涤生大数据实战:基于Flink+ODPS历史累计计算项目分析与优化(二)
1.优化方案
1.1 优化方案一:基于lambda方案的改进
问题分析
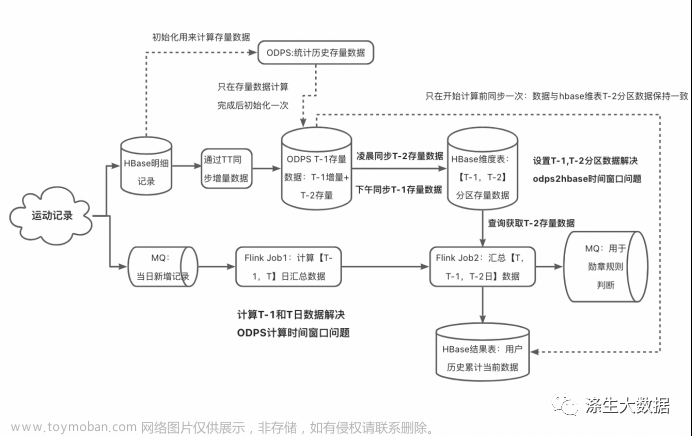
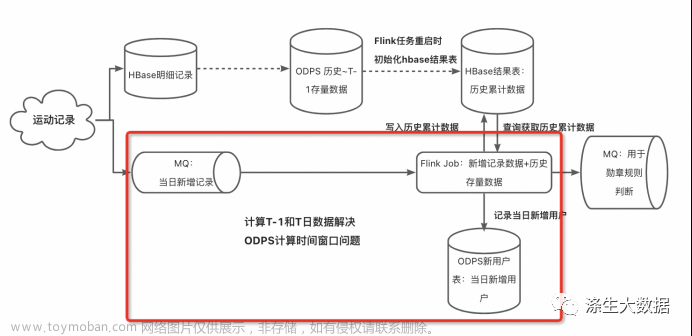
在 ODPS计算期间 或者 odps表同步到hbase表期间,发生了查询,会导致数据错误。出现问题的地方就是这两个时间窗口:ODPS计算期间 和 odps表同步到hbase表期间。那就针对性分析,各个击破。
解决方案
第一个时间窗口:“ODPS计算期间”
经过实际测试,ODPS的计算时间约为 30~40分钟,这个时间窗口还是很大的,哪怕是优化代码也减少不了多少,而且这个时间差肯定是存在的,无法消除。不能消除,那就给它充裕的时间计算。
目前我们计算总量的方案是:
实时总量= 离线计算 [历史~ T-1日] 存量 + 实时计算 [T日] 增量
如果改用:
实时总量= 离线计算 [历史~ T-2日] 存量 + 实时计算 [T日 +T-1日] 增量
将第T-1日的数据交给实时计算来算,这样离线部分就会多出一天的时间来计算 T-1日的数据,供第二天实时计算使用。
举例来说:
27号 :
ODPS凌晨时开始计算 26号的存量数据(此时25号存量数据已经计算完成了)。
Flink1计算26和27号的汇总数据;Flink2使用odps表的25号存量数据与Flink1的26、27号汇总数据,得到27号历史~此刻的汇总数据。
28号 :
ODPS凌晨时开始计算 27号的存量数据(此时26号存量数据经过一天肯定计算完成了)。
Flink1计算27和28号的汇总数据;Flink2使用odps表的26号存量数据与Flink1的26、27号汇总数据,得到27号历史~此刻的汇总数据。
······
经过上述方案,可以解决“ODPS计算时间”造成的时间差问题。
这里有个细节需要注意:
实时计算 [T日 +T-1日] 增量数据,T-1日数据既会参与T-1日的实时计算,也会参与T日的计算,会被用到两次(如上,27号的数据既要参与27日当日的实时计算,也要参与28号的实时计算)。可以写个UDTF将数据内容复制下,一条用于当日 ,一条用于明日,详情可见代码部分。
第二个时间窗口:“odps表同步数据到hbase表期间”
这个时间窗口在“ODPS计算期间”之后才出现。经过测试,odps表同步数据到hbase表的任务花费时间在 3~ 5分钟。
最直接的方案是不用hbase做维表里,直接使用 odps表作为维表,这样就可以方便的使用T-2分区数据了。但考虑到后期数据量的膨胀,大数据量情况下odps做维表不合适,这个方案被否定了。
我们要使用odps表的 T-2 分区数据, 在凌晨的时候还要无缝切换到新的T-2日分区,这里就涉及到两个分区数据的切换。那就在 hbase表里模拟出两个时间分区,分别存方odps的最近两个分区数据好了(hbase维表设计使用 “两列” 来模拟两个分区,也可以使用 “一列+两行” 的方案来解决)。
原方案的hbase维表结构(只存odps表的T-1分区数据):
| rowkey |
data |
day |
| 44556677775|28 |
3000 |
20231026 |
改进新方案的hbase维表结构(有两个相同结构的分区,分别存odps表的T-2 和 T-1分区数据):
| rowkey |
data_t2 |
day_t2 |
data_t1 |
day_t1 |
| 44556677775|28 |
3000 |
20231026 |
3003 |
20231027 |
data_t2 存放的是ODPS表的 T-2 分区数据,每日凌晨更新,主要支撑当日的维表查询。
data_t1 存放的是ODPS表的 T-1 分区数据,每日下午3:00更新,作为明天两个特殊窗口期发生维表查询时的替补(即“ODPS计算期间”、“ODPS表同步Hbase维表期间”两个容易发生问题的窗口期);
例如:
28号(hbase维表数据更新策略)
28号凌晨,将odps表的26号分区数据更新到hbase表的 t2 部分;
28号下午,将odps表的27号分区数据更新到hbase表的 t1 部分;
29号(hbase维表数据使用策略)
凌晨(同样会将odps表的27号分区数据更新到hbase表的 t2 部分),Flink需要使用27号的数据:
非发生问题的窗口期:发现hbase维表的t2中数据已更新完毕(已是27号数据),就正常使用t2数据;
处于发生问题的窗口期:发现hbase维表的t2中数据未更新(还是26号的数据),就使用t1的数据(27号数据)。
这里,主要使用hbase的t2部分数据,t1部分数据作为备用。什么时候使用t1的数据?在t2数据未更新时。
1.2 优化方案一实施
注意:
Flink任务的状态至少需要保存48小时(默认36小时),这里设为56小时;
第一次初始化hbase结果表时,需要使用odps的T-2日数据初始化;
当Flink任务重启时,只需回拉MQ到T-1日零点的消息位点即可;
代码1:基于lambda方案的改进” FlinkSQL代码
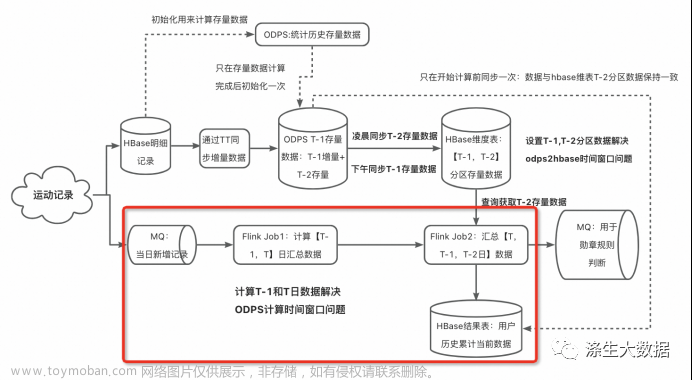
这里是上图红色部分实时链路的FlinkSQL代码:
--SQL
--********************************************************************--
--Comment: 运动身份证-跑步项目 实时统计用户历史汇总数据
