注意:本文内容截止到 2024 年 2 月 26 日发布的 Kafka 3.7.0 版本。
MirrorMaker2(后文简称 MM2)在 2019 年 12 月随 Kafka 2.4.0 一起推出。顾名思义,是为了解决 Kafka 集群之间数据复制和数据同步的问题而诞生的 Kafka 官方的数据复制工具。在实际生产中,经常被用来实现 Kafka 数据的备份,迁移和灾备等目的。
在此也预告一下,AutoMQ 基于 MM2 的迁移产品化功能也即将和大家见面,可以帮助用户更好更快从自建 Kafka 迁移到 AutoMQ,欢迎大家届时使用。
01 安装部署
MM2 一共有三种部署模式,dedicated mode,standalone mode 和 Kafka connect mode。
部署模式
Dedicated mode
直接部署 Kafka MM2,启动命令如下:
./bin/connect-mirror-maker.sh connect-mirror-maker.properties此时 MM2 依然是基于 Kafka Connect,对外封装掉了 Kafka Connect 的复杂度,与此同时也支持分布式部署。One-line 直接拉起 MM2 以及背后的 Kafka Connect,不过相比较来说也丧失掉了一些 Kafka Connect 的灵活性(阉割了 Kafka Connect 对外的 RESTful API)。
Standalone mode
Standalone mode 更像是为测试环境设计的,并不支持分布式部署。这一点在 KIP-382[1] 中也有说明。因为不是一个生产可用的版本,在此不作多赘述。
Kafka Connect mode
此时整个 MM2 的部署是需要一个现成的 Kafka Connect 集群的,MM2 会在 Kafka Connect 上部署自己的 Connector 来完成整个迁移过程。因为 Kafka Connect mode 是 MM2 最复杂的部署模式,而且无论是 Dedicated mode 还是 Kafka Connect mode,背后的原理都是一样,只是前者进行了封装,因此了解 MM2 在 Kafka Connect 上的工作流程最有利于我们对 MM2 有全局了解。
Kafka Connect 在 Kafka 0.9.0 版本中进行推出,旨在简化数据集成和数据流管道的构建,同时提供了一种可拓展,可靠的方式来连接 Kafka 与外部系统。基于这样的设计,MM2 基于 Kafka Connect 进行实现是非常自然的事情。
我们可以把基于 Kafka Connect mode 进行部署的 MM2 里的调度资源分为以下几种:
ꔷ Worker:一个 MM2 或者 Kafka Connect 进程,是进行分布式部署时的基本单位。
ꔷ Connector:单个 Worker 内部执行迁移任务的连接器,一个 Worker 内可以有多个 Connector,每个 Connector 负责相对独立的功能。
ꔷ Task:Connector 将需要迁移的任务进行切分,Task 是并发执行的最小单位。
Kafka Connect 集群
在 Kafka Connect Mode 下,我们需要先准备一个 Kafka Connect 集群,在每个节点上执行以下命令即可启动 Kafka Connect 集群。
./bin/connect-distributed.sh config/connect-distributed.properties在 Kafka Connect 集群部署完成之后,我们可以利用 Kafka Connect 提供的 RESTful API 来启动 MM2 所需要的所有 Connectors。默认情况下,Kafka Connect 提供的端口为 8083。即使 Kafka Connect 集群中有多个节点,但是执行下列的命令只需要向集群中的任一节点发起请求即可。
Connector
假设节点 IP 为本机,启动三个 Connector 的命令如下(实际上向当前 Kafka Connect 集群中的任一节点发起请求即可):
# MirrorSourceConnector
curl -X POST -H "Content-Type: application/json" --data @mirror-source-connector.properties http://127.0.0.1:8083/connectors
