先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新大数据全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip204888 (备注大数据)
正文
对于浏览器窗口的尺寸进行控制与获取,如最大化、最小化、指定窗口大小等。
窗口全屏
browser.fullscreen_window()
窗口最大化
browser.maximize_window()
窗口最小化
browser.minimize_window()
自定义窗口大小(宽X高)
browser.set_window_size(1080, 720)
自定义窗口坐标位置与大小(x坐标,y坐标,宽X高)
browser.set_window_rect(100, 200, 1080, 720)
获取窗口的大小(宽X高)
browser.get_window_size()
获取窗口的坐标位置,返回一个字典对象
browser.get_window_position()
获取窗口的坐标与大小(x坐标,y坐标,宽X高)
browser.get_window_rect()
获取当前窗口的句柄
browser.current_window_handle
获取当前所有窗口的句柄
browser.window_handles
5.2 页面基础操作
对于浏览器当前页面的一些操作,如前进、后退、刷新等。
前进(下一页面)
browser.forward()
后退(上一页面)
browser.back()
刷新(当前页面)
browser.refresh()
截图并保存为test.png(当前页面)
browser.save_screenshot('test.png')
截图并保存为png文件(当前页面)
browser.get_screenshot_as_file('test\_02.png')
截图并将信息转为base64编码的字符串
browser.get_screenshot_as_base64()
5.3 信息操作
对于浏览器当前一些信息的获取与操作。
获取页面URL(当前页面)
browser.current_url
获取日志类型,会返回一个列表对象
browser.log_types
获取浏览器操作日志,注意函数内的参数为固定值类型’browser’
browser.get_log('browser')
获取设备操作日志,参数原理同上
browser.get_log('driver')
获取当前页面标题
browser.title
获取当前浏览器的名字
browser.name
5.4 元素操作
Selenium中最基础也是最重要的一环,基本上对于页面的业务操作大多数都集中与此。另外需要注意的是元素定位所使用的find_element_by的方法在很早之前就已经被废弃,这里同样也会使用最新的find_element方法进行讲解。
如何查看页面中的元素与其相关属性,这里以Chrome为例,我们只需按F12或者右键页面选择“检查”,再点击调试窗口的左上角的箭头标志或者使用快捷键Ctrl+Shift+C来进行元素的选取,此时Elements标签页中会将焦点对应跳转至该元素的html代码行中,接下来我们就可以针对不同的元素和不同的属性来进行定位操作。
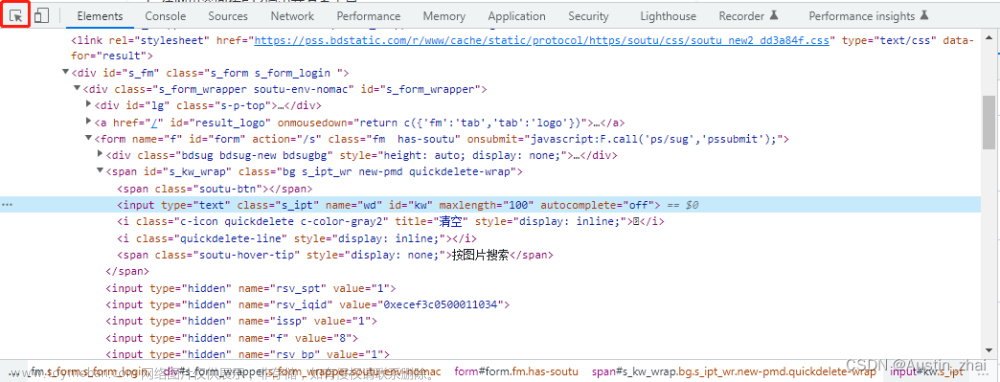
5.4.1 name定位
通过一个元素的name属性来进行定位。
比如定位百度中的搜索栏,我们通过name属性来进行定位。该元素的html构造如下:
<input type="text" class="s\_ipt" name="wd" id="kw" maxlength="100" autocomplete="off">
我们只需将name属性后面的值拿出,赋予给find_element方法即可。新的By方法我们只需要导入selenium.webdriver.common.by下的By方法即可。
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(2)
browser.find_element(By.NAME, 'wd')
5.4.2 class name定位
通过一个元素的class属性来进行定位。
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(2)
browser.find_element(By.CLASS_NAME, 's\_ipt')
5.4.3 id定位
通过一个元素的id属性来进行定位。
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(2)
browser.find_element(By.ID, 'kw')
5.4.4 css定位
css selector也被成为选择器定位,它通过页面内的元素的id、name、tag三个属性来进行定位,根据元素属性的重复程度,可以单独属性定位也可组合属性来进行定位。而且相较于xpath定位方式来说,博主更推荐使用此方法来进行定位,无论是易用度还是维护性来说比xpath定位好的多。
单属性定位–tag属性
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(2)
browser.find_element(By.CSS_SELECTOR, 'input')
单属性定位–id属性
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(2)
browser.find_element(By.CSS_SELECTOR, '#kw')
单属性定位–class属性
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(2)
browser.find_element(By.CSS_SELECTOR, '.s\_ipt')
多属性定位–tag+id属性
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(2)
browser.find_element(By.CSS_SELECTOR, 'input#kw')
多属性定位–tag+class属性
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(2)
browser.find_element(By.CSS_SELECTOR, 'input.s\_ipt')
同样的,其他的组合方式大家可以举一反三,不断尝试,比如模糊匹配input[class ~= "局部关键字"]、层级定位#form > span > input等等等等。
5.4.5 link text定位
这种定位方式适用于页面中带有超链接的元素,直接通过超链接标签内的文字进行元素定位。
我们以百度首页为例,可以看到该页面中有很多的超链接标签,如果我们想模拟点击跳转至新闻对应页面的操作,就可以用link text的元素定位方法来进行实现。

使用超链接标签对中的“新闻”一词来进行定位。
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(2)
