-
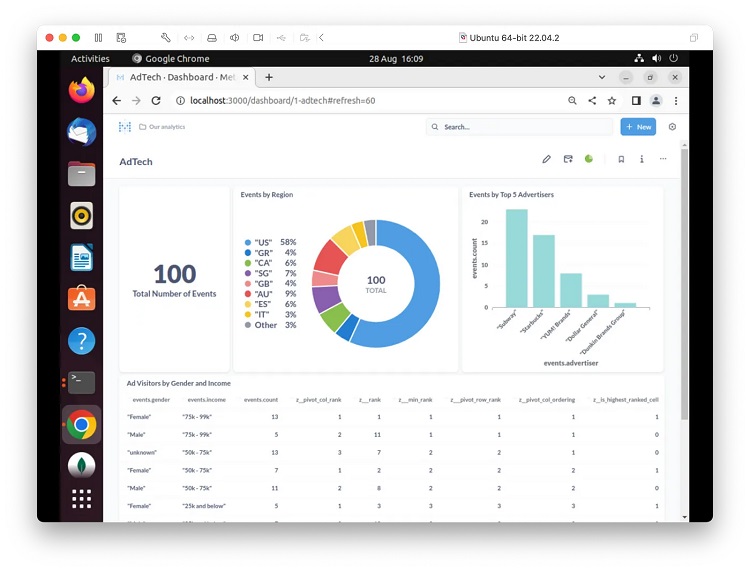
使用Kafka和CDC将数据从MongoDB Atlas流式传输到SingleStore Kai
本文介绍了如何使用CDC解决方案,将数据从MongoDB Atlas流式传输到SingleStore Kai,并使用Kafka作为中间件。还将演示如何使用Metabase创建单个分析仪表板。
-
【天衍系列 05】Flink集成KafkaSink组件:实现流式数据的可靠传输 & 高效协同
Flink版本: 本文主要是基于Flink1.14.4 版本 导言: Apache Flink 作为流式处理领域的先锋,为实时数据处理提供了强大而灵活的解决方案。其中,KafkaSink 是 Flink 生态系统中的关键组件之一,扮演着将 Flink 处理的数据可靠地发送到 Kafka 主题的角色。本文将深入探讨 KafkaSink 的工作
-
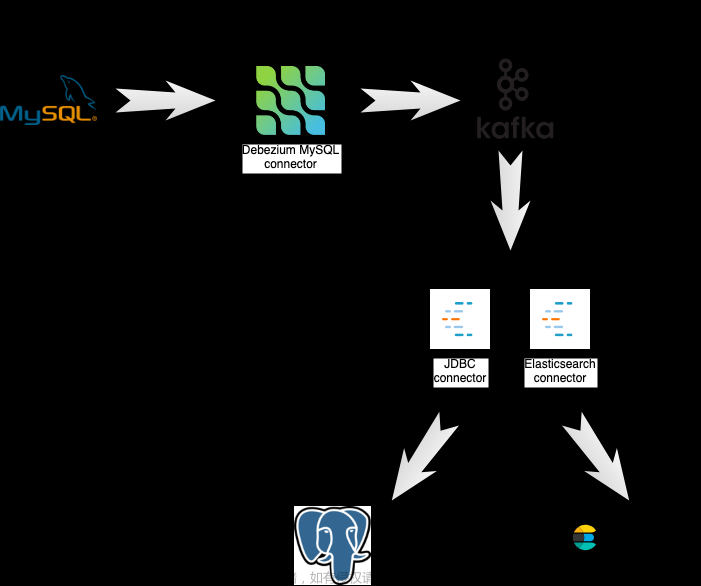
Debezium系列之:基于debezium将mysql数据库数据更改流式传输到 Elasticsearch和PostgreSQL数据库
基于 Debezium 的端到端数据流用例,将数据流式传输到 Elasticsearch 服务器,以利用其出色的功能对我们的数据进行全文搜索。 同时把数据流式传输到 PostgreSQL 数据库,通过 SQL 查询语言来优化对数据的访问。 下面的图表显示了数据如何流经我们的分布式系统。首先,Debezium M
-
ChatGPT流式传输(stream=True)的实现-OpenAI API 流式传输
默认情况下,当请求OpenAI的API时,整个响应将在生成后一次性发送回来。如果需要的响应比较复杂,就会需要很长时间来等待响应。 为了更快地获得响应,可以在请求API时选择“流式传输”。 要使用流式传输,调用API时设置 stream=True 。这将返回一个对象,以 data-only server-
-
java http流式传输
Java中的HTTP流式传输是指在Java应用程序中使用流的方式来发送和接收HTTP请求和响应。这种方式通常用于在Java应用程序中处理大量数据或实时数据流。 Java中有许多不同的库和框架可用于实现HTTP流式传输,例如Apache HttpComponents、Java Async HTTP Client(AsyncHttpClient)和Java WebSocket。这些
