01 Changelog相关优化规则
0101 运行upsert-kafka作业
登录sql-client,创建一个upsert-kafka的sql作业(注意,这里发送给kafka的消息必须带key,普通只有value的消息无法解析,这里的key即是主键的值)
CREATE TABLE pageviews_per_region (
user_region STRING,
pv STRING,
PRIMARY KEY (user_region) NOT ENFORCED -- 设置主键
) WITH (
'connector' = 'upsert-kafka',
'topic' = 'pageviews_per_region',
'properties.bootstrap.servers' = 'xxxxxx:9092',
'key.format' = 'csv',
'value.format' = 'csv'
);
select * from pageviews_per_region;
发送消息带key和消费消息显示key方式如下
kafka-console-producer.sh --broker-list xxxxxx:9092 --topic pageviews_per_region --property "parse.key=true" --property "key.separator=:"
key1:value1,value1
key2:value2,value2
kafka-console-consumer.sh --bootstrap-server xxxxxx:9092 --topic pageviews_per_region --from-beginning --property print.key=true
作业的DAG图如下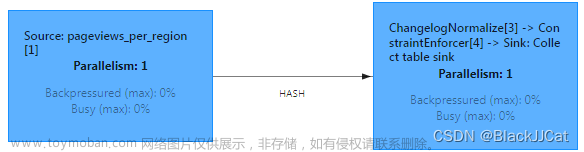
0102 StreamPhysicalChangelogNormalize
DAG图中有一个ChangelogNormalize,代码中搜索到对应的类是StreamPhysicalChangelogNormalize,这是一个对changelog数据做规范化的类,注释如下
/**
* Stream physical RelNode which normalizes a changelog stream which maybe an upsert stream or a
* changelog stream containing duplicate events. This node normalize such stream into a regular
* changelog stream that contains INSERT/UPDATE_BEFORE/UPDATE_AFTER/DELETE records without
* duplication.
*/
class StreamPhysicalChangelogNormalize(
功能就是转成对应的exec节点
override def translateToExecNode(): ExecNode[_] = {
val generateUpdateBefore = ChangelogPlanUtils.generateUpdateBefore(this)
new StreamExecChangelogNormalize(
unwrapTableConfig(this),
uniqueKeys,
generateUpdateBefore,
InputProperty.DEFAULT,
FlinkTypeFactory.toLogicalRowType(getRowType),
getRelDetailedDescription)
}
0103 StreamPhysicalTableSourceScanRule
StreamPhysicalChangelogNormalize是在优化规则StreamPhysicalTableSourceScanRule当中创建的,如下流式的FlinkLogicalTableSourceScan会应用该规则
class StreamPhysicalTableSourceScanRule
extends ConverterRule(
classOf[FlinkLogicalTableSourceScan],
FlinkConventions.LOGICAL,
FlinkConventions.STREAM_PHYSICAL,
"StreamPhysicalTableSourceScanRule") {
创建StreamPhysicalChangelogNormalize,也就是转为changelog的条件如下
if (
isUpsertSource(resolvedSchema, table.tableSource) ||
isSourceChangeEventsDuplicate(resolvedSchema, table.tableSource, config)
) {
isUpsertSource判断是否为upsert流,判断逻辑如下
public static boolean isUpsertSource(
ResolvedSchema resolvedSchema, DynamicTableSource tableSource) {
if (!(tableSource instanceof ScanTableSource)) {
return false;
}
ChangelogMode mode = ((ScanTableSource) tableSource).getChangelogMode();
boolean isUpsertMode =
mode.contains(RowKind.UPDATE_AFTER) && !mode.contains(RowKind.UPDATE_BEFORE);
boolean hasPrimaryKey = resolvedSchema.getPrimaryKey().isPresent();
return isUpsertMode && hasPrimaryKey;
}
其中ChangelogMode在各自数据源实现类的getChangelogMode接口中定义,如JDBC只支持insert
@Override
public ChangelogMode getChangelogMode() {
return ChangelogMode.insertOnly();
}
isSourceChangeEventsDuplicate判断不是upsert的更改流,判断逻辑如下
public static boolean isSourceChangeEventsDuplicate(
ResolvedSchema resolvedSchema,
DynamicTableSource tableSource,
TableConfig tableConfig) {
if (!(tableSource instanceof ScanTableSource)) {
return false;
}
ChangelogMode mode = ((ScanTableSource) tableSource).getChangelogMode();
boolean isCDCSource =
!mode.containsOnly(RowKind.INSERT) && !isUpsertSource(resolvedSchema, tableSource);
boolean changeEventsDuplicate =
tableConfig.get(ExecutionConfigOptions.TABLE_EXEC_SOURCE_CDC_EVENTS_DUPLICATE);
boolean hasPrimaryKey = resolvedSchema.getPrimaryKey().isPresent();
return isCDCSource && changeEventsDuplicate && hasPrimaryKey;
}
综合来说要走StreamPhysicalChangelogNormalize这一条调用链,就不能是insertOnly的数据源,但目前大部分Flink实现的数据源包括Iceberg都是insertOnly的
0104 更新模式
Flink相关的更新模式类有如下几个:RowKind、ChangelogMode、UpdateKind
- RowKind
RowKind是定义更新流每条数据的类型,其中对于更新有;两条数据,一条删除旧数据,一条插入新数据
/** Insertion operation. */
INSERT("+I", (byte) 0),
/**
* Update operation with the previous content of the updated row.