# MirrorCheckpointConnector
curl -X POST -H "Content-Type: application/json" --data @mirror-checkpoint-connector.properties http://127.0.0.1:8083/connectors
# MirrorHeartbeatConnector
curl -X POST -H "Content-Type: application/json" --data @mirror-heartbeat-connector.properties http://127.0.0.1:8083/connectors其中 mirror-source-connector.properties,mirror-checkpoint-connector.properties 和 mirror-heartbeat-connector.properties 为对应 Connector 的配置文件。
在启动完 Connector 之后,我们还可以使用以下命令查看当前 Kafka Connect 集群中已经存在的 Connectors。
$ curl http://127.0.0.1:8083/connectors
["mm2-heartbeat-connector","mm2-source-connector","mm2-checkpoint-connector"]%更多关于 Kafka Connect RESTful API 的细节,可以参考 Kafka Connect 101: Kafka Connect's REST API[2]。
02 工作流
从上文可以看到,在 MM2 中,有三个 Connector,它们负责完成整个副本复制过程,这三个 Connector 包括:
ꔷ MirrorSourceConnector:同步源集群中 topic 的消息数据到目标集群。
ꔷ MirrorCheckpointConnector:将源集群的消费位点翻译并同步到目标集群。
ꔷ MirrorHeartbeatConnector:定时往源集群中发送心跳,验证和监控两个集群之间连接和迁移任务的运行情况。
对于 MirrorSourceConnector 和 MirrorCheckpointConnector 提供有 JMX 监控信息,可以帮助对迁移进度和迁移健康状况有全局了解。
MM2 会创建以下几种 Topic(除 heartbeats 之外,所有的 Topic 都会被创建在 target 集群上):
ꔷ connect-configs:存储 MM2 中 connector 的配置信息。
ꔷ connect-offsets:存储 MM2 中 MirrorSourceConnector 和 MirrorCheckpointConnector 的消费位点。
ꔷ connect-status:存储 MM2 中 connector 的状态信息。
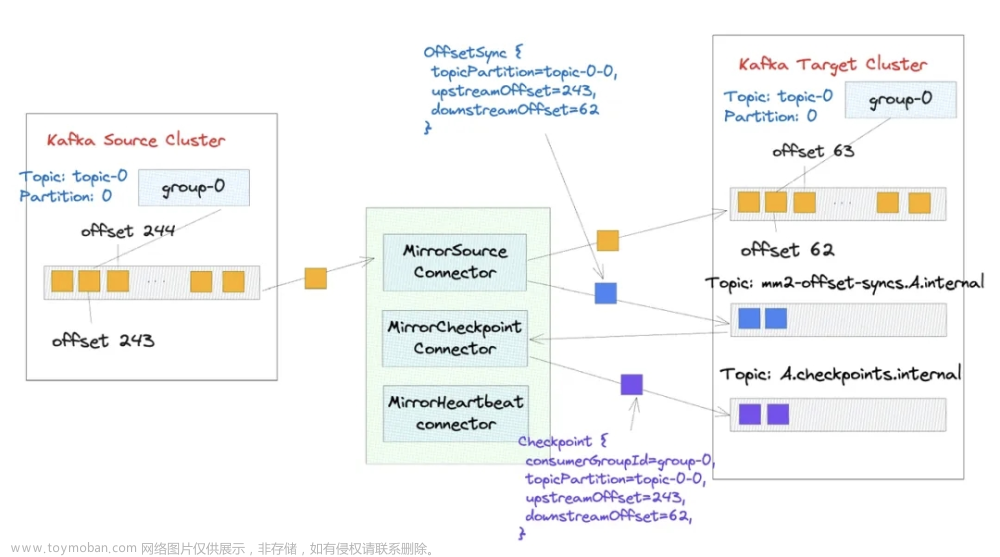
ꔷ mm2-offset-syncs.A.internal:存储消息在源集群和目标集群之间同步的 offset 映射信息(即 OffsetSync 消息)用于消费位点翻译。此 Topic 中的消息由 MirrorSourceConnector 发出(Topic 名中 A 表示源集群的 alias)。
ꔷ A.checkpoints.internal:存储 GroupId 同步的消费进度。具体存储的信息包括 GroupId,Partition 以及在源集群和目标集群的消费位点,此 Topic 中的信息由 MirrorCheckpointConnector 发出(Topic 名中 A 表示源集群的 alias)。
ꔷ heartbeats:定期往源集群发送心跳消息,这部分消息会被同步到目标集群。此 Topic 中的消息体主要存储简单的时间戳信息,其中的消息由 MirrorHeartbeatConnector 发出。
想要了解具体的 MM2 工作流,弄清楚 mm2-offset-syncs.A.internal 和 A.checkpoints.internal 两个 Topic 的作用尤为关键。
消息同步与位点映射
MirrorSourceConnector 会从最早位点开始同步消息。在同步消息时会生成 OffsetSync 消息。OffsetSync 消息中记录了被同步的消息的分区信息,在源集群和目标集群上的位点映射信息。
记录在 OffsetSync 消息中的位点映射信息是非常必要的,首先一条消息从源集群被同步到目标集群上,前后的 offset 大概率是不同的,而且还有可能会出现消息重复和多个源集群的 topic 被同步到一个目标 topic 上的情况,而位点映射能最大程度上帮助我们将源集群的消息和目标集群的消息对应上。