-
websocket 流式传输 交易订单更新
对于从事加密货币行业的任何人来说,使用 REST api 从交易所查询实时数据并不总是最佳做法,原因有很多: 效率低下:每个查询都需要时间,并且会显着影响性能,尤其是对于高频策略。 交易所施加的限制很容易被打破,例如Binance的硬限制为每分钟 1200 个请求权重。 您只
-
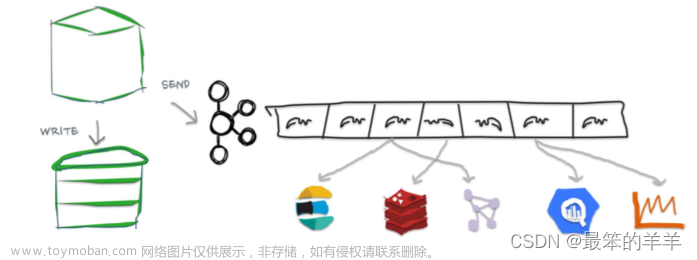
Debezium日常分享系列之:流式传输 Cassandra
选择Cassandra 这个 NoSQL 数据库,主要是因为它的高可用性、水平可扩展性以及处理高写入吞吐量的能力。 将 Cassandra 引入我们的基础设施后,我们的下一个挑战是找到一种方法将 Cassandra 中的数据公开给我们的数据仓库 BigQuery,以进行分析和报告。我们快速构建了一个 Airflow
-
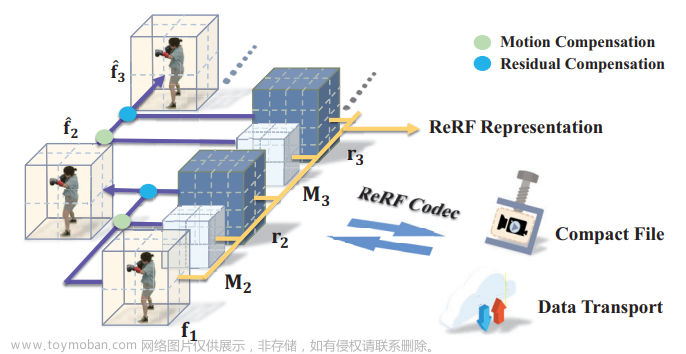
用于流式传输自由视点视频的神经残余辐射场
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 本周主要阅读了2023CVPR的文章,用于流式传输自由视点视频的神经残余辐射场,在文章中讲解了一种基于神经残余辐射场实现流式传输自由视点视频的方法,其主要思路就是建模时空特征空间中相邻时间
-

实时云渲染服务:流式传输 VR 和 AR 内容
想象一下无需专用的物理计算机,甚至无需实物连接,就能获得高质量的 AR/VR 体验是种什么样的体验? 过去,与 VR 交互需要专用的高端工作站,并且根据头显、壁挂式传感器和专用的物理空间。VR 中的复杂任务会突破传感器范围、电缆长度和空间边界的限制,使艺术家陷入
-
Debezium日常分享系列之:流式传输Cassandra第二部分
在本博客文章系列的前半部分中,解释了Cassandra 设计流数据管道的决策过程。在这篇文章中,我们将把管道分为三个部分,并更详细地讨论每个部分: Cassandra 到 Kafka 与 CDC 代理 Kafka 与 BigQuery 和 KCBQ 使用 BigQuery 视图进行转换 相关技术博客: Debezium日常分享系列之:流式传输
-
使用 Python 流式传输来自 OpenAI API 的响应:分步指南
