一、.修改主机名
在Centos7中直接使用root用户执行hostnamectl命令修改,重启(reboot)后永久生效。
hostnamectl set-hostname 新主机名
要求:三台主机的名字分别为:master slave1 slave2
二、关闭防火墙
1.查看CentOS 7防火墙状态
systemctl status firewalld.service
2.关闭运行的防火墙
systemctl stop firewalld.service
关闭后,可查看防火墙状态,当显示disavtive(dead)的字样,说明CentOS 7防火墙已经关闭。
但要注意的是,上面的命令只是临时关闭了CentOS 7防火墙,当重启操作系统后,防火墙服务还是会再次启动。如果想要永久关闭防火墙则还需要禁用防火墙服务。
3.禁用防火墙服务
systemctl disable firewalld.service
三、配置静态ip
使用root用户修改当前启用的网卡配置文件,所在路径为 /etc/sysconfig/network-scripts ,CentOS 6系统默认为ifcfg-eth0,CentOS 7系统默认为ifcfg-ens32 ,使用vi编辑器编辑ifcfg-ens32文件,所用命令如下:
vi /etc/sysconfig/network-scripts/ifcfg-ens32
三个节点上的这个文件都需要修改,修改的内容基本一致,如下是需要修改和添加的
#原值为dhcp,修改为static
BOOTPROT="satic"
# 添加IPADDR,对应的值要与原ip在同一网段
IPADDR=xxx.xxx.xxx.xxx
# 添加NETMASK,指定子网掩码,默认为255.255.255.0
NETMASK=255.255.255.0
# 添加GATEWAY,要与虚拟机网卡的设置一致,默认仅主机模式为1,NAT模式为2
GATEWAY=xxx.xxx.xxx.1/2
# 如果需要连入外网,则可以添加DNS1和DNS2配置,通常会将DNS1指定为网关地址
DNS1=网关地址
DNS2=8.8.8.8
注意:配置完成后保存退出,使用systemctl restart network命令重启网卡服务。(如果使用service network restart命令,则需要编辑/etc/resolv.conf文件,添加对应的如下内容:nameserver 8.8.8.8 )
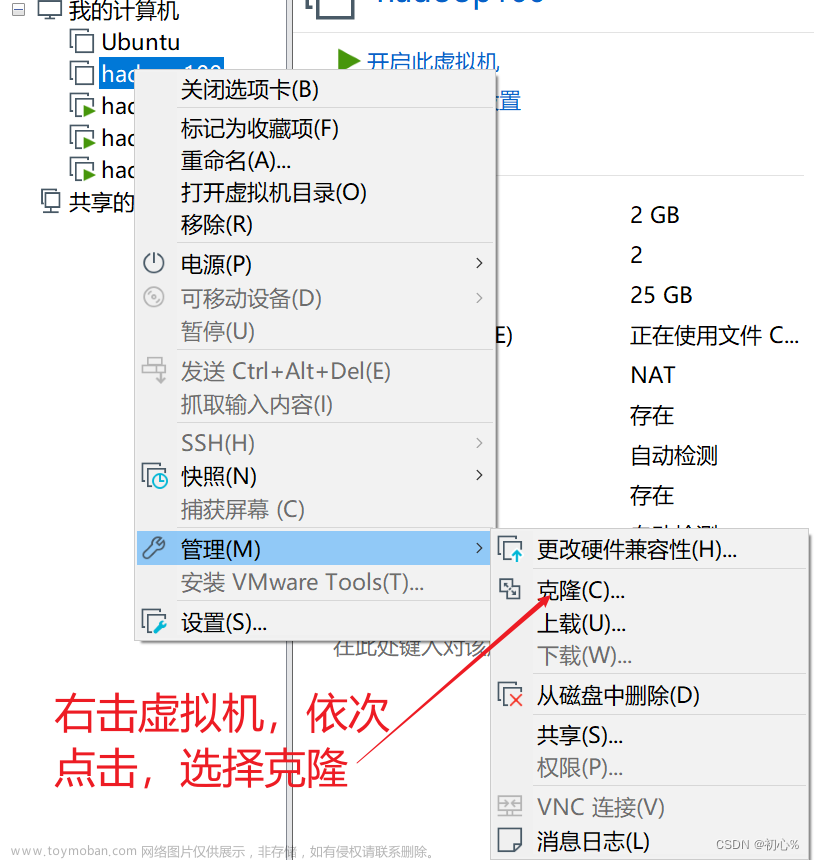
四、克隆虚拟机
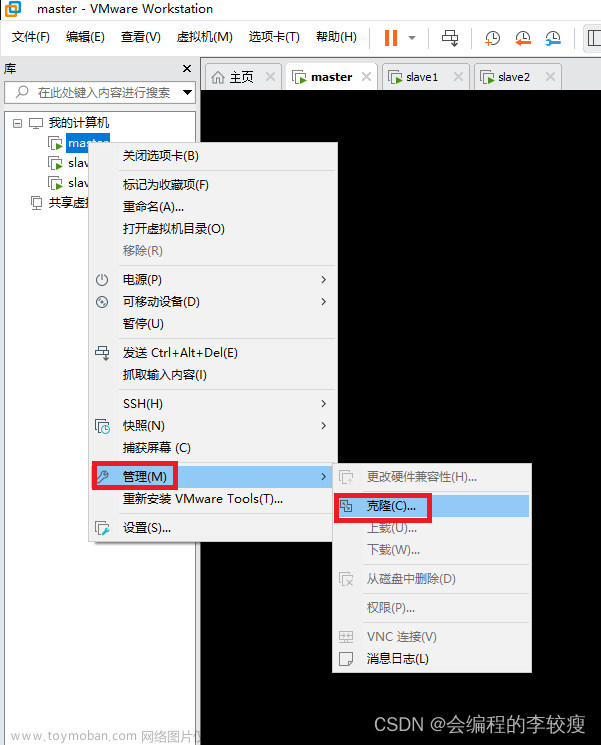



