flink 简介
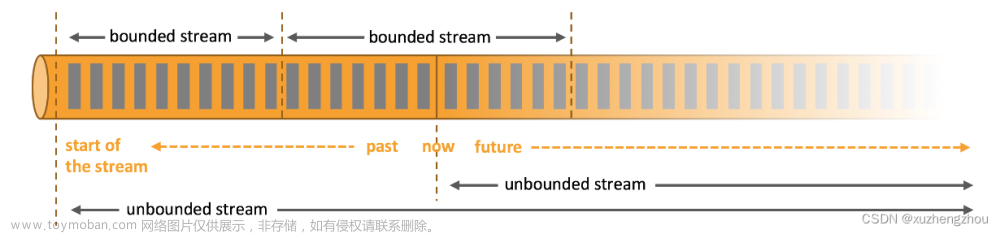
Apache Flink 是一个开源的流处理和批处理框架,用于大数据处理和分析。它旨在以实时和批处理模式高效处理大量数据。Flink 支持事件时间处理、精确一次语义、有状态计算等关键功能。
以下是与Apache Flink相关的一些主要特性和概念:
-
流处理和批处理:
- 流处理: Flink 支持流处理,允许您实时处理数据。
- 批处理: Flink 也支持批处理,以分布式和容错的方式处理大量数据。
-
事件时间处理:
- Flink 允许根据实际发生时间而不是到达时间来处理事件,对于准确和有意义的事件数据分析至关重要。
-
精确一次语义:
- Flink 支持精确一次处理语义,确保每个事件仅被处理一次,即使发生故障也不会丢失数据完整性。
-
有状态计算:
- Flink 支持有状态应用程序的开发,允许您跨事件和时间保留和更新状态。这对于需要在一段时间内记住和聚合信息的场景非常重要。
-
容错性:
- Flink 设计为容错的,提供从故障中恢复而不丢失数据完整性的机制。
-
丰富的 API 集:
- Flink 提供了 Java、Scala 和 Python 的 API,使其适用于各种开发人员。API 包括用于批处理的 DataSet API 和用于流处理的 DataStream API。
-
库和连接器:
- Flink 配备了多个库和连接器,用于常见用例,如 FlinkML 用于机器学习、Flink Gelly 用于图处理,以及与 Apache Kafka、Apache Hadoop 等的连接器。
-
社区和生态系统:
- Flink 拥有充满活力的开源社区,是 Apache Software Foundation 的一部分。它具有由社区开发的扩展和工具的不断增长的生态系统。
-
动态扩展:
- Flink 支持动态扩展,允许您在运行时调整操作符的并行实例数以适应变化的工作负载。
-
兼容性:
- Flink 可在各种集群管理器上运行,包括 Apache Mesos、Apache Hadoop YARN 和 Kubernetes。它还与其他大数据技术集成。
总体而言,Apache Flink 是构建实时和批处理数据处理应用程序的强大而灵活的框架,适用于大数据领域的各种用例。
1.Local本地模式
1.1 原理
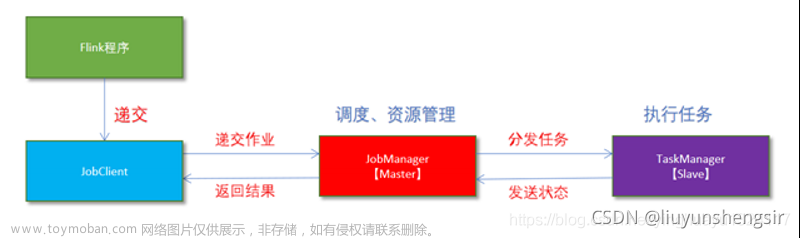
主节点JobManager(Master)和从节点TaskManager(Slave)在一台机器上模拟
-
Flink程序由JobClient进行提交
-
JobClient将任务提交给JobManager
-
JobManager只负责协调分配资源和分发任务,资源分配完成后将任务提交给相应的TaskManager
-
TaskManager启动一个线程开始执行任务,TaskManager会向JobManager报告状态的变更, 例如:开始执行、正在执行、执行完成
-
作业执行完成后,结果将发送回客户端(JobClient)文章来源:https://www.toymoban.com/news/detail-843899.html
1.2 安装
yum install java-1.8.0-openjdk.x86_64
yum install -y java-1.8.0-openjdk-devel
wget --no-check-certificate https://mirrors.tuna.tsinghua.edu.cn/apache/flink/flink-1.17.2/flink-1.17.2-bin-scala_2.12.tgz
mkdir -p /opt/flink
tar -zxvf flink-1.17.2-bin-scala_2.12.tgz -C /opt/flink
1.3 测试
/opt/flink/flink-1.17.2/bin/stop-cluster.sh
/opt/flink/flink-1.17.2/bin/start-cluster.sh
访问http://10.6.8.227:8081/
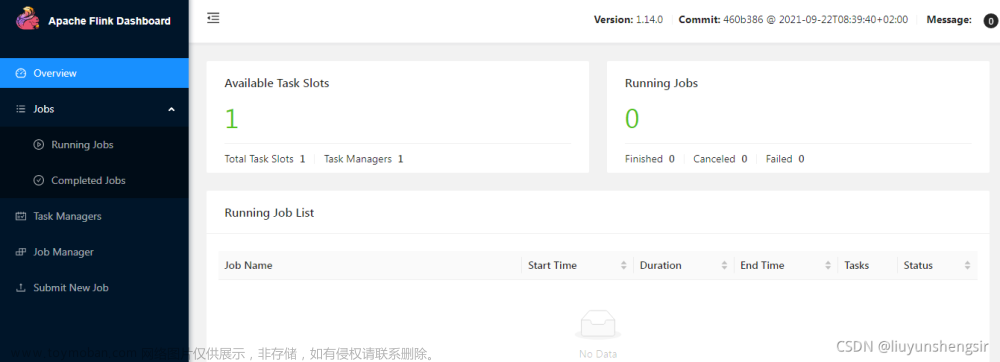 文章来源地址https://www.toymoban.com/news/detail-843899.html
文章来源地址https://www.toymoban.com/news/detail-843899.html
# 可以只执行上面这个,也可以加上下面的参数
/opt/flink/flink-1.17.2/bin/flink run /opt/flink/flink-1.17.2/examples/batch/WordCount.jar --input /root/words.txt --output /root/out
停止Flink:
/opt/flink/flink-1.17.2/bin/stop-cluster.sh
到了这里,关于flink-1.17.2的单节点部署的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!