这个 OffsetSync 消息就被存储在 mm2-offset-syncs.A.internal 中。但是并不是每同步一条消息就会生成一个 OffsetSync 消息。默认情况下每隔 100 条消息就会生成一个 OffsetSync 消息,这里的参数可以使用 offset.lag.max 来进行调节。关于 OffsetSync 消息的同步判断,可以参照 org.apache.kafka.connect.mirror.MirrorSourceTask.PartitionState#update 的具体实现细节。
位点翻译
MirrorCheckpointConnector 则会执行具体的位点翻译工作,它会消费 mm2-offset-syncs.A.internal 中的 OffsetSync 消息,然后将源集群上的消费位点翻译成目标集群上的消费位点并执行 alterConsumerGroupOffsets 方法来重置消费者位点。
因为 OffsetSync 没有按照时间间隔同步的逻辑,导致的结果就是当前分区最新的消息位点距离上一次同步的位点如果没有超过 100,则不会生成新的 OffsetSync。而 MirrorCheckpointConnector 是根据 OffsetSync 中的消息位点来同步消费进度的,这样的结果就是目标集群的消费位点基本上不可能被完全同步,最多相比较于源集群会回退 100 个位点。但是在 3.7.0 以及之后的版本中,对 OffsetSync 增加了按照时间同步的兜底逻辑,使得这个问题得到了解决[3]。
详细来说,如果当前消息距离之前的 OffsetSync 中的最新消息没有超过 100 个 offset,但是已经有一段时间没有进行过 OffsetSync 消息的同步了,也会强行进行一次 OffsetSync 消息的同步(由 offset.flush.internal.ms 参数控制,默认为 10S)。

可以通过以下命令方便地查看 OffsetSync 消息的内容。
$ ./bin/kafka-console-consumer.sh --formatter "org.apache.kafka.connect.mirror.formatters.OffsetSyncFormatter" --bootstrap-server 127.0.0.1:9592 --from-beginning --topic mm2-offset-syncs.A.internal
OffsetSync{topicPartition=heartbeats-0, upstreamOffset=0, downstreamOffset=0}
OffsetSync{topicPartition=test-0-0, upstreamOffset=0, downstreamOffset=0}
OffsetSync{topicPartition=test-0-0, upstreamOffset=101, downstreamOffset=101}
OffsetSync{topicPartition=heartbeats-0, upstreamOffset=2, downstreamOffset=2}针对 MM2 中的 HeartbeatConnector,更多的时候则是起到一个观测当前 MM2 集群同步状况的作用。使用以下命令可以查看 HeartbeatTopic 的内容。
$ ./bin/kafka-console-consumer.sh --formatter "org.apache.kafka.connect.mirror.formatters.HeartbeatFormatter" --bootstrap-server 127.0.0.1:9092 --from-beginning --topic heartbeats --property print.key=true
Heartbeat{sourceClusterAlias=A, targetClusterAlias=B, timestamp=1712564822022}
Heartbeat{sourceClusterAlias=A, targetClusterAlias=B, timestamp=1712564842185}
Heartbeat{sourceClusterAlias=A, targetClusterAlias=B, timestamp=1712564862192}
