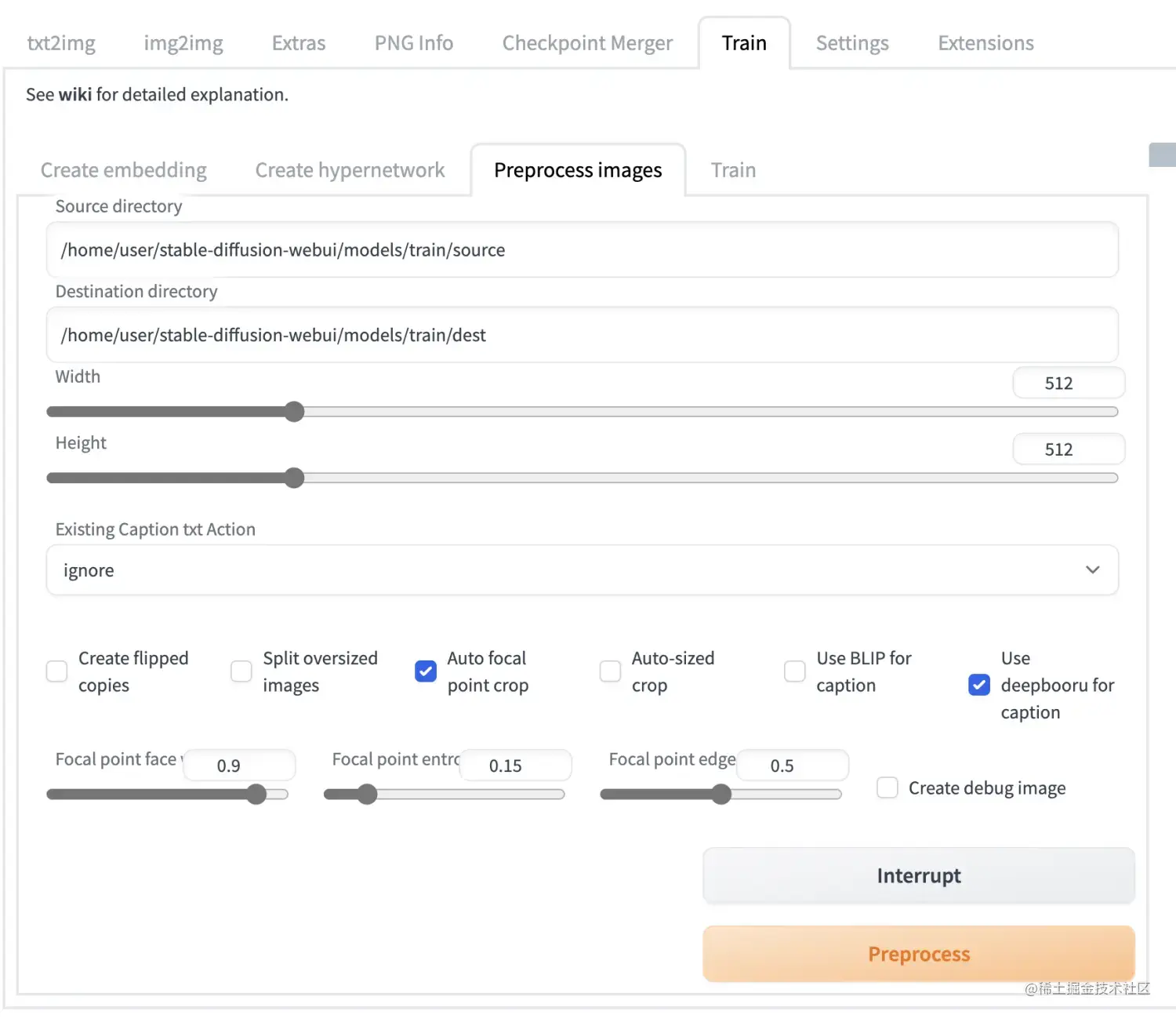
点击Preprocess按钮,等待处理完成。顺利的的话会在dest文件夹下生成512*512的图片,和描述词文件 
6. 开始训练
我们去训练的界面,需要设置一堆参数,直接看图吧
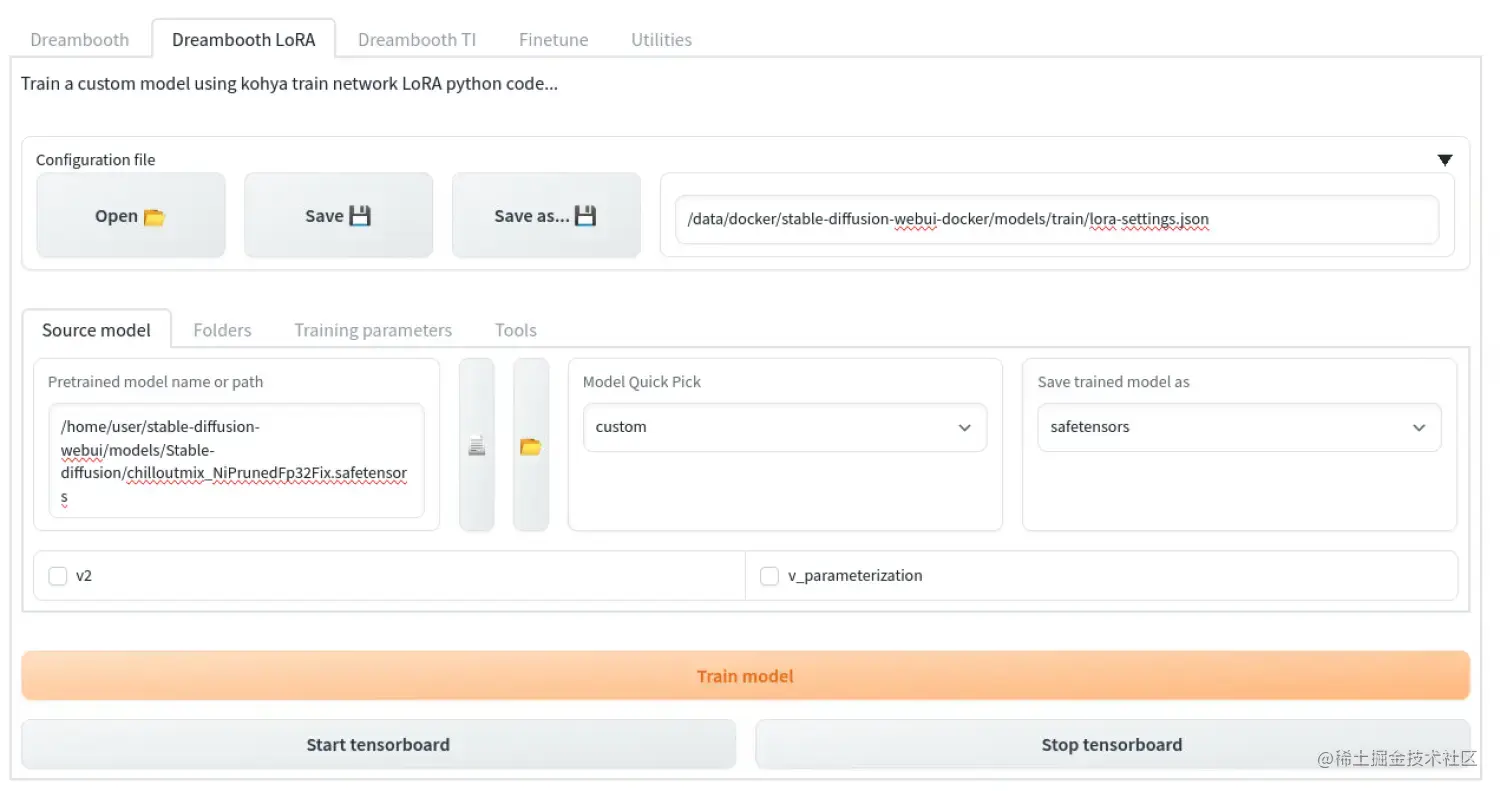
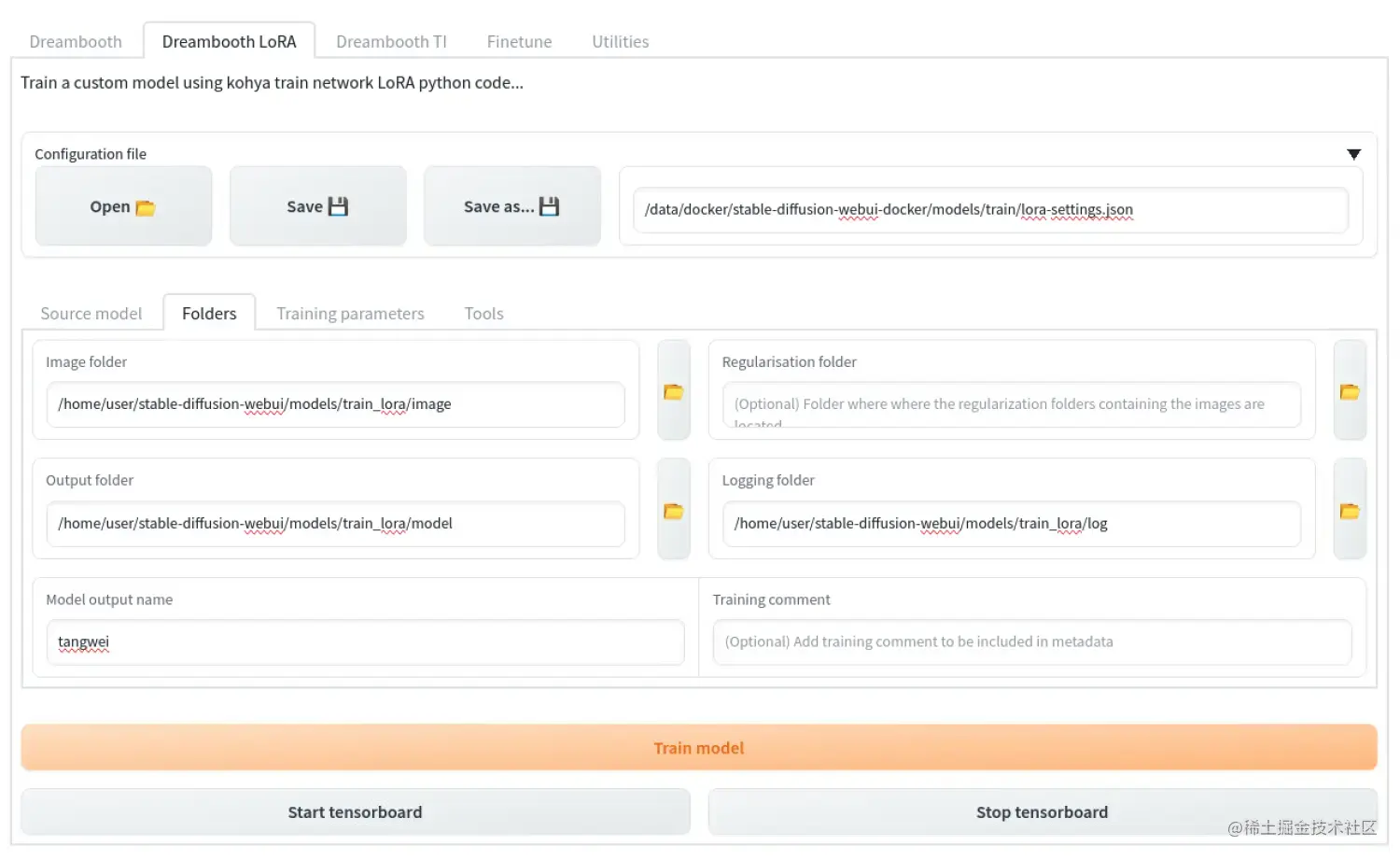
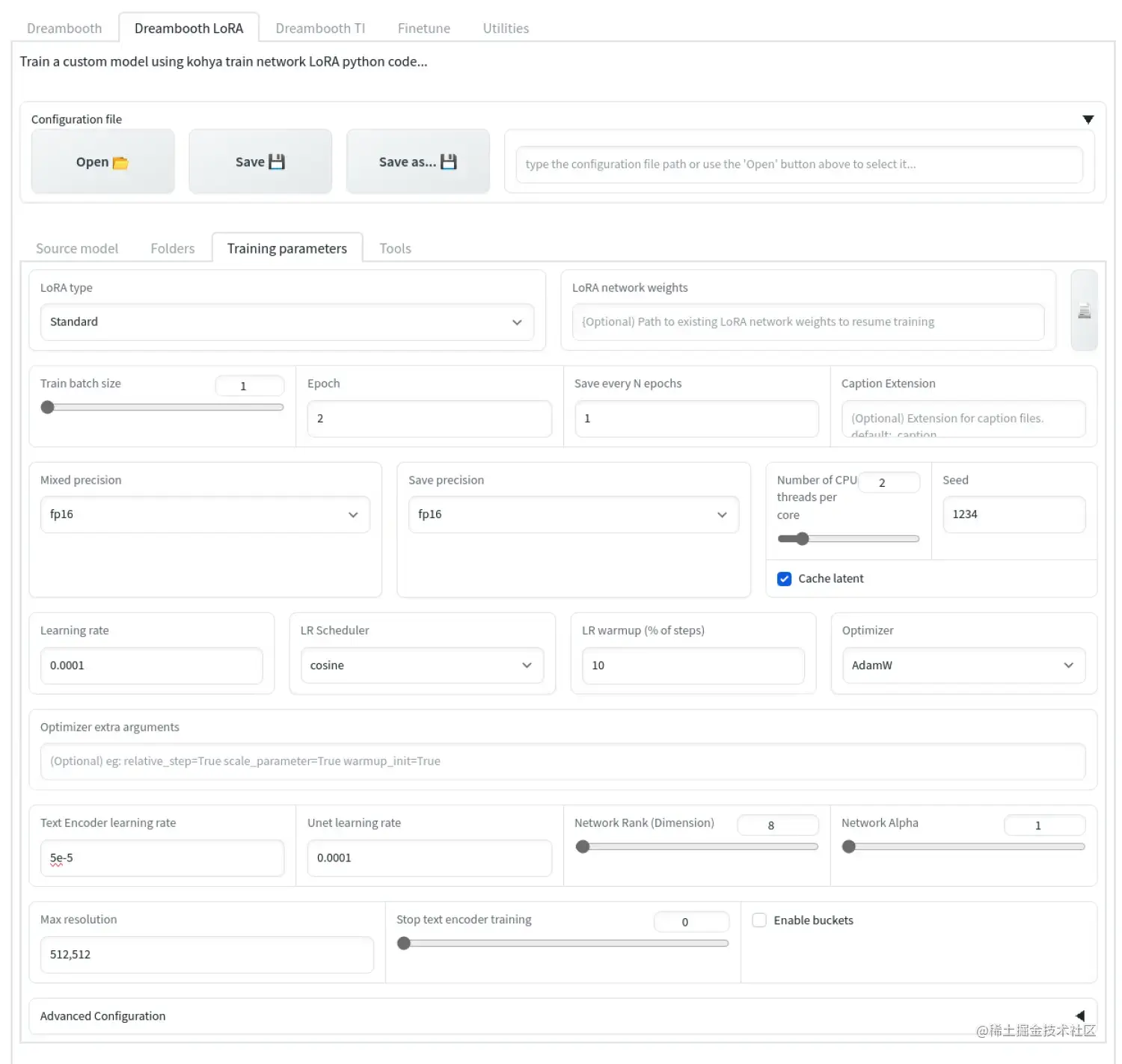
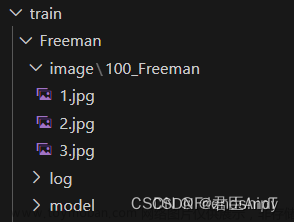
