CVPR2024满分文章,英伟达团队工作。
文章地址:https://arxiv.org/pdf/2312.08344.pdf
代码地址:https://github.com/NVlabs/FoundationPose
摘要
提出FoundationPose,能用于6D位姿估计与跟踪,无论模型是否可用都支持。只需要CAD模型或少量参考图像就能进行zero-shot测试,泛化能力依靠大规模训练,LLM和对比学习,达到实例级效果。

(通过这张对比图,能简单看出本方法爆杀之前的各种方法,且能执行多种任务,不难看出大模型让各领域都趋向于多任务统一化。)
一、介绍
将实例级位姿估计归类为传统方法:需要依靠CAD模型生成训练数据,且无法应用到新物体(unseen novel object)。类别级位姿估计不需要CAD模型,但仅限于训练过的预定义类内对象,且类别级位姿估计训练数据制备较难。
为了应对以上问题,最近的解决方案大致分为两类:model-based:依赖3D CAD模型;model-free:用一些参考图像,而不需要模型。本文统一这两种方法。
之后介绍了与位姿估计不同的任务:姿态跟踪,利用时间线索,对视频进行位姿估计。也存在对物体知识假设的依赖。
本方法输入为RGBD,通过神经隐式表示来减少基于模型以及无模型设定的差距。同时使用一种比渲染与比较更快的新视图合成方法,一个LLM辅助合成数据生成的方法。在仅基于合成方法进行训练时实现强大泛化能力。
二、相关工作
基于CAD模型的物体位姿估计
假设为对象给出了纹理CAD模型,训练和测试在完全相同的实例上执行。物体姿态通常通过直接回归,或构建2D-3D对应关系,然后进行PnP求解,或3D-3D之后最小二乘。类别级位姿估计不需要模型,但只能用于同一类别的新对象。目前的研究方向在进行实时估计,且只在推理时提供CAD模型。
Few-shot无模型物体位姿估计
不需要模型,但是需要提供目标对象多个参考图,比如NerF-Pose进行实例级训练但是不需要模型,通过神经辐射场提供对坐标图和掩膜的半监督。本文引入了建立在SDF表示之上的神经对象场,用于高效的RGB和深度渲染,以弥合基于模型和无模型场景之间的差距。
目标位姿跟踪
旨在利用时间线索来实现对视频序列的更高效、平滑和准确的姿态预测。本方法通过神经渲染能简单的扩展到位姿跟踪,
三、方法
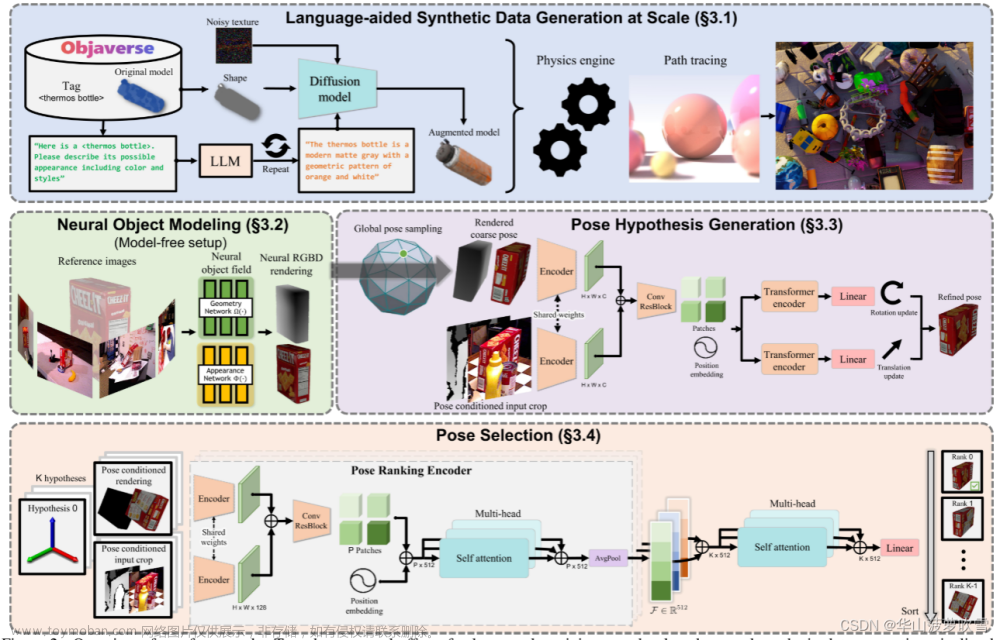
(能看出既用了LLM,又用了扩散模型,还用了神经辐射场。)
语言辅助数据生成
开发了一种新的用于训练的合成数据生成管道,由最近新兴的资源和技术提供支持:大规模3D模型数据库,大型语言模型(LLM)和扩散模型。
LLM进行纹理增强:之前的方法生成的纹理都不够逼真,本文通过使用LLM和扩散模型进行自动且逼真的纹理增强。向TexFusion 提供文本提示、对象形状和随机初始化的噪声纹理,以生成增强纹理模型。此外,利用ChatGPT生成对象可能外观的描述,提示是模板化的,GPT产生的答案作为扩散模型的文本,能实现纹理增强的自动化。
神经对象建模
为了解决无模型对象的渲染。神经隐式表示对于新颖的视图合成是有效的并且在GPU上是可并行的,从而在为下游姿态估计模块渲染多个姿态假设时提供高计算效率。
