本篇文章是使用bs4中的BeautifulSoup和requests解析网页和获取数据👑🌟
🌟前言
为了更深入的学习爬虫,今天来了解下bs4的使用和实践,当然解析网页不止只有bs4的BeautifulSoup可以做到,还有xpath语法和正则表达式。本期是初步的了解BeautifulSoup模块的使用,欢迎初学者学习本期内容。
一、🍉bs4中的BeautifulSoup
BeautifulSoup库是Python编程语言中的一款第三方库,主要用于解析HTML和XML文档。这个库能够将复杂的HTML或XML数据转换为树形结构(即DOM树),让开发者能够以更简单的方式来遍历、搜索和操作这些结构化的数据。
bs4的四种解析方式:
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| python标准库 | soup = BeautifulSoup(htmlt, ‘html.parser’) | python内置标准库;执行速度适中 | python2.x或者python3.2x前的版本中文文档容错能力差 |
| lxml HTML解析器 | soup = BeautifulSoup(html, ‘lxml’) | 速度快;文档容错能力强 | 需要安装c语言库 |
| lxml XML解析器 | soup = BeautifulSoup(html, ‘xml’) | 速度快;唯一支持XML的解析器 | 需要安装c语言库 |
| html5lib | soup = BeautifulSoup(html, ‘html5lib’) | 最好的容错性;以浏览器的方式解析文档;生成HTML5格式的文档;不依赖外部扩展库 | 速度慢 |
二、🍉bs4的语法
- 获取全部的单个标签:
soup.find_all('标签')
- 获取拥有指定属性的标签:
soup.find_all('标签',属性的键值对)
soup.find_all('标签',attrs={键值对1,键值对2})
注意:attrs是存储的是字典,里面可以包含html的多个属性
- 获取多个指定属性的标签:
soup.find_all('标签',属性的键值对1,属性的键值对2)
如果在获取时,出现python关键字与属性冲突时,在获取的时候添加一个下划线 ' _ ' ,例如:
soup.find_all('div',class_='position')
- 获取标签属性值:
先锁定标签
alist=soup.find_all('a')
- 方法1:
通过下标方式提取
for a in alist:
href=a['href']
print(href)
- 方法2:
利用attrs参数提取