-- 统计指标:总里程、总持续时间、总次数、总卡路里
-- 要统计两天内的汇总数据,需要保留最近两天的数据,最多共计48小时
-- 默认的 stat 保存时间为 36小时,需要调大保存时间,调大为保存54小时
-- #rocksdb的数据生命周期,单位毫秒
-- #state.backend.rocksdb.ttl.ms=194400000
-- copyRunRecord 自定义UDTF,接受输入一个 string/long型 微秒时间字段 born_timestamp ,
-- 输出两行:其余内容相同,时间字段不同(差一天):born_timestamp 和 born_timestamp+1day
--********************************************************************--
CREATE FUNCTION copyRunRecord AS 'com.alibaba.streamstudio.CopyRunRecord';
-- 跑步数据上传后发送mq消息给Flink,MQ消息是各 字符串,里面的内容自己用 REGEXP_EXTRACT 函数解析
-- MQ内容的各个字段顺序信息找发MQ消息的同学要
CREATE TABLE source_mq_runtopic (
contents varchar --boday解析出的字段
, __born_timestamp__ varchar header --用户发送MQ时间,毫秒
-- ,__store_timestamp__ varchar header --MQ存储时间
) WITH (
type = 'metaq',
topic = 'tao-tie-xxxxxxxx',
pullIntervalMs = '100',
consumerGroup = 'CID-tao-xxxxxxxx'
-- ,unitName = 'pre' --【Note】访问预发MQ,必须加该字段,其他环境默认即可
-- lengthCheck = 'PAD' --匹配格式
-- , fieldDelimiter = ',' --字段分割符
);-- 创建hbase维表
-- hbase在Flink创建维表的字段必须和hbase存的字段名是一样的,hbase是按创建的表字段名 去拉对应字段数据的
-- hbase的rowkey字段在hbase里是名称为row
CREATE TABLE dim_hbase_run_total_stat (
`row` varchar --hbase里rowekey对应的原名
,tmi2 varchar
,tdt2 varchar
,tf2 varchar
,tca2 varchar
,p2 varchar --T-2分区标志
,tmi1 varchar
,tdt1 varchar
,tf1 varchar
,tca1 varchar
,p1 varchar --T-1分区标志
,PRIMARY KEY (`row`) -- hbase 中的 rowkey 字段
,PERIOD FOR SYSTEM_TIME --定义了维表的标识。
) with (
type = 'alihbase',
-- 线上库
diamondKey = 'hbase.diamond.xxxxxxxx',
diamondGroup ='hbase-diamond-xxxxxxxx',
tableName = 'aliyitu_taotiexxxxxxxx',
columnFamily = 'f',
--partitionedJoin = 'true',
async='true' -- 开启异步策略
)
;--***************************************************
--【*注意*】 planner filter 节点在做优化时, push down的优化rule把filter push down到了agg之前,导致无法使用前一天数据
-- 问题详情描述:https://aliyuque.antfin.com/nn76ob/cxrx00/lv2q6a3m3fdxud27
--【解决方案】加print节点(让分段优化生效,不再下推该filter),print节点加参数ignoreWrite
CREATE TABLE print_view_recently_2d_stat
(
uid VARCHAR
,updateday VARCHAR
,total_mi BIGINT
,total_dt BIGINT
,total_times BIGINT
,total_ca DOUBLE
) with (
type='print',
ignoreWrite = 'true'
);
--***************************************************
--【*注意*】 planner filter 节点在做优化时, push down的优化rule把filter push down到了agg之前,导致无法使用前一天数据
-- 问题详情描述:https://aliyuque.antfin.com/nn76ob/cxrx00/lv2q6a3m3fdxud27
--【解决方案】加print节点(让分段优化生效,不再下推该filter),print节点加参数ignoreWrite
CREATE TABLE print_view_recently_2d_stat
(
uid VARCHAR
,updateday VARCHAR
,total_mi BIGINT