*
* <p>This kind SHOULD occur together with {@link #UPDATE_AFTER} for modelling an update that
* needs to retract the previous row first. It is useful in cases of a non-idempotent update,
* i.e., an update of a row that is not uniquely identifiable by a key.
*/
UPDATE_BEFORE("-U", (byte) 1),
/**
* Update operation with new content of the updated row.
*
* <p>This kind CAN occur together with {@link #UPDATE_BEFORE} for modelling an update that
* needs to retract the previous row first. OR it describes an idempotent update, i.e., an
* update of a row that is uniquely identifiable by a key.
*/
UPDATE_AFTER("+U", (byte) 2),
/** Deletion operation. */
DELETE("-D", (byte) 3);
- ChangelogMode
ChangelogMode定义数据源的更新模式,主要三种,就是包含不同的RowKind的类型
private static final ChangelogMode INSERT_ONLY =
ChangelogMode.newBuilder().addContainedKind(RowKind.INSERT).build();
private static final ChangelogMode UPSERT =
ChangelogMode.newBuilder()
.addContainedKind(RowKind.INSERT)
.addContainedKind(RowKind.UPDATE_AFTER)
.addContainedKind(RowKind.DELETE)
.build();
private static final ChangelogMode ALL =
ChangelogMode.newBuilder()
.addContainedKind(RowKind.INSERT)
.addContainedKind(RowKind.UPDATE_BEFORE)
.addContainedKind(RowKind.UPDATE_AFTER)
.addContainedKind(RowKind.DELETE)
.build();
- UpdateKind
UpdateKind是针对update这种更新类型细分
/** NONE doesn't represent any kind of update operation. */
NONE,
/**
* This kind indicates that operators should emit update changes just as a row of {@code
* RowKind#UPDATE_AFTER}.
*/
ONLY_UPDATE_AFTER,
/**
* This kind indicates that operators should emit update changes in the way that a row of {@code
* RowKind#UPDATE_BEFORE} and a row of {@code RowKind#UPDATE_AFTER} together.
*/
BEFORE_AND_AFTER
02 StreamExecChangelogNormalize
StreamExecChangelogNormalize的处理流程中根据是否启用table.exec.mini-batch.enabled分为微批处理和单数据的流处理
微批处理使用ProcTimeMiniBatchDeduplicateKeepLastRowFunction,流式使用ProcTimeDeduplicateKeepLastRowFunction,两者的核心差别就是微批会缓存数据使用一个for循环处理
这两个函数除了StreamPhysicalChangelogNormalize这一条链路外,还有StreamExecDeduplicate这一条链路,对应StreamPhysicalRankRule,是一个排序的东西
for (Map.Entry<RowData, RowData> entry : buffer.entrySet()) {
RowData currentKey = entry.getKey();
RowData currentRow = entry.getValue();
ctx.setCurrentKey(currentKey);
if (inputInsertOnly) {
processLastRowOnProcTime(
currentRow,
generateUpdateBefore,
generateInsert,
state,
out,
isStateTtlEnabled,
equaliser);
} else {
processLastRowOnChangelog(
currentRow, generateUpdateBefore, state, out, isStateTtlEnabled, equaliser);
}
}
- processLastRowOnProcTime
对数据按照时间语义进行去重,将当前数据作为最新,这个函数只针对insert only的数据
static void checkInsertOnly(RowData currentRow) {
Preconditions.checkArgument(currentRow.getRowKind() == RowKind.INSERT);
}
整套处理逻辑就是对数据根据场景修改数据的RowKind类型
} else {
if (generateUpdateBefore) {
preRow.setRowKind(RowKind.UPDATE_BEFORE);
out.collect(preRow);
}
currentRow.setRowKind(RowKind.UPDATE_AFTER);
out.collect(currentRow);
}
- processLastRowOnChangelog
这个函数就是按Key去重,本质上也是针对数据修改RowKind
核心的一块功能就是更新的时候要将前一个数据修改为UPDATE_BEFORE
} else {
if (generateUpdateBefore) {
preRow.setRowKind(RowKind.UPDATE_BEFORE);
out.collect(preRow);
}
currentRow.setRowKind(RowKind.UPDATE_AFTER);
out.collect(currentRow);
}
函数整体借用的是Flink的state功能,从状态中获取前面的数据,所以对状态缓存由要求;另外针对非删除型的数据,如果TTL没有开的话,就不会更新前面的数据
if (!isStateTtlEnabled && equaliser.equals(preRow, currentRow)) {
// currentRow is the same as preRow and state cleaning is not enabled.