for a in alist:
href=a.attrs['href']
print(href)
-
获取标签内的文本信息:
使用string方法
# 获取html的所有div标签,从第二个开始
divs=soup.find_all('div')[1:]
# 利用循环输出每个标签
for div in divs:
# 只提取标签下的字符串
a=div.find_all('a')[0].string
# 提取整个div下的字符串
divs=soup.find_all('div')[1:]
for div in divs:
infos=list(div.stripped_strings) # stripped_strings方法是删除列表中的制表符,例如: "\n,\t"等
三、🍉内容实践
爬取的网页链接:https://www.autohome.com.cn/news/1/#liststart
1. 确定想要爬取的内容
在此以爬取:前五页的(标题、更新时间和页面部分显示的详细内容)
2. 分析网页
首页内容,这里要注意的是这个网页链接,可以从第一页到第三页的链接对比
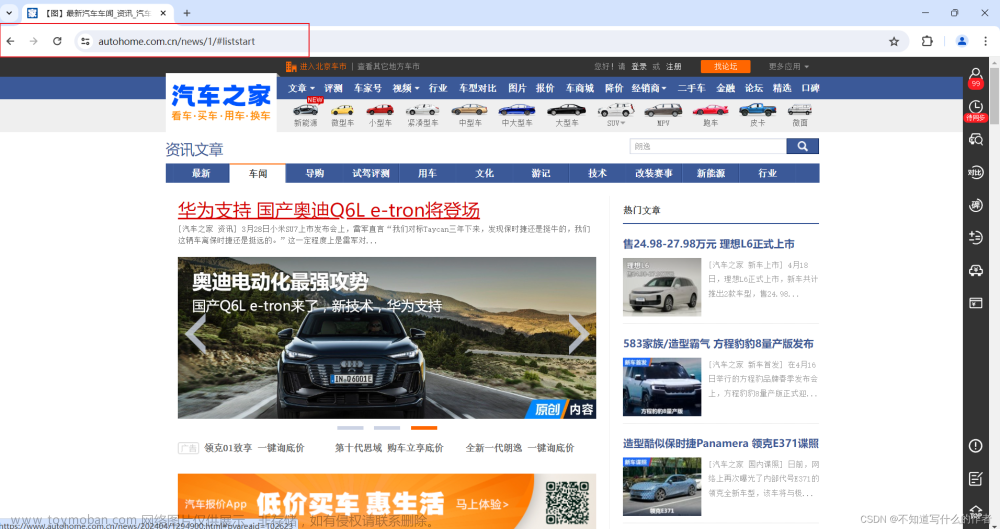
仔细查看后,只有这个/news/后的数字发生了变化,所以我们只要做一个循环数字的方式更改内容就可以
https://www.autohome.com.cn/news/1/#liststart
https://www.autohome.com.cn/news/2/#liststart
https://www.autohome.com.cn/news/3/#liststart
内容实施:
urls = [] # 定义一个列表存放每页的链接
for i in range(1, 6):
url = f"https://www.autohome.com.cn/news/{i}/#liststart"
urls.append(url)
# print(urls)
3. 获取数据分析
- 观察html标签内容
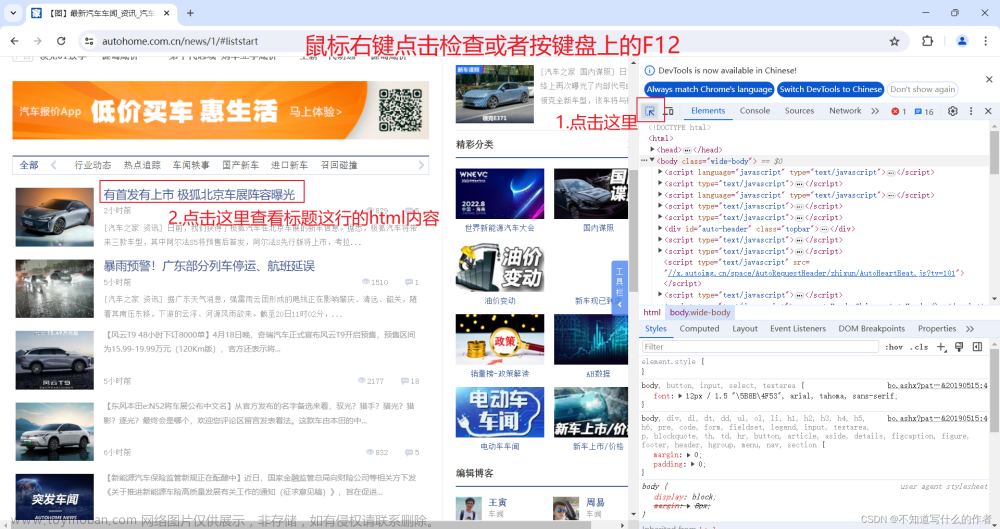
- 获取网页的标签信息,发现这些标签都在div标签中的ul标签里面
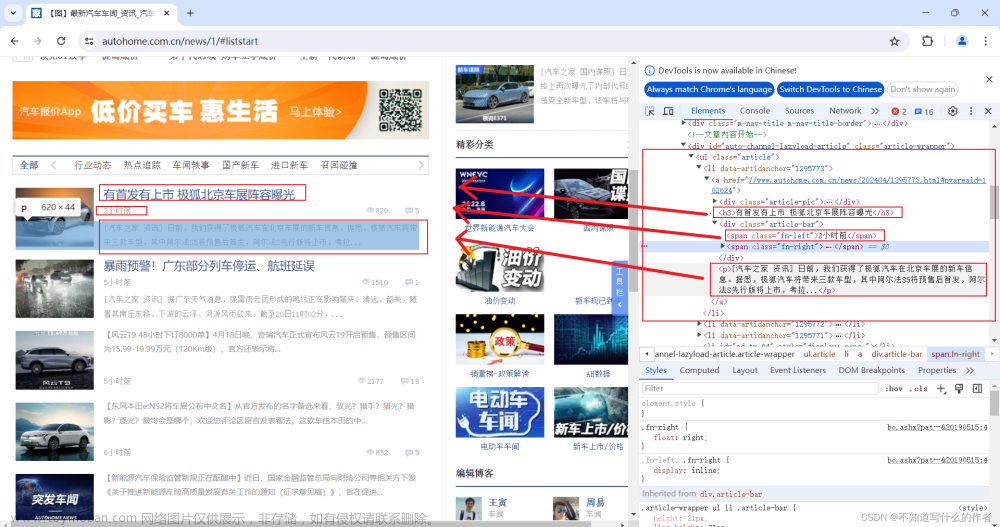
- 对比标签,发现每个内容都是使用的相同标签
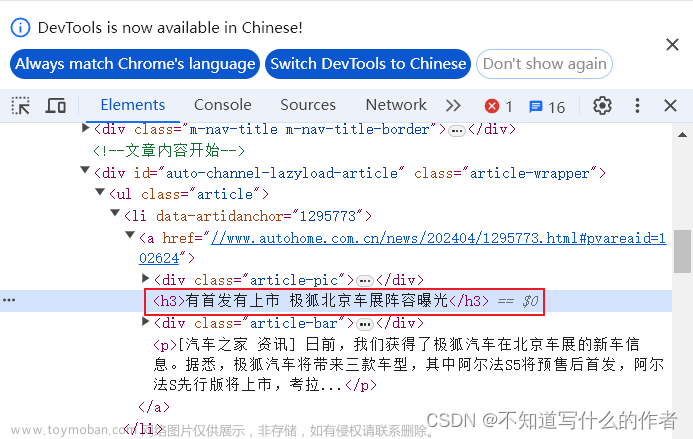
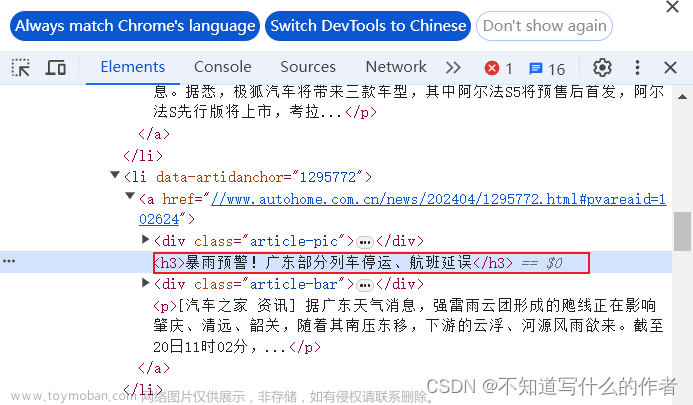
- 代码
# 导包
from bs4 import BeautifulSoup
import requests