通过几何函数和外观函数来表示物体,几何函数输入是3D点,输出作为外观函数的中间特征向量。
在原始Nerf渲染基础上增加深度渲染。
姿态假设生成
使用现成的检测器获得2D边界框,并通过框内中值的3D点进行平移初始化,以对象为中心进行均匀采样获得几个全局姿态初始化的旋转。作为初始位姿。
姿态细化:初始化很粗糙,观察到渲染对应于粗略姿势的单个视图就足够了。网络采用基于位姿的裁剪策略而不是基于固定的2D检测来裁剪,以此来反馈平移更新。网络将对象原点投影到图像空间以确定裁剪中心,并将略微放大的对象直径(对象表面上任意两点之间的最大距离)投影出来以确定包含对象及其周围上下文的裁剪大小。
网络架构通过单个共享的CNN编码器从两个RGBD输入分支提取特征图,然后将这些特征图连接起来,并通过具有残差连接的CNN块进行处理,最后通过划分为带有位置嵌入的补丁进行标记化。网络最终预测平移更新∆t和旋转更新∆R,每个更新都由transformer编码器独立处理并线性投影到输出维度。
Pose Selection
通过分层位姿排名网络计算多个细化后的位姿得分,并选择得分最高的位姿作为最终估计。
分层比较
将渲染图像与裁剪输入观察进行比较,使用位姿排名编码器进行,编码器利用与细化网络中相同的骨架架构进行特征提取。提取的特征被连接、标记化,并传递到多头自注意模块,以便更好地利用全局图像上下文进行比较。位姿排名编码器执行平均池化以输出特征嵌入 ,描述渲染与观察之间的对齐质量。
对比验证
为了训练位姿排名网络,提出了位姿条件的三元组损失,损失只计算那些正样本与真实值足够接近的位姿对,以使比较有意义。
(实验部分不写了,相当厉害。之前的跟踪第一帧都是真实值,本方法不用也能爆杀,甚至比用真值效果还好??)文章来源:https://www.toymoban.com/news/detail-861713.html
总结
提出了一个统一的基础模型,用于6D姿态估计和跟踪新的对象,支持基于模型和无模型的设置。对4个不同任务的组合进行的大量实验表明,它不仅是通用的,而且比为每个任务专门设计的现有最先进的方法性能更好。它甚至达到了与那些需要实例级训练的方法相当的结果。未来准备大一统且全面超越各项任务了。
(真的是一个非常吓人的工作了。)文章来源地址https://www.toymoban.com/news/detail-861713.html
到了这里,关于论文阅读:FoundationPose: Unified 6D Pose Estimation and Tracking of Novel Objects-6DoF位姿估计的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!






![[实体关系抽取|顶刊论文]UniRel:Unified Representation and Interaction for Joint Relational Triple Extraction](https://imgs.yssmx.com/Uploads/2024/02/761994-1.png)