建议新建立文件夹,比如我这里叫train_lora,在文件夹里创建image、log和model三个文件夹,其中,image里存放的图片就是预处理生成的图片。 image里的预处理图片不能直接放在里面,需要在里面创建一个文件夹,文件夹的命名非常有讲究。 已知,LoRa的训练需要至少1500步,而每张图片至少需要训练100步。 如果我们有15张或者15张以上张图片,文件夹就需要写上100_Hunzi。 如果训练的图片不够15张,比如10张,就需要改为150_Hunzi,以此类推。 这部分很重要,一定要算清楚。 当然,这也正是LoRa强大的地方,用这么少的图片即可完成训练。
点击训练按钮,开始炼丹: 
生成的丹就在train_lora/model文件夹下面: 
最终使用这个丹的生成的图片效果展示: 

写在最后
感兴趣的小伙伴,赠送全套AIGC学习资料,包含AI绘画、AI人工智能等前沿科技教程和软件工具,具体看这里。
AIGC技术的未来发展前景广阔,随着人工智能技术的不断发展,AIGC技术也将不断提高。未来,AIGC技术将在游戏和计算领域得到更广泛的应用,使游戏和计算系统具有更高效、更智能、更灵活的特性。同时,AIGC技术也将与人工智能技术紧密结合,在更多的领域得到广泛应用,对程序员来说影响至关重要。