在本文中,我们将了解如何通过连接Apache Kafka代理到MongoDB Atlas并使用CDC解决方案将数据从MongoDB Atlas流式传输到SingleStore Kai。同时,我们还将使用Metabase创建一个简单的SingleStore Kai分析仪表板。
本文末尾附上所使用的代码本文的出处链接。
https://github.com/VeryFatBoy/adtech-kafka-cdc
简介
CDC是一种追踪数据库或系统中发生的更改的方法。SingleStore现在提供与MongoDB配合使用的CDC解决方案。
为了演示CDC解决方案,我们将使用Kafka代理将数据流式传输到MongoDB Atlas集群,并使用CDC管道将数据从MongoDB Atlas传播到SingleStore Kai。我们还将使用Metabase创建一个简单的分析仪表板。
下图显示了系统的高级架构。
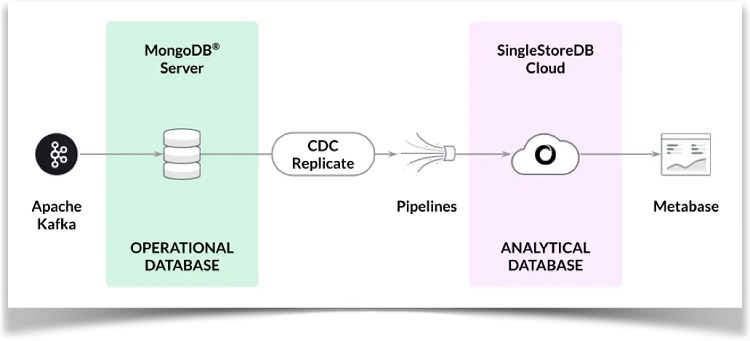
以后会发布重点介绍使用CDC解决方案的其他场景的文章。
MongoDB Atlas
我们将在M0 Sandbox中使用MongoDB Atlas。在Database Access下,我们将配置一个具有atlasAdmin权限的管理员用户。在Network Access下,我们将临时允许从任何地方(IP地址0.0.0.0/0)访问。我们将记录用户名、密码和主机。
Apache Kafka
我们将配置一个Kafka代理将数据流式传输到MongoDB Atlas。我们将使用Jupyter Notebook来实现这一目标。
首先,我们需要安装一些库:
!pip install pymongo kafka-python --quiet
接下来,我们将连接到MongoDB Atlas和Kafka代理:
from kafka import KafkaConsumer
from pymongo import MongoClient
try:
client = MongoClient("mongodb+srv://<username>:<password>@<host>/?retryWrites=true&w=majority")
db = client.adtech
print("连接成功")
except:
print("无法连接")
consumer = KafkaConsumer(
"ad_events",
bootstrap_servers = ["public-kafka.memcompute.com:9092"]
)我们将使用之前从MongoDB Atlas保存的值替换`<username>`、`<password>`和`<host>`。
首先,我们将加载100条记录到MongoDB Atlas中:
MAX_ITERATIONS = 100
for iteration, message in enumerate(consumer, start = 1):
if iteration > MAX_ITERATIONS:
break
try:
record = message.value.decode("utf-8")
user_id, event_name, advertiser, campaign, gender, income, page_url, region, country = map(str.strip, record.split("\t"))
events_record = {
"user_id": int(user_id),
"event_name": event_name,
"advertiser": advertiser,
"campaign": int(campaign.split()[0]),
"gender": gender,
"income": income,
"page_url": page_url,
"region": region,
"country": country
}
db.events.insert_one(events_record)
except Exception as e:
print(f"Iteration {iteration}: 无法插入数据 - {str(e)}")数据应成功加载,并且我们应该看到一个名为`adtech`的数据库和一个名为`events`的集合。集合中的文档应具有类似以下示例的结构:
_id: ObjectId('64ec906d0e8c0f7bcf72a8ed')
user_id: 3857963415
event_name: "Impression"
advertiser: "Sherwin-Williams"
campaign: 13
gender: "Female"
income: "25k and below",
page_url: "/2013/02/how-to-make-glitter-valentines-heart-boxes.html/"
region: "Michigan"
country: "US"这些文档表示广告活动事件。events集合存储了有关广告商、广告活动以及用户的各种人口统计信息,如性别和收入。
SingleStore Kai
SingleStore Kai是一个实时分析平台,可以处理大规模的数据和查询。我们将使用CDC pipeline将数据从MongoDB Atlas传播到SingleStore Kai。
之前的文章展示了创建免费SingleStoreDB Cloud帐户的步骤。我们将使用以下设置:
工作区组名称:CDC Demo Group
云提供商:AWS
地区:US East 1 (N. Virginia)
工作区名称:cdc-demo
大小:S-00
设置:
选择 SingleStore Kai 一旦工作区可用,我们会记下密码和主机信息。从CDC Demo Group > Overview > Workspaces > cdc-demo > Connect > Connect Directly > SQL IDE > Host可以找到主机信息。我们稍后在Metabase中会需要这些信息。
我们还会通过配置CDC Demo Group > Firewall临时允许从任何地方访问。
从左侧导航栏中,我们会选择DEVELOP > SQL Editor来创建一个adtech数据库和链接,如下所示:
CREATE DATABASE IF NOT EXISTS adtech;
USE adtech;
DROP LINK adtech.link;
CREATE LINK adtech.link AS MONGODB
CONFIG '{"mongodb.hosts": "<primary>:27017, <secondary>:27017, <secondary>:27017",
"collection.include.list": "adtech.*",
"mongodb.ssl.enabled": "true",
"mongodb.authsource": "admin",
"mongodb.members.auto.discover": "false"}'
CREDENTIALS '{"mongodb.user": "<username>",
"mongodb.password": "<password>"}';
CREATE TABLES AS INFER PIPELINE AS LOAD DATA LINK adtech.link '*' FORMAT AVRO;我们会用之前从MongoDB Atlas保存的值替换<username>和<password>。我们还需要用MongoDB Atlas中每个地址的完整地址替换<primary>,<secondary>和<secondary>的值。
现在我们来检查是否有任何表,如下所示:
SHOW TABLES;
这应该会显示一个名为events的表:
+------------------+ | Tables_in_adtech | +------------------+ | events | +------------------+
我们来检查表的结构:
DESCRIBE events;
输出应该如下所示:
+-------+------+------+------+---------+-------+ | Field | Type | Null | Key | Default | Extra | +-------+------+------+------+---------+-------+ | _id | text | NO | UNI | NULL | | | _more | JSON | NO | | NULL | | +-------+------+------+------+---------+-------+
接下来,我们来检查是否有任何pipelines:
SHOW PIPELINES;
这将显示一个名为events的pipeline,目前处于停止状态:
+---------------------+---------+-----------+ | Pipelines_in_adtech | State | Scheduled | +---------------------+---------+-----------+ | events | Stopped | False | +---------------------+---------+-----------+
现在我们来启动events pipeline:
START ALL PIPELINES;
状态应该变为Running:
+---------------------+---------+-----------+ | Pipelines_in_adtech | State | Scheduled | +---------------------+---------+-----------+ | events | Running | False | +---------------------+---------+-----------+
如果我们现在运行以下命令:
SELECT COUNT(*) FROM events;
它应该返回结果100:
+----------+ | COUNT(*) | +----------+ | 100 | +----------+
我们检查events表中的一行,如下所示:
SELECT * FROM events LIMIT 1;
输出应类似于以下内容:
+--------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| _id | _more |
+--------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| {"$oid": "64ec906d0e8c0f7bcf72a8f7"} | {"_id":{"$oid":"64ec906d0e8c0f7bcf72a8f7"},"advertiser":"Wendys","campaign":13,"country":"US","event_name":"Click","gender":"Female","income":"75k - 99k","page_url":"/2014/05/flamingo-pop-bridal-shower-collab-with.html","region":"New Mexico","user_id":3857963416} |