,total_dt BIGINT
,total_times BIGINT
,total_ca DOUBLE
) with (
type='print',
ignoreWrite = 'true'
)
;
--输出结果表1: hbase结果表
-- 加上 stringWriteMod = 'true' 参数后,写入hbase数据都是string格式,在后台可读
CREATE TABLE sink_hbase_result
( rowkey varchar
,tmi BIGINT
,tdt BIGINT
,tf BIGINT
,tca DOUBLE
,PRIMARY KEY(rowkey) --rowkey已构建好,直接使用即可
) with ( type='alihbase',
-- 线上库
diamondKey = 'hbase.diamond.xxxxxxxx',
diamondGroup ='hbase-diamond-xxxxxxxx',
columnFamily='f',
tableName='aliyitu_taotxxxxxxxx'
-- writePkValue = 'true',
-- stringWriteMod = 'true' --以string格式写入hbase
-- rowkeyDelimiter = '|'
)
;-- 输出的结果表2:mq结果表
CREATE TABLE sink_mq_result
( uid varchar
,tmi varchar
,tdt varchar
,tf varchar
,tca varchar
) with (
type='metaq',
topic='alisports_xxxxxxxx',
producerGroup='alisports_xxxxxxxx',
-- unitName = 'pre', --【Note】访问预发MQ,必须加该字段,其他环境默认即可
tag='28',
encoding='utf-8',
fieldDelimiter=',',
retryTimes='5',
sleepTimeMs='500',
-- isDynamicTag = 'true', --配置tag
-- dynamicTagColumn = 'channel',
keyColumns = 'uid', -- 配置key
writeKeysToBody = 'true'
)
;
-- step1.1:去重并解析MQ消息
create view view_mq_col_info as
SELECT
uid,
startTime,
endTime,
duration,
mileage,
calorie,
mq_born_timestamp
FROM
( -- topN 的 first row 方式去重
SELECT
uid,
CAST(startTime as BIGINT) as startTime,
CAST(endTime as BIGINT) as endTime,
CAST(duration as BIGINT) as duration,
CAST(mileage as BIGINT) as mileage,
CAST(calorie as DOUBLE) as calorie,
CAST(mq_born_timestamp as BIGINT) as mq_born_timestamp,
row_number () over (
PARTITION by uid,
channel,
startTime
order
by CAST(mq_born_timestamp as BIGINT)
) as rowNum
from
( --解析MQ消息内容
SELECT
REGEXP_EXTRACT(contents,'userId=(.*?)(,)',1) as uid
,REGEXP_EXTRACT(contents,'channel=(.*?)(,)',1) as channel
,REGEXP_EXTRACT(contents,'startTime=(.*?)(,)',1) as startTime
,REGEXP_EXTRACT(contents,'endTime=(.*?)(,)',1) as endTime
,REGEXP_EXTRACT(contents,'duration=(.*?)(,)',1) as duration
,REGEXP_EXTRACT(contents,'mileage=(.*?)(,)',1) as mileage
,REGEXP_EXTRACT(contents,'calorie=(.*?)(,)',1) as calorie
,REGEXP_EXTRACT(contents,'available=(.*?)(,)',1) as available
,__born_timestamp__ as mq_born_timestamp
from
source_mq_runtopic
where REGEXP_EXTRACT(contents,'available=(.*?)(,)',1) = '1' --只取有效数据
) a
) b
where rowNum=1
;
-- step1.2:一条MQ消息变成两条
-- 每条MQ消息会用于最近两日(当日和明日),需要使用UDTF将一条MQ消息变成两条,内容完全一样,但 mq_born_timestamp 不一样
-- uid, otherFeature, mq_born_timestamp
-- uid, otherFeature, mq_born_timestamp + 1day