browser.find_element(By.LINK_TEXT, '新闻').click()
5.4.6 partial link text定位
这个定位方式与link text定位十分相像,实际上也就是link text的模糊查找定位方式,对象也是超链接内的文字,只不过他匹配的不是全部文字而是局部。
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(2)
browser.find_element(By.PARTIAL_LINK_TEXT, '新').click()
5.4.7 tag定位
tag定位的效率总体来说不高,也不太推荐单独使用,html页面中一般也是由很多相同或不同的标签对组成。就tag而言标签重复的越多,定位的效率其实也就越低。
比如我们想在百度的搜索栏中输入“selenium”关键字,那么光使用tag其实就很难达到我们的目的,甚至无法准确定位到我们想要的元素。如果运气好,搜索栏的input标签在html页面中排在第一位那还好,只要不是第一位,我们就需要编写其他的代码逻辑来辅助我们继续定位这个元素。
所以下面的代码实在是不能称之为高效的执行代码
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(2)
browser.find_element(By.TAG_NAME, 'input').send_keys('selenium')
5.4.8 xpath定位
一般来说无法通过以上的这些元素定位方法定位的情况下,我们会使用xpath定位方法。但这里需要特别注意,xpath方法分为绝对路径和相对路径两种定位方式,博主只推荐如果真要使用xpath就使用相对路径+正则表达式的方式来进行元素定位。不推荐绝对路径的原因就不用博主多说了吧,只要你敢用,后期的脚本维护与复用绝对会让你抓狂的。
还是老样子,我们使用xpath的相对路径写法来定位百度首页的搜索栏。
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(2)
browser.find_element(By.XPATH, '//\*[@id="kw"]').send_keys('selenium')
另外与find_element方法相对应的find_elements方法这里就不多做介绍了,该种方法是将当前页面中所有能匹配上对应元素定位方法的元素全部获取。大家可以根据自己的需求来进行选取和使用。
5.5 延时方式
我们加载页面时通常会因为网络环境等各方面的客观因素而导致元素加载的速度各不相同,如果此时我们没有对业务操作进行一定的延时执行,那么大概率业务操作会出现各类的no such element报错。
那么我们就需要在页面元素加载完成之后再对相应的元素进行业务操作来规避上面说的这个问题。Selenium内可以使用三种延时的函数来进行对应的延时业务操作。
5.5.1 隐式等待
隐式等待的作用是在页面加载是隐性的进行特定时长的等待,如果在规定的等待时长内页面加载完毕,则会继续进入下一个业务操作,如果没有加载完毕,则会抛出一个超时的异常。这里其实有两个问题,第一,隐式等待是全局性质的,也就是说一旦你设置了个5秒,那整个程序都会使用这个等待时间类进行配置,灵活性较低;第二,如果碰到了有些页面中的元素是局部加载的话,那整个页面的加载是否完成也就没有了其意义,隐式加载无法针对这样的情况作出调整,智能度较低。所以一般来说只要是对于页面的整体加载要求不高或者元素的加载比较稳定的程序,都可以使用隐式等待来进行延时操作。
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.implicitly_wait(5)
browser.find_element(By.XPATH, '//\*[@id="kw"]').send_keys('selenium')
5.5.2 显式等待
显式等待的作用则是使用特定的等待时长来进行某些业务逻辑判断,如果判断(比如元素是或否加被定位)在时间完成那继续执行下一个业务操作,如果判断失败也会抛出no such element的异常,而显式等待的默认检查元素周期为0.5秒。乍一看好像与隐式等待差不多,其实不然,首先显式等待是针对页面中某个或某组特定元素而执行的,隐式则是全局,对所有的元素都生效;其二,显式等待可以通过自定义条件来进行元素的定位和选取,隐式则不行。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
ele = WebDriverWait(browser, 10, 0.5).until(EC.presence_of_element_located((By.XPATH, '//\*[@id="kw"]')))
ele.send_keys('selenium')
5.5.3 强制等待
这个应该是平时大家代码中用的最多的等待方式了吧,sleep是针对线程进行挂起的一种等待方式,等待时长根据指定的参数来进行决定。最大的好处就是简单粗暴,无任何逻辑在里面,所以也被称为强制等待。
from selenium import webdriver
from selenium.webdriver.common.by import By
from time import sleep
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
sleep(2)
browser.find_element(By.XPATH, '//\*[@id="kw"]').send_keys('selenium')
那么以上的三种等待方式其实各有各的特点与缺点,三者之间没有绝对的好用和不好用,而在我们的日常工作场景中也希望大家可以根据实际的情况有选择性的使用。
5.6 超时等待
元素加载超时我们可以使用以上三种延时方式来进行处理,那么页面超时了又该如何操作呢?selenium也为我们准备了两个函数来对应这样的局面。
页面加载超时
browser.set_page_load_timeout(30)
这里推荐将超时的时间有效的拉长,不宜过短。过短的超时时间容易导致整体页面出现未加载html代码情况下直接令驱动无法工作的情况。
页面异步js或ajax操作超时
browser.set_script_timeout(30)
这个函数是用于execute_async_script()相关的异步js操作超时报错,由于是异步操作,等待时间同理也不易过短。
5.7 键鼠操作
浏览器中键盘与鼠标的操作也是不可或缺的重要一环,在被测对象的业务要求中往往占有不少的戏份。
文字输入
browser.find_element(By.ID, 'kw').send_keys('selenium')
点击
browser.find_element(By.ID, 'kw').click()
点击并按住不放(左键长按),这些模拟鼠标操作需要导入ActionChains包
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
act = ActionChains(browser)
ele = browser.find_element(By.ID, 'kw')