Heartbeat{sourceClusterAlias=A, targetClusterAlias=B, timestamp=1712564882197}
Heartbeat{sourceClusterAlias=A, targetClusterAlias=B, timestamp=1712564902202}这里每 20 秒会生成一条心跳消息,心跳消息包含一条当时的时间戳。这样通过在目标集群查看被同步过来的 heartbeat Topic 中的消息,即可查看当前消息同步状况。
03 负载均衡
在 Kafka Connect 中,一个独立的 Kafka Connect 进程我们称之为一个 worker。在分布式环境下,相同 group.id 的一组 worker 就形成了一个 Kafka Connect 集群。
尽管在负载均衡的过程中,Connector 和 Task 都会参与,但是 Connector 和 Task 并不是正交的。Task 从属于 Connector。Connector 参与负载均衡只是表示具体的 Connector 类中的逻辑会在哪个 worker 中执行。具体的实现逻辑可以参照 EagerAssigner#performTaskAssignment 中的内容:
private Map<String, ByteBuffer> performTaskAssignment(String leaderId, long maxOffset,
Map<String, ExtendedWorkerState> memberConfigs,
WorkerCoordinator coordinator) {
// 用于记录 Connector 分配结果
Map<String /* member */, Collection<String /* connector */>> connectorAssignments = new HashMap<>();
// 用于记录 Task 分配结果
Map<String /* member */, Collection<ConnectorTaskId>> taskAssignments = new HashMap<>();
List<String> connectorsSorted = sorted(coordinator.configSnapshot().connectors());
// 使用一个环形迭代器,将 connector 和 task 分别分配给不同的 worker
CircularIterator<String> memberIt = new CircularIterator<>(sorted(memberConfigs.keySet()));
// 先分配 Connector
for (String connectorId : connectorsSorted) {
String connectorAssignedTo = memberIt.next();
log.trace("Assigning connector {} to {}", connectorId, connectorAssignedTo);
Collection<String> memberConnectors = connectorAssignments.computeIfAbsent(connectorAssignedTo, k -> new ArrayList<>());
memberConnectors.add(connectorId);
}
// 在分配具体的 Task,延续 member 迭代器中的顺序
for (String connectorId : connectorsSorted) {
for (ConnectorTaskId taskId : sorted(coordinator.configSnapshot().tasks(connectorId))) {
String taskAssignedTo = memberIt.next();
log.trace("Assigning task {} to {}", taskId, taskAssignedTo);
Collection<ConnectorTaskId> memberTasks = taskAssignments.computeIfAbsent(taskAssignedTo, k -> new ArrayList<>());
memberTasks.add(taskId);
}
}
// 序列化分配结果并返回
......
}下图展示了有 3 个 Worker,1 个 Connector 以及 5 个 Task 时以及 Worker2 宕机前后的负载均衡情况。