create view view_mq_col_info_copy_record as
select uid
,startTime
,endTime
,duration
,mileage
,calorie
,cast(ts as BIGINT) as mq_born_timestamp
from view_mq_col_info ,
LATERAL table(copyRunRecord(mq_born_timestamp)) as T(ts); -- 自定义UDTF,将一行变多行,内容相同,时间相差1day-- step2:统计数据最近2天(T + T-1日)的汇总数据
-- way1:先明细,在汇总
create view view_recently_2d_stat as
select
uid,
updateday,
sum (mileage) as total_mi,
sum (duration) as total_dt,
cast( sum (1) as bigint ) as total_times,
sum (calorie) as total_ca
from (
select
uid,
DATE_FORMAT(TO_TIMESTAMP (mq_born_timestamp),'yyyy-MM-dd') as updateday, --上传日期
if (duration < 1, endTime - startTime, duration) as duration,
mileage,
if (calorie < 1.0, mileage * 0.07, calorie) as calorie --修复calorie
from
view_mq_col_info_copy_record
where
startTime < endTime
and (endTime - startTime) <= 86400 ----运动时间小于24小时
and duration <= 86400 ----运动时间小于24小时
and mileage >= 200 --跑步距离大于200米
and endTime < cast (mq_born_timestamp / 1000 as bigint) --排除异常2开头的et时间值
) a
GROUP
by uid,updateday
;
-- 打印【最近两日】聚合后的结果,解决“filter push down到了agg之前”导致无法使用前一天数据的问题
INSERT into print_view_recently_2d_stat
SELECT uid
,updateday
,total_mi
,total_dt
,total_times
,total_ca
from view_recently_2d_stat;
-- step3: 查询维表,获取T-2日的累计数据,与Flink实时计算的最近2日数据求和汇总
-- if((p2 is null & p1 = today-2) or (p2 is not null & p2 = today-3 ),d1 , if(d2 is null,0,d2))
-- (p2 is null & p1 = today-2) p2分区未来的及更新,p1分区已完成更新,p1分区的新用户,取p1数据d1
-- (p2 is not null & p2 = today-3) p2分区未来的及更新,p1分区已完成更新,p1分区的老用户,取p1数据d1
-- 其他情况取p2分区数据d2,如果d2数据为null,则取0
create view view_total_stat as
SELECT a.uid as uid
,a.total_mi + if( (b.p2 is null and DATE_FORMAT(b.p1,'yyyyMMdd','yyyy-MM-dd') = date_sub(CURRENT_TIMESTAMP,2)) or (b.p2 is not null and DATE_FORMAT(b.p2,'yyyyMMdd','yyyy-MM-dd') = date_sub(CURRENT_TIMESTAMP,3)) ,cast(b.tmi1 as bigint) ,if(b.tmi2 is null,cast(0 as bigint),cast(b.tmi2 as bigint))) as total_mi
,a.total_dt + if( (b.p2 is null and DATE_FORMAT(b.p1,'yyyyMMdd','yyyy-MM-dd') = date_sub(CURRENT_TIMESTAMP,2)) or (b.p2 is not null and DATE_FORMAT(b.p2,'yyyyMMdd','yyyy-MM-dd') = date_sub(CURRENT_TIMESTAMP,3)) ,cast(b.tdt1 as bigint),if(b.tdt2 is null,cast(0 as bigint),cast(b.tdt2 as bigint))) as total_dt
,a.total_times + if( (b.p2 is null and DATE_FORMAT(b.p1,'yyyyMMdd','yyyy-MM-dd') = date_sub(CURRENT_TIMESTAMP,2)) or (b.p2 is not null and DATE_FORMAT(b.p2,'yyyyMMdd','yyyy-MM-dd') = date_sub(CURRENT_TIMESTAMP,3)) ,cast(b.tf1 as bigint),if(b.tf2 is null,cast(0 as bigint),cast(b.tf2 as bigint))) as total_times