OpenAI API 提供了大量可用于执行各种 NLP 任务的尖端 AI 模型。但是,在某些情况下,仅向 OpenAI 发出 API 请求可能还不够,例如需要实时更新时。这就是服务器发送事件 (SSE) 发挥作用的地方。 SSE 是一种简单有效的技术,用于将数据从服务器实时流式传输到客户端。 如何在 W
-
自然语言处理从入门到应用——LangChain:模型(Models)-[聊天模型(Chat Models):使用少量示例和响应流式传输]
分类目录:《大模型从入门到应用》总目录 LangChain系列文章: 基础知识 快速入门 安装与环境配置 链(Chains)、代理(Agent:)和记忆(Memory) 快速开发聊天模型 模型(Models) 基础知识 大型语言模型(LLMs) 基础知识 LLM的异步API、自定义LLM包装器、虚假LLM和人类输入LLM(
-
JavaScript前端接收流式数据
在Java开发中,前端接收流式数据通常涉及到使用WebSocket 或Server-Sent Events(SSE)这样的技术。这两种技术都允许服务器推送实时数据到客户端,以便在浏览器中进行处理和更新。 1. WebSocket: WebSocket是一种在单个 TCP 连接上进行全双工通信的协议。在Java 中,你可以使用Java
-
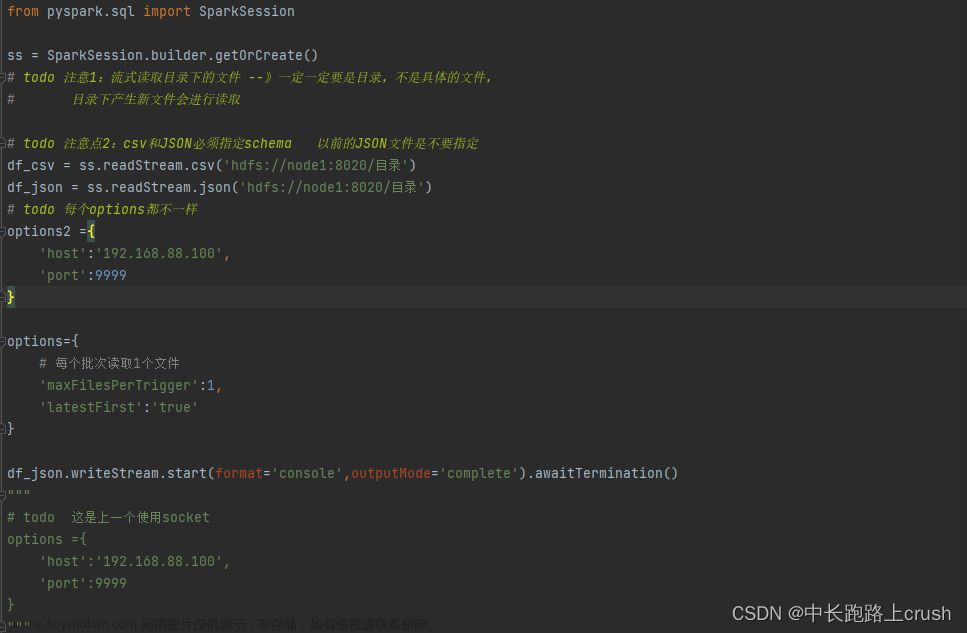
Spark流式读取文件数据
流式读取文件数据 from pyspark.sql import SparkSession ss = SparkSession.builder.getOrCreate() df_csv = ss.readStream.csv(‘hdfs://node1:8020/目录’) df_json = ss.readStream.json(‘hdfs://node1:8020/目录’) options2 ={ ‘host’:‘192.168.88.100’, ‘port’:9999 } options={ # 每个批次读取1个文件 ‘maxFilesPerTrigger’:1, ‘lat
-
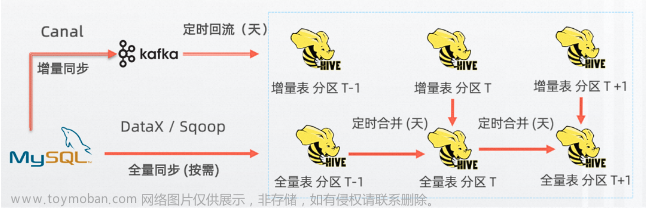
聊聊流式数据湖Paimon(二)
Apache Paimon 最典型的场景是解决了 CDC (Change Data Capture) 数据的入湖;CDC 数据来自数据库。一般来说,分析需求是不会直接查询数据库的。 容易对业务造成影响,一般分析需求会查询全表,这可能导致数据库负载过高,影响业务 分析性能不太好,业务数据库一般不是列存,查