克隆完成后需要重新设置ip地址和mac地址
mac地址的设置如下:



启动虚拟机,输入
uuidgen

vi /etc/sysconfig/network-scripts/ifcfg-ens32

然后重启网络
systemctl restart network
五、ip地址和主机名的映射
在完全分布式部署的Hadoop平台上,为了方便各节点的交互,也为了尽量减少配置的修改,通常在配置文件中都会使用主机名来访问节点,这就需要正确的建立主机名与ip的映射。我们目前已经有了三台配置好网络的机器。现在我们有这样三台机器(master为主节点):
| 主机名称 | IP地址 |
|---|---|
| master | 192.168.233.131 |
| slave1 | 192.168.233.130 |
| slave2 | 192.168.233.128 |
1.需要使用root用户修改 /etc/hosts 文件,删除原来的内容,在结尾直接追加内容(每台机器):
192.168.233.131 master
192.168.233.130 slave1
192.168.233.128 slave2
2.配置完成后可以使用ping命令一一测试,看看是够能够正确解析出ip地址,得到目标机器的回应(可以每台机器都测试一下:使用Ctrl + C结束)。



3.在slave1和slave2 上也修改hosts文件,追加内容和步骤1的内容相同,然后重复步骤2
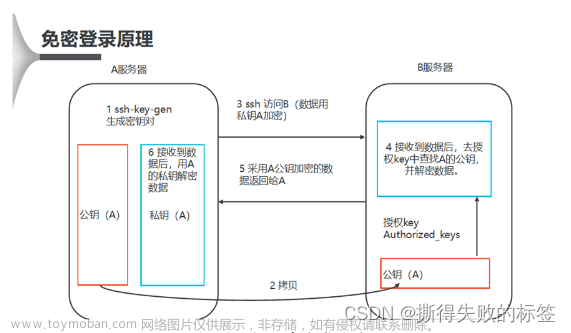
六、免密登录设置
1.生成公钥密钥对
在3个节点上分别都执行如下命令:
ssh-keygen
连续按Enter键确认。
在root目录下输入:ll-a 可以查看当前目录下的所有文件(包含隐藏文件)。
然后进入.ssh隐藏目录,输入ls 命令,如图所示:

在图中能够看到包含两个文件分别是私钥和公钥,其中id_rsa为生成的私钥,id_rsa.pub为生成的公钥。
2.将子节点的公钥拷贝到主节点并添加进authorized_keys
在master节点上执行如下两行命令:
ssh-copy-id master
ssh-copy-id slave1
ssh-copy-id slave2
执行时,到了红色框区域,需要输入yes

3.测试是否成功
为了测试免密设置是否成功,可执行如下命令:
ssh master
ssh slave1
ssh slave2
结果如图所示:


七、配置jdk环境
为了规范后续Hadoop集群相关软件和数据的安装配置,这里在虚拟机的根目录下建一些文件夹作为约定,具体如下:
| 文件夹名 | 作用 |
|---|---|
| /opt/module | 存放软件 |
| /opt/software | 存放安装包压缩包 |
具体需要执行下面3条命令:
mkdir -p /opt/module
mkdir -p /opt/software
进入/opt目录下,执行ls命令,如图所示即为成功。
1.下载jdk安装包和hadoop3.1.4
下载JDK地址 : https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
2.将本地的jdk安装包上传到/opt/software系统中
3.进入/opt/software目录下,解压jdk安装包到/opt/module
执行如下命令:
cd /opt/software
tar -zxvf jdk-8u161-linux-x64.tar.gz -C /opt/module
tar hadoop-3.1.4.tar.gz -C /opt/module/
解压后在/opt/module目录下使用ll命令查看:!