,a.total_ca + if( (b.p2 is null and DATE_FORMAT(b.p1,'yyyyMMdd','yyyy-MM-dd') = date_sub(CURRENT_TIMESTAMP,2)) or (b.p2 is not null and DATE_FORMAT(b.p2,'yyyyMMdd','yyyy-MM-dd') = date_sub(CURRENT_TIMESTAMP,3)) ,cast(b.tca1 as double),if(b.tca2 is null,cast(0.0 as double),cast(b.tca2 as double))) as total_ca
from (
SELECT
uid,
total_mi ,
total_dt ,
total_times ,
total_ca
from
view_recently_2d_stat
where updateday = DATE_FORMAT(CURRENT_TIMESTAMP,'yyyy-MM-dd') --只取当日计算的汇总数据(昨日+今日)
) a
left JOIN dim_hbase_run_total_stat FOR SYSTEM_TIME AS OF PROCTIME() b --不管维表有没有数据,都保留源表数据到hbase表里
on CONCAT_WS ('|',a.uid,'28') = b.`row`
;-- step4:将汇总结果写入hbase结果表
-- 输出线路1: 将汇总结果写入hbase结果表,
insert
into sink_hbase_result
SELECT
CONCAT_WS('|',uid,'28') as rowkey,
total_mi as tmi,
total_dt as tdt ,
total_times as tf ,
total_ca as tca
from
view_total_stat
;
-- 输出线路2: 将汇总结果写入MQ结果表,拼成json格式
INSERT into sink_mq_result
SELECT concat('{', CONCAT_WS(':','"uid"',concat('"',uid,'"'))) as uid
,CONCAT_WS(':','"totalMi"',cast(total_mi as varchar) ) as tmi
,CONCAT_WS(':','"totalDt"',cast(total_dt as varchar) ) as tdt
,CONCAT_WS(':','"totalTimes"',cast(total_times as varchar) ) as tf
,concat(CONCAT_WS(':','"totalCa"',cast(total_ca as varchar)),'}') as tca
from view_total_stat;1.3 优化方案二:完全基于流计算
问题分析
在 ODPS计算期间 或者 odps表同步到hbase表期间,发生了查询,会导致数据错误。出现问题的地方就是这两个时间窗口:ODPS计算期间 和 odps表同步到hbase表期间,这两个时间窗口都与离线链路有关,那如果不要离线链路了,完全使用实时链路来计算,就没有这样的问题了。
解决方案
经过前文分析,不能直接将所有的历史数据都放在Flink里做累计计算,那就提前加工好。
方案步骤
step1: 初始化:将用户 [历史 ~ 昨日] 累计数据计算好,放入到hbase结果表;
step2: 从 [今日零点] 开始启动Flink任务,新来一条跑步数据,Flink就去hbase结果表里查该用户原有累计数据,相加,实时更新hbase结果表;
该hbase结果表,既作为Flink写的结果表,又作为Flink查的维表;
老用户,历史累计与新来数据数值直接相加即可;
新用户,hbase结果表里没有该用户数据,则将历史累计值设为0,在相加,更新hbase结果表;同时将该新用户uid记录到一张odps增量分区表中(备用)。
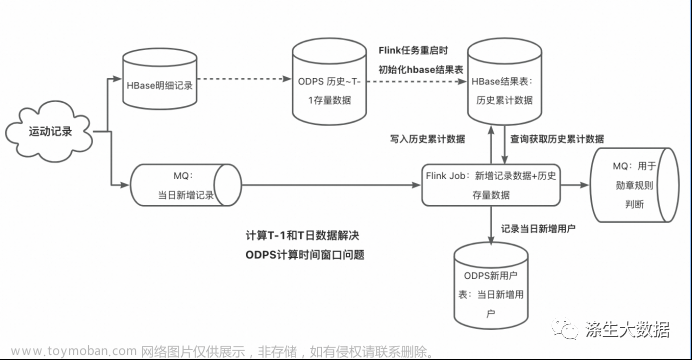
方案分析
优点:计算逻辑简单,链路简单
缺陷:使用结果表数据做累加再写入到结果表里,数据不具备幂等性;
eg:该用户的某条跑步记录如果重复上传多次(如Flink任务中断后,需要从当日凌晨重启,则当日0点到中断时刻的数据会再次重新参与计算),则会累加多次。
缺陷修复方案
正常情况下, 该方案不会出现幂等问题,只有当Flink任务停止后重启后(重启位点为当日0点),累加数据会出现幂等性的情况。那就针对这种特殊情况做处理。
【解决方案】
起一个离线任务,每日例行计算 [历史~昨日] 的累计数据,存在 T-1 分区里;
当 Flink 任务在第 T日 暂停后 需要重启:
先使用离线ODPS表的 T-1日 分区数据初始化hbase结果表一次;
非T日新增的老用户的数据在ODPS表里已存在,odps2hbase时会覆盖掉hbase表中现有数据,都更新为ODPS表数据,这样在hbase结果表里,T日之前的老用户累计数据都是正确的;
T日新增的新用户的数据在ODPS表里没有,odps2hbase时,这部分新用户的数据在hbase表中不受影响,数据保持不变(需要额外处理)