# 设置请求头
url = 'https://www.autohome.com.cn/news/'
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0"
}
# 利用循环读取前5分页
urls = [] # 定义一个列表存放每页的链接
for i in range(1, 6):
url = f"https://www.autohome.com.cn/news/{i}/#liststart"
urls.append(url)
# print(urls)
# 定义两个列表 news存放字典数据
news = []
for url in urls:
# 利用try……except语句获取每页,如果某页读取不了,则继续读取下一页
try:
response = requests.get(url, headers=headers)
content = response.content.decode('gbk') # 在网页上查看编码格式
# print(content)
# 实例化BeautifulSoup对象
soup = BeautifulSoup(content, 'html.parser')
# print(soup)
# divs=soup.find_all('div',class_="article-pic")
uls = soup.find_all('ul', class_="article")
for ul in uls:
# 获取标题
title = list(ul.find_all('h3'))
# 获取更新日期
times = list(ul.find_all('span', class_="fn-left"))
# 获取内容
profiles = list(ul.find_all('p'))
# print(times,title,profiles)
# 提取标签内的字符串和使用zip打包在一起
for title, times, profiles in zip(title, times, profiles):
title = title.string
times = times.string
profiles = profiles.string
# 将数据存放在字典中
car_news = {
"title": title,
"times": times,
"profiles": profiles,
}
news.append(car_news)
except:
continue
print(news)
- 输出结果
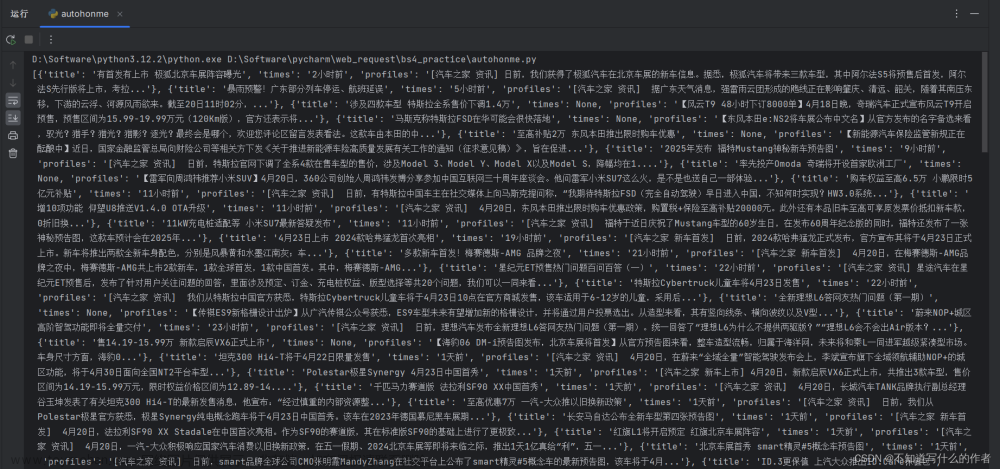