未来,AIGC技术将继续得到提高,同时也将与人工智能技术紧密结合,在更多的领域得到广泛应用。
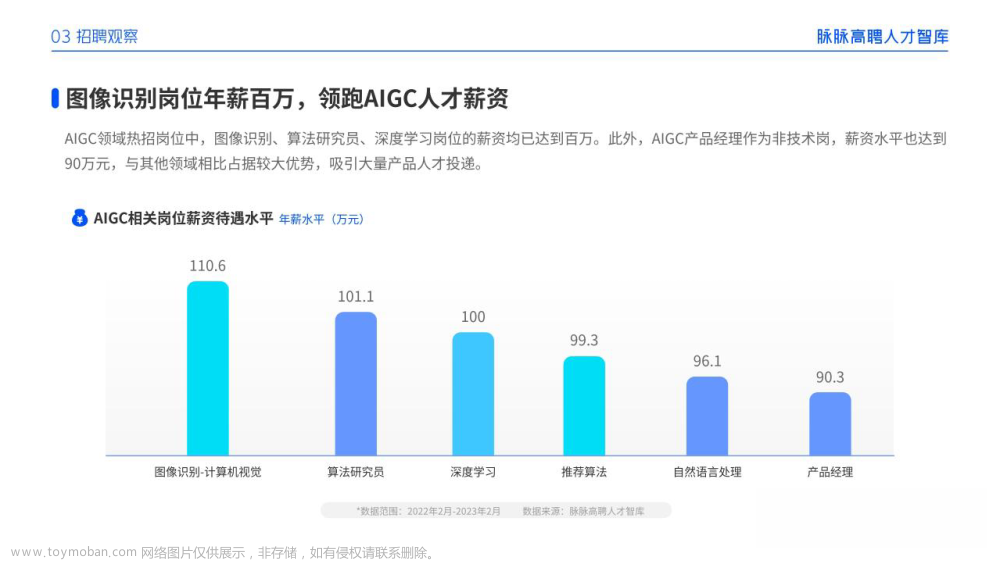
一、AIGC所有方向的学习路线
AIGC所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。
二、AIGC必备工具
工具都帮大家整理好了,安装就可直接上手!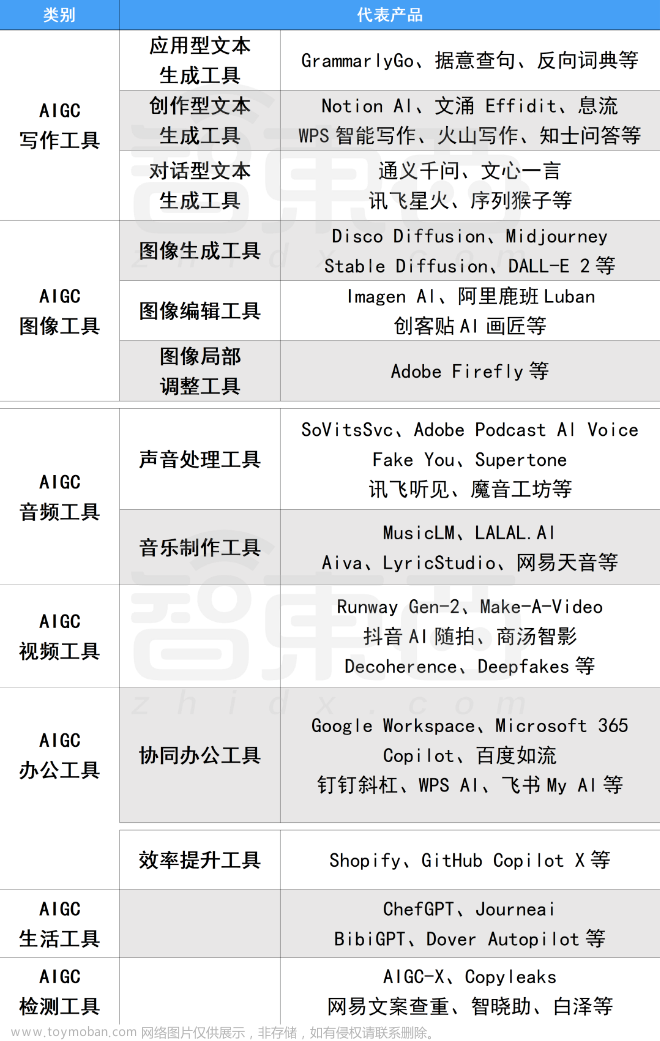
三、最新AIGC学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例文章来源:https://www.toymoban.com/news/detail-843895.html
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
文章来源地址https://www.toymoban.com/news/detail-843895.html
到了这里,关于炼丹!训练 stable diffusion 来生成LoRA定制模型的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!