再从Flink任务实时记录的新用户ODPS表中取出第T日的新用户,用来将hbase结果表中这部分新用户的数值初始化为0(新用户);
然后重启Flink任务,数据回拉到 当日00:00,开始运行,就会补全新老用户的数据。
可以看到,该方案在任务重启时需要 离线和实时 同时操作,才能保证重启后的数据计算结果正确性。
代码2:完全基于流计算”FlinkSQL代码
这里仅仅是上图实时链路红色部分的FlinkSQL代码:
--SQL
--********************************************************************--
--Comment: 运动身份证-跑步项目 实时统计用户历史汇总数据
-- 统计指标:总里程、总持续时间、总次数、总卡路里
-- 方案2:每来一条数据去查该用户的历史存量数据,增加
-- 同时将每日新来的用户记录在odps表里
-- 当Flink任务挂掉,一方面使用odps离线汇总表更新前一日汇总数据 + 一方面根据新用户odps表找到当日新用户
-- 将hbase里的当日新用户统计数据置0,即可满足habse新用户的更新策略
--********************************************************************--
-- 跑步数据上传后发送mq消息给Flink
-- Flink里的source字段与MQ消息解析出的字段【顺序】一致,内容由MQ字段内容而定
-- MQ内容的各个字段顺序信息找发MQ消息的同学要
CREATE TABLE source_mq_runtopic (
uid varchar,
channel varchar,
startTime varchar,--开始时间,秒
endTime VARCHAR,
duration varchar,
mileage varchar,
calorie varchar,
tempo varchar --配速
, speed varchar --平均速度
, `path` varchar --跑步路径
, available varchar --数据有效性标签,1 为有效
, __born_timestamp__ varchar header --用户发送MQ时间,毫秒
-- ,__store_timestamp__ varchar header --MQ存储时间
) WITH (
type = 'metaq',
topic = 'tao-tie-xxxxxxxxx',
pullIntervalMs = '100',
consumerGroup = 'xxxxxxxx',
lengthCheck = 'PAD' --匹配格式
, fieldDelimiter = ',' --字段分割符
);
-- 创建hbase维表
-- hbase在Flink创建维表的字段必须和hbase存的字段名是一样的,hbase是按创建的表字段名 去拉对应字段数据的
-- hbase的rowkey字段在hbase里是名称为row
CREATE TABLE dim_hbase_run_total_stat (
`row` varchar --hbase里rowekey对应的原名
,tmi varchar
,tdt varchar
,tf varchar
,tca varchar
,PRIMARY KEY (`row`) -- hbase 中的 rowkey 字段
,PERIOD FOR SYSTEM_TIME --定义了维表的标识。
) with (
type = 'alihbase',
-- 线上库
diamondKey = 'hbase.diamond.xxxxxxxx',
diamondGroup ='hbase-diamond-xxxxxxxx',
tableName = '_shadow_xxxxxxxx', --planb的表
columnFamily = 'f',
--partitionedJoin = 'true',
async='true' -- 开启异步策略
)
;--输出结果表1: hbase结果表
-- 加上 stringWriteMod = 'true' 参数后,写入hbase数据都是string格式,在后台可读
CREATE TABLE sink_hbase_result
( rowkey varchar
,tmi BIGINT
,tdt BIGINT
,tf BIGINT
,tca DOUBLE
,PRIMARY KEY(rowkey) --rowkey已构建好,直接使用即可
) with ( type='alihbase',
-- 线上库
diamondKey = 'hbase.diamond.xxxxxxxx',
diamondGroup ='hbase-diamond-xxxxxxxx',
columnFamily='f',
tableName='_shadow_test_aliyitu_xxxxxxxx',
-- writePkValue = 'true',
stringWriteMod = 'true' --以string格式写入hbase
-- rowkeyDelimiter = '|'
)
;
-- 输出的结果表2:mq结果表
CREATE TABLE sink_mq_result
( uid varchar
,tmi varchar
,tdt varchar
,tf varchar
,tca varchar
) with (
type='metaq',
topic='tanggula-xxxxxxxx',
producerGroup='tanggula-xxxxxxxx',