🌟总结
这里需要注意的是使用bs4语句获取的标签内容是bs4的类型,不是列表类型,所以使用了强制转换成列表【list()】.
拓展:
在Python爬虫中,即使代码看起来没有明显语法错误,爬取的数据仍然可能为空,这通常与以下因素有关:文章来源:https://www.toymoban.com/news/detail-857127.html
- 目标网站结构改变:
如果爬虫是基于HTML结构编写的,而目标网站进行了改版或更新,原有的选择器(如XPath或CSS Selector)可能不再有效,导致找不到预期的数据。- 动态加载内容:
网页上的数据可能是通过JavaScript动态加载的,直接爬取HTML源代码可能无法获取这些数据。此时需要分析网页加载逻辑,使用如Selenium、Pyppeteer等工具模拟浏览器行为,或者通过分析Ajax请求来间接获取数据。- 反爬策略:
目标网站可能启用了反爬虫策略,比如Cookies验证、User-Agent限制、IP封锁、验证码、登录验证等。这时,需要针对这些策略进行相应的处理,比如设置更真实的User-Agent、使用代理IP池、处理验证码或模拟登录。- 请求参数不正确:
请求头信息(headers)、cookies、POST数据等参数可能需要特殊配置才能获取数据,如果缺少必要参数或参数不正确,服务器可能不会返回有效数据。- 网络问题:
即使代码看似没问题,网络连接不稳定或服务器端出现问题也可能导致无法获取数据。- 解析逻辑错误:
数据解析环节可能出现问题,例如正则表达式匹配不正确,或者在解析HTML或JSON时引用了不存在的键或属性。- API调用权限或频率限制:
若爬取的是API接口,可能存在调用频率限制、API密钥失效或没有必要的授权。- 数据缓存问题:
如果爬虫有缓存机制并且缓存了错误的结果,新的爬取可能会直接读取缓存而非从服务器获取新数据。
要解决这个问题,可以从以下几个步骤入手:文章来源地址https://www.toymoban.com/news/detail-857127.html
- 检查并确认请求网址是否正确且能够正常访问;
- 使用开发者工具查看网页加载过程,确认数据是如何加载和呈现的;
- 检查请求头和请求体是否符合目标网站的要求;
- 检查解析代码逻辑,特别是提取数据的部分;
- 检测网络状况以及是否有反爬措施,调整爬虫策略;
- 对于动态加载内容,确保相应脚本能够正确执行或模拟;
- 针对可能出现的API限制,合理安排请求间隔,遵循网站的使用协议。
到了这里,关于python爬虫小案例——汽车之家的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!