// We do not emit retraction and update message.
// If state cleaning is enabled, we have to emit messages to prevent too early
// state eviction of downstream operators.
return;
}
03 初始RowKind来源
前面的流程里,在进行changelog转换的时候,数据是已经存在一个RowKind的值了,这一章追踪初始RowKind的来源
基于Flink-27的设计,Kafka数据源处理任务有一个KafkaRecordEmitter,emitRecord当中做数据的反序列化
deserializationSchema.deserialize(consumerRecord, sourceOutputWrapper);
最终走到DeserializationSchema.deserialize完成最终的反序列化
default void deserialize(byte[] message, Collector<T> out) throws IOException {
T deserialize = deserialize(message);
if (deserialize != null) {
out.collect(deserialize);
}
}
这里message是一个二进制数组,实际是Kafka的数据类型ConsumerRecord。根据SQL当中的配置,value反序列化使用的是csv,所以走到CsvRowDataDeserializationSchema当中处理
final JsonNode root = objectReader.readValue(message);
return (RowData) runtimeConverter.convert(root);
这里读出来的root是数据的key,convert的转化的实现类是CsvToRowDataConverters,其createRowConverter接口当中创建了转化函数,函数中将数据转化为了Flink的数据类型GenericRowData
GenericRowData row = new GenericRowData(arity);
GenericRowData的定义当中,有初始化RowKind,就是insert
public GenericRowData(int arity) {
this.fields = new Object[arity];
this.kind = RowKind.INSERT; // INSERT as default
}
04 补充
0401 delete
按照官方说法,发送一个空消息就会产生delete
Also, null values are interpreted in a special way: a record with a null value represents a “DELETE”.
使用kafka producer控制台发送空消息无法解析
[ERROR] Could not execute SQL statement. Reason:
org.apache.flink.shaded.jackson2.com.fasterxml.jackson.databind.exc.MismatchedInputException: No content to map due to end-of-input
at [Source: UNKNOWN; byte offset: #UNKNOWN]
官方说法是kafka的控制台版本对 null的支持问题,需要3.2以上版本
https://issues.apache.org/jira/browse/FLINK-27663?jql=project%20%3D%20FLINK%20AND%20text%20~%20%22upsert-kafka%22
空值处理逻辑在DynamicKafkaDeserializationSchema.deserialize当中
这里根据输入的数据是否空值进行分支处理;非空值时走的就是前三章的逻辑,也就是这里是前三章逻辑的入口文章来源:https://www.toymoban.com/news/detail-844078.html
if (record.value() == null && upsertMode) {
// collect tombstone messages in upsert mode by hand
outputCollector.collect(null);
} else {
valueDeserialization.deserialize(record.value(), outputCollector);
}
空值时走到OutputProjectionCollector.emitRow,这里会设置初始类型为DELETE文章来源地址https://www.toymoban.com/news/detail-844078.html
if (physicalValueRow == null) {
if (upsertMode) {
rowKind = RowKind.DELETE;
} else {
throw new DeserializationException(
"Invalid null value received in non-upsert mode. Could not to set row kind for output record.");
}
} else {
rowKind = physicalValueRow.getRowKind();
}
到了这里,关于FlinkSQL ChangeLog的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!