4.配置环境变量
使用vi编辑器编辑etc文件夹下的profile文件,键盘按下大写字母G,即可将光标移动到文章的末尾。
vi /etc/profile.d/my_env.sh
将如下内容添加到末尾
#jdk环境变量
export JAVA_HOME=/opt/module/jdk1.8.0_161
export PATH=$JAVA_HOME/bin:$PATH
#hadoop环境变量
export HADOOP_HOME=/opt/module/hadoop-3.1.4
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
刷新环境变量
source /etc/profile
使用命令测试jdk环境变量的配置
java -version

使用命令测试hadoop环境变量的配置
hadoop version

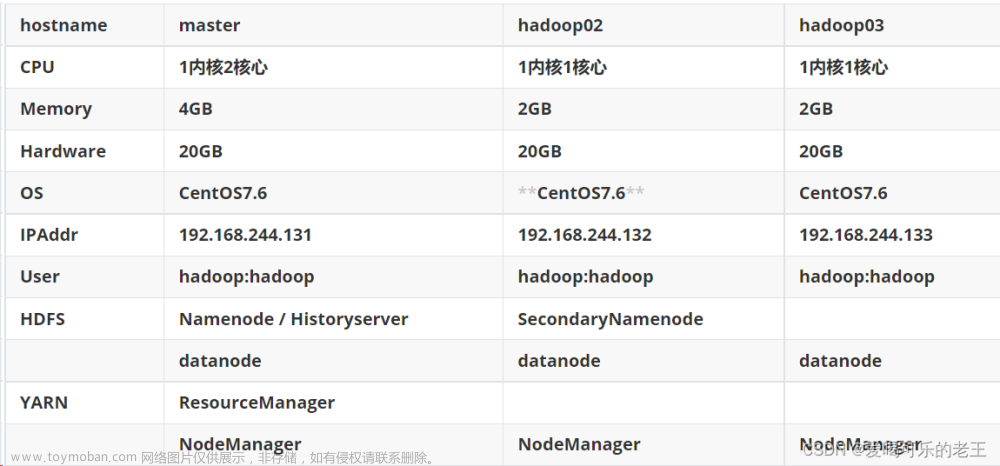
八、Hadoop集群配置
| master | slave1 | s;ave2 |
|---|---|---|
| namenode | resourcemanager | secondarynamenode |
| datanode | datanode | datanode |
| nodemanager | nodemanager | nodemanager |
1.修改core-site.xml文件
<!-- 指定 NameNode 的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:8020</value>
</property>
<!-- 指定 hadoop 数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.4/data</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
2.修改hdfs-site.xml文件
<!-- nn web 端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>master:9870</value>
</property>
<!-- 2nn web 端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave2:9868</value>
</property>
3.修改mapred-site.xml文件
<!-- 指定 MapReduce 程序运行在 Yarn 上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<!-- 历史服务器 web 端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
4.修改yarn-site.xml文件
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定 ResourceManager 的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>slave1</value>
</property>
在任意目录下输入:hadoop classpath,复制返回的信息,并添加到如下value标签中
<property>
<name>yarn.application.classpath</name>
<value>输入刚才返回的Hadoop classpath路径</value>
</property>
5 修改workers文件
master
slave1
slave2
6.修改环境变量相关设置
vi /etc/profile.d/my_env.sh
添加hadoop为root用户,否则启动的HDFS的时候可能会报错.
添加如下内容:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_JOURNALNODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
九、格式化文件系统
初次启动HDFS集群时,必须对主节点进行格式化处理文章来源:https://www.toymoban.com/news/detail-854421.html
格式化文件系统指令如下:文章来源地址https://www.toymoban.com/news/detail-854421.html
hdfs namenode -format
十、启动和关闭集群
十一、通过UI界面查看Hadoop集群运行状态
到了这里,关于Hadoop3.1.4完全分布式集群搭建的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!