+--------------------------------------+-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+成功连接到MongoDB Atlas并将所有100条记录复制到SingleStore Kai的CDC解决方案。
现在,让我们使用Metabase创建一个仪表板。
Metabase
在之前的文章中,我们详细介绍了安装、配置和创建与Metabase的连接的方法。我们将使用稍微变化的查询来创建可视化。
1. 事件总数SQL
SELECT COUNT(*) FROM events;
2. 按地区统计事件SQL
SELECT _more::country AS `events.country`, COUNT(_more::country) AS 'events.countofevents' FROM adtech.events AS events GROUP BY 1;
3. 前5个广告商的事件数量SQL
SELECT _more::advertiser AS `events.advertiser`, COUNT(*) AS `events.count` FROM adtech.events AS events WHERE (_more::advertiser LIKE '%Subway%' OR _more::advertiser LIKE '%McDonals%' OR _more::advertiser LIKE '%Starbucks%' OR _more::advertiser LIKE '%Dollar General%' OR _more::advertiser LIKE '%YUM! Brands%' OR _more::advertiser LIKE '%Dunkin Brands Group%') GROUP BY 1 ORDER BY `events.count` DESC;
4. 广告访客按性别和收入分类SQL
SELECT * FROM (SELECT *, DENSE_RANK() OVER (ORDER BY xx.z___min_rank) AS z___pivot_row_rank, RANK() OVER (PARTITION BY xx.z__pivot_col_rank ORDER BY xx.z___min_rank) AS z__pivot_col_ordering, CASE WHEN xx.z___min_rank = xx.z___rank THEN 1 ELSE 0 END AS z__is_highest_ranked_cell FROM (SELECT *, Min(aa.z___rank) OVER (PARTITION BY aa.`events.income`) AS z___min_rank FROM (SELECT *, RANK() OVER (ORDER BY CASE WHEN bb.z__pivot_col_rank = 1 THEN (CASE WHEN bb.`events.count` IS NOT NULL THEN 0 ELSE 1 END) ELSE 2 END, CASE WHEN bb.z__pivot_col_rank = 1 THEN bb.`events.count` ELSE NULL END DESC, bb.`events.count` DESC, bb.z__pivot_col_rank, bb.`events.income`) AS z___rank FROM (SELECT *, DENSE_RANK() OVER (ORDER BY CASE WHEN ww.`events.gender` IS NULL THEN 1 ELSE 0 END, ww.`events.gender`) AS z__pivot_col_rank FROM (SELECT _more::gender AS `events.gender`, _more::income AS `events.income`, COUNT(*) AS `events.count` FROM adtech.events AS events WHERE (_more::income <> 'unknown' OR _more::income IS NULL) GROUP BY 1, 2) ww) bb WHERE bb.z__pivot_col_rank <= 16384) aa) xx) zz WHERE (zz.z__pivot_col_rank <= 50 OR zz.z__is_highest_ranked_cell = 1) AND (zz.z___pivot_row_rank <= 500 OR zz.z__pivot_col_ordering = 1) ORDER BY zz.z___pivot_row_rank;
下图显示了在AdTech仪表板上调整大小和位置的图表示例。
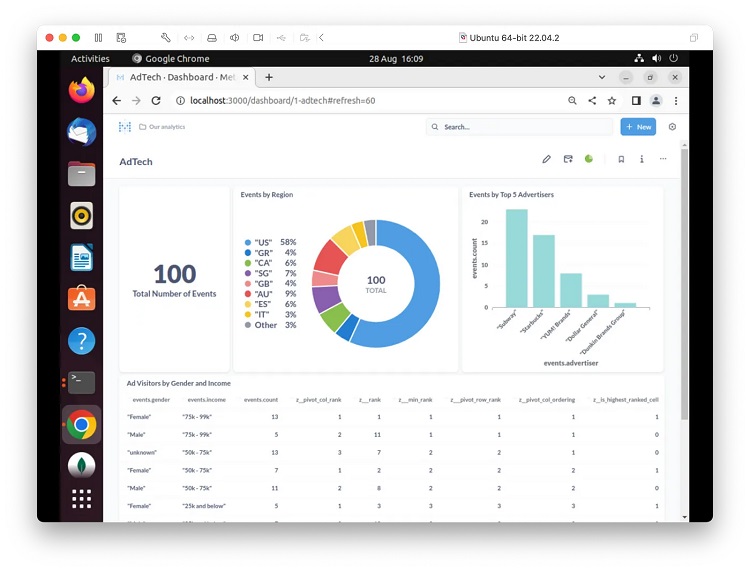
我们将设置自动刷新选项为1分钟。文章来源:https://www.toymoban.com/diary/system/666.html
如果我们在MongoDB Atlas中使用Jupyter笔记本加载更多数据,只需更改MAX_ITERATIONS,我们将看到数据传播到SingleStore Kai,并在AdTech仪表板中反映出新的数据。文章来源地址https://www.toymoban.com/diary/system/666.html
到此这篇关于使用Kafka和CDC将数据从MongoDB Atlas流式传输到SingleStore Kai的文章就介绍到这了,更多相关内容可以在右上角搜索或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!