tag='28',
encoding='utf-8',
fieldDelimiter=',',
retryTimes='5',
sleepTimeMs='500',
-- isDynamicTag = 'true', --配置tag
-- dynamicTagColumn = 'channel',
keyColumns = 'uid', -- 配置key
writeKeysToBody = 'true'
)
;
-- 输出结果表3:odps表,用来存储当日增用户
create table sink_odps_new_user_di(
rowkey VARCHAR
,total_mi BIGINT
,total_dt BIGINT
,total_times BIGINT
,total_ca DOUBLE
,statday VARCHAR
,ds VARCHAR
) with (
type = 'odps',
endPoint = 'http://service.odps.aliyun-inc.com/api',
project = 'alisportxxxxxxxx',
tableName = 'alisports_ydsjzx_rxxxxxxxx',
accessId = 'xxxxxxxx',
accessKey = 'xxxxxxxx',
`partition` = 'ds'--分区配置详情参考下文 with 参数介绍
);-- step1:解析并去重MQ消息
create view view_mq_col_info as
SELECT
split_index (uid, '=', 1) as uid,
split_index (channel, '=', 1) as channel,
cast (split_index (startTime, '=', 1) as BIGINT) as startTime,
cast (split_index (endTime, '=', 1) as bigint) as endTime,
cast (split_index (duration, '=', 1) as bigint) as duration,
cast (split_index (mileage, '=', 1) as bigint) as mileage,
cast (split_index (calorie, '=', 1) as DOUBLE) as calorie,
-- cast (split_index (available, '=', 1) as bigint) as available,
cast (__born_timestamp__ as bigint) as mq_born_timestamp
from (
--去重:去除重复发送的消息,取最先到达的消息
SELECT
uid,
channel,
startTime,
endTime,
duration,
mileage,
calorie,
available,
__born_timestamp__,
row_number () over (
PARTITION by uid,
channel,
startTime
order
by cast (__born_timestamp__ as bigint)
) as rowNum
from
source_mq_runtopic
WHERE
split_index (available, '=', 1) = '1' --只取有效数据
)
WHERE
rowNum = 1;-- step2:对新来的一条数据做过滤处理,处理成符合需求的格式
create view view_filter_data as
select
uid,
mileage as total_mi,
if (duration < 1, endTime - startTime, duration) as total_dt,
cast( 1 as bigint ) as total_times,
if (calorie < 1.0, mileage * 0.07, calorie) as total_ca --修复calorie
from
view_mq_col_info
where
DATE_FORMAT(TO_TIMESTAMP (mq_born_timestamp),'yyyy-MM-dd') = DATE_FORMAT(CURRENT_TIMESTAMP,'yyyy-MM-dd') --只取当日数据
and startTime < endTime
and (endTime - startTime) <= 86400 ----运动时间小于24小时
and duration <= 86400 ----运动时间小于24小时
and mileage > 200 --跑步距离大于200米
and endTime < cast (mq_born_timestamp / 1000 as bigint) --排除异常2开头的et时间值
;-- step3.1: 查询维表,判断该用户是否是当日新来的用户,如果是写入odps维表
INSERT INTO sink_odps_new_user_di
select rowkey
,cast(0 as BIGINT ) as total_mi
,cast(0 as BIGINT ) as total_dt
,cast(0 as BIGINT ) as total_times
,cast(0.0 as DOUBLE ) as total_ca