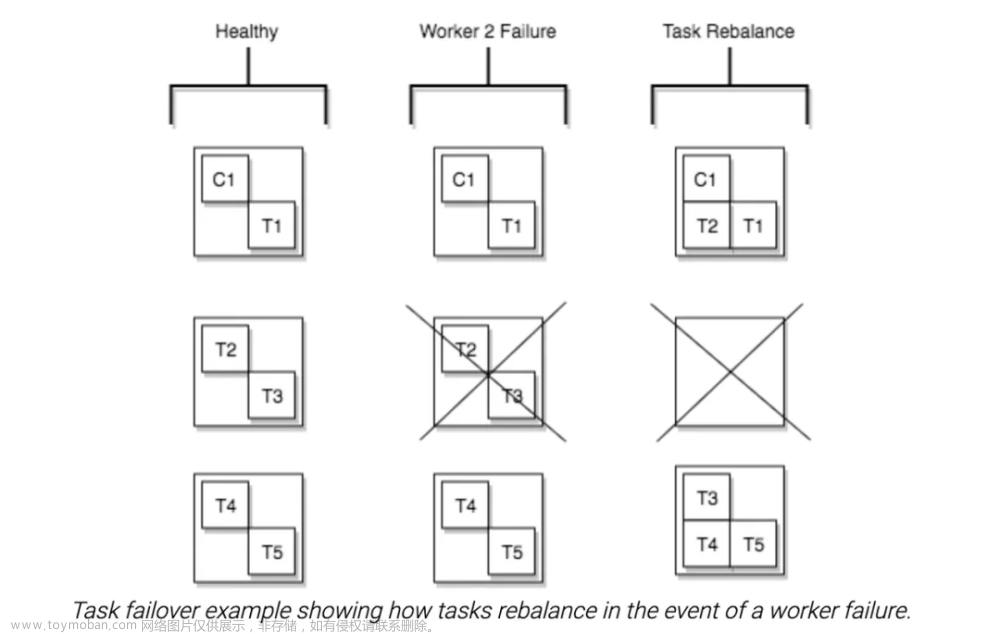
不过这种负载均衡方式会引起比较明显的惊群效应,比如在 Kafka Connect 集群扩缩容的时候,不是新扩缩容的节点也会出现较长的 stop-the-world 问题,在 K8s 环境中如果有节点需要进行滚动升级,也会出现类似的问题。这种负载均衡方式在 Kafka 中称之为 Eager Rebalance。
后面 Kafka 提出了 Incremental Cooperative Rebalance[4],引入了一个延迟时间延后 rebalance 的过程。进行了这样的改进之后,当出现节点滚动升级时,负载均衡就不会马上发生,因为被升级的节点可能很快就回归了,之前负载均衡的结果也能最大限度得到保留,对整体消息同步流程的影响也尽可能降到了最低。相比较来说,Eager Rebalance 可以很快就达到负载均衡的终态,而 Incremental Cooperative Rebalance 则可以最大程度上降低滚动升级等场景下对负载均衡带来的全局影响。
参考资料
[1] KIP-382: MirrorMaker 2.0:https://cwiki.apache.org/confluence/display/KAFKA/KIP-382\%3A+MirrorMaker+2.0
[2] COURSE: KAFKA CONNECT 101 Kafka Connect’s REST API:https://developer.confluent.io/courses/kafka-connect/rest-api/
[3] KAFKA-15906:https://issues.apache.org/jira/browse/KAFKA-15906
[4] Incremental Cooperative Rebalancing in Kafka Connect:https://cwiki.apache.org/confluence/display/KAFKA/KIP-415\%3A+Incremental+Cooperative+Rebalancing+in+Kafka+Connect
[5] KIP-415: Incremental Cooperative Rebalancing in Kafka Connect:https://cwiki.apache.org/confluence/display/KAFKA/KIP-415\%3A+Incremental+Cooperative+Rebalancing+in+Kafka+Connect
[6] KIP-545: support automated consumer offset sync across clusters in MM 2.0:https://cwiki.apache.org/confluence/display/KAFKA/KIP-545\%3A+support+automated+consumer+offset+sync+across+clusters+in+MM+2.0
[7] KIP-656: MirrorMaker2 Exactly-once Semantics:https://cwiki.apache.org/confluence/display/KAFKA/KIP-656\%3A+MirrorMaker2+Exactly-once+Semantics
关于我们
我们是来自 Apache RocketMQ 和 Linux LVS 项目的核心团队,曾经见证并应对过消息队列基础设施在大型互联网公司和云计算公司的挑战。现在我们基于对象存储优先、存算分离、多云原生等技术理念,重新设计并实现了 Apache Kafka 和 Apache RocketMQ,带来高达 10 倍的成本优势和百倍的弹性效率提升。
🌟 GitHub 地址:https://github.com/AutoMQ/automq
💻 官网:https://www.automq.com
👀 B站:AutoMQ官方账号文章来源:https://www.toymoban.com/news/detail-861883.html
🔍 视频号:AutoMQ文章来源地址https://www.toymoban.com/news/detail-861883.html
到了这里,关于Kafka 迁移工具 MirrorMaker2 原理起底的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!