act.click_and_hold(ele).perform()
右键点击
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
act = ActionChains(browser)
ele = browser.find_element(By.ID, 'kw')
act.context_click(ele).perform()
双击
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
act = ActionChains(browser)
ele = browser.find_element(By.ID, 'kw')
act.double_click(ele).perform()
拖拽元素至另一个元素处,ele_a 为source,ele_b 为target
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
act = ActionChains(browser)
ele_a = browser.find_element(By.ID, 'btn\_a')
ele_b = browser.find_element(By.ID, 'btn\_b')
act.drag_and_drop(ele_a, ele_b).perform()
拖拽元素至指定位置后松开,元素后为x,y坐标值
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
act = ActionChains(browser)
ele = browser.find_element(By.ID, 'btn\_a')
act.drag_and_drop_by_offset(ele, 200, 100).perform()
鼠标移动至指定元素
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
act = ActionChains(browser)
ele = browser.find_element(By.ID, 'btn\_a')
act.move_to_element(ele).perform()
按下指定的键位(示例代码中是回车键)
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
act = ActionChains(browser)
ele = browser.find_element(By.ID, 'kw').send_keys('selenium')
act.key_down(Keys.ENTER).perform()
松开指定的键位,这里也可以用链式写法
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
act = ActionChains(browser)
ele = browser.find_element(By.ID, 'kw').send_keys('selenium')
act.key_down(Keys.ENTER)
act.key_up(Keys.ENTER)
# 链式写法
act.key_down(Keys.ENTER).act.key_up(Keys.ENTER).perform()
移动鼠标到指定坐标位置
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
act = ActionChains(browser)
ele = browser.find_element(By.ID, 'kw').send_keys('selenium')
act.move_by_offset(100, 200).perform()
移动到距离指定元素多少距离的位置(从左上角0, 0开始计算)
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
act = ActionChains(browser)
ele = browser.find_element(By.ID, 'kw').send_keys('selenium')
act.move_to_element_with_offset(ele, 100, 200).perform()
在指定元素位置松开鼠标文章来源地址https://www.toymoban.com/news/detail-860090.html
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)**
 **一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
hains import ActionChains
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
act = ActionChains(browser)
ele = browser.find_element(By.ID, 'kw').send_keys('selenium')
act.move_by_offset(100, 200).perform()
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
hains import ActionChains
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
act = ActionChains(browser)
ele = browser.find_element(By.ID, 'kw').send_keys('selenium')
act.move_by_offset(100, 200).perform()
移动到距离指定元素多少距离的位置(从左上角0, 0开始计算)文章来源:https://www.toymoban.com/news/detail-860090.html
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
act = ActionChains(browser)
ele = browser.find_element(By.ID, 'kw').send_keys('selenium')
act.move_to_element_with_offset(ele, 100, 200).perform()
在指定元素位置松开鼠标
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip204888 (备注大数据)**
[外链图片转存中...(img-z3dMphUl-1713332255939)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
到了这里,关于web自动化测试入门篇03——selenium使用教程_(2)在上述学习基础上,自行选择一个合适的网站,进一步在实践中去运用selenium webd(1)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!