,DATE_FORMAT(CURRENT_TIMESTAMP,'yyyyMMdd') as statday
,DATE_FORMAT(CURRENT_TIMESTAMP,'yyyyMMdd') as ds --当日日期做odps表分区
from
(
SELECT CONCAT_WS ('|',a.uid,'28') as rowkey
,b.`row` as b_rowkey
from view_filter_data a
left JOIN dim_hbase_run_total_stat FOR SYSTEM_TIME AS OF PROCTIME() b --不管维表有没有数据,都保留源表uid到odps新用户表
on CONCAT_WS ('|',a.uid,'28') = b.`row`
)a
where b_rowkey is null --只保留当日新用户
;
-- step3.2: 查询维表,获取当前累计数据,与Flink新接收到的一条数据求和汇总
create view view_total_stat as
SELECT a.uid as uid
,a.total_mi + if(b.tmi is null,cast(0 as bigint),cast(b.tmi as bigint)) as total_mi
,a.total_dt + if(b.tdt is null,cast(0 as bigint),cast(b.tdt as bigint)) as total_dt
,a.total_times + if(b.tf is null,cast(0 as bigint),cast(b.tf as bigint)) as total_times
,a.total_ca + if(b.tca is null,cast(0.0 as double),cast(b.tca as double)) as total_ca
from view_filter_data a
left JOIN dim_hbase_run_total_stat FOR SYSTEM_TIME AS OF PROCTIME() b --不管维表有没有数据,都保留源表数据到hbase表里
on CONCAT_WS ('|',a.uid,'28') = b.`row`
;-- step4.1 输出线路1:将汇总结果写入hbase结果表
insert
into sink_hbase_result
SELECT
CONCAT_WS('|',uid,'28') as rowkey,
total_mi as tmi,
total_dt as tdt ,
total_times as tf ,
total_ca as tca
from
view_total_stat;
-- step4.2 输出线路2: 将汇总结果写入MQ结果表,拼成json格式
INSERT into sink_mq_result
SELECT concat('{', CONCAT_WS(':','"uid"',concat('"',uid,'"'))) as uid
,CONCAT_WS(':','"total_mi"',cast(total_mi as varchar) ) as tmi
,CONCAT_WS(':','"total_dt"',cast(total_dt as varchar) ) as tdt
,CONCAT_WS(':','"total_times"',cast(total_times as varchar) ) as tf
,concat(CONCAT_WS(':','"total_ca"',cast(total_ca as varchar)),'}') as tca
from view_total_stat;2.优化方案选择
基于lambda方案改进的方案,计算链路较长,但如果发生Flink任务重启的情况,可以直接回拉消息位点到 T-1 日的00:00时刻即可完成重启和数据修复;而完全基于流计算的优化方案,计算链路较短,但如果发生Flink任务重启的情况,需要离线和实时两条线一起修复数据:离线补一次T-1数据到hbase + 离线初始化hbase中当日新用户数据为0 + Flink重启回拉消息位点到T日00:00,共计三步。为了后期维护的方便,本次采用了基于lambda的改进方案。实际落地后运行状态较好。

3.扩展&&思考
本文所述的两种方案都属于“先计算结果,将结果存储起来,在供查询使用”,将计算结果存储在hbase中可轻松支持万级的qps。
如果某些业务的qps没那么高(预估在400以下),可以使用 “Flink数据同步+Clickhouse实时分析”来做,将历史~今的明细数据存放到Clickhouse中,利用Clickhouse(OLAP型数据库)强大的数据分析能力,直接从明细里统计出所需的数据指标,大致分为2步:
step1:将用户历史存量明细数据、实时增量明细数据 实时同步到Clickhouse中;文章来源:https://www.toymoban.com/news/detail-843922.html
step2: 基于Clickhouse做实时数据分析,对外提供数据服务,每次查询时在Clickhouse中实时计算历史~今的统计数据。文章来源地址https://www.toymoban.com/news/detail-843922.html
到了这里,关于涤生大数据实战:基于Flink+ODPS历史累计计算项目分析与优化(下)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!