- Paddle Serving服务化部署实战
- 准备预测数据和部署环境
-
环境准备
- 安装 PaddlePaddle 2.0
- 安装 PaddleOCR
- 准备PaddleServing的运行环境,
- 模型转换
-
Paddle Serving pipeline部署
- 确认工作目录下文件结构:
- 启动服务可运行如下命令:
-
测试
- Python发送服务请求:
- Postman 发送请求
- 参数调整
百度飞桨(PaddlePaddle) - PP-OCRv3 文字检测识别系统 预测部署简介与总览
百度飞桨(PaddlePaddle) - PP-OCRv3 文字检测识别系统 Paddle Inference 模型推理(离线部署)
百度飞桨(PaddlePaddle) - PP-OCRv3 文字检测识别系统 基于 Paddle Serving快速使用(服务化部署 - CentOS)
百度飞桨(PaddlePaddle) - PP-OCRv3 文字检测识别系统 基于 Paddle Serving快速使用(服务化部署 - Docker)推荐
Paddle Serving 是飞桨服务化部署框架,能够帮助开发者轻松实现从移动端、服务器端调用深度学习模型的远程预测服务。 Paddle Serving围绕常见的工业级深度学习模型部署场景进行设计,具备完整的在线服务能力,支持的功能包括多模型管理、模型热加载、基于Baidu-RPC的高并发低延迟响应能力、在线模型A/B实验等,并提供简单易用的Client API。Paddle Serving可以与飞桨训练框架联合使用,从而训练与远程部署之间可以无缝过度,让用户轻松实现预测服务部署,大大提升了用户深度学习模型的落地效率。
Paddle Serving服务化部署框架(PIP安装方式、Docker安装)
最新wheel包合集
Paddle Serving服务化部署实战
服务化部署指的是,将模型以服务的形式进行部署,其他的设备可以通过发送请求的形式去访问服务,从而获取模型服务的推理结果。服务化部署示意图如下所示。
在模型部署成功后,不同用户都可以通过客户端,以发送网络请求的方式获得推理服务。
基于Paddle Serving部署PP-OCRv2系统流程图
准备预测数据和部署环境
数据与模型推理所用数据一致。
运行Paddle Serving,需要安装Paddle Serving三个安装包:paddle-serving-server、paddle-serving-client 和 paddle-serving-app,命令如下。
https://pypi.tuna.tsinghua.edu.cn/simple/
环境准备
虚机配置:CentOS 7 、 内存:12G、CPU:4核
本文版本号:
PaddlePaddle 2.2.2
PaddleOCR 2.6
注意: Python 版本 (Docker 镜像中的 Python 已经集成好,比较方便:Python 3.7.12)
PaddlePaddle 2.4.0 - => Python 3.7.4
PaddlePaddle 2.4.1 + => Python 3.9.0
尽量保持一致,防止麻烦
首先下载PaddleOCR代码,安装相关依赖,具体命令如下
准备PaddleOCR的运行环境:https://gitee.com/paddlepaddle/PaddleOCR/blob/release/2.6/doc/doc_ch/installation.md
Linux 升级安装 Python 3
安装 PaddlePaddle 2.0
# 注意版本,原来电脑是 3.8 的。非常麻烦
[root@localhost PaddleOCR]# python -V
Python 3.7.4
[root@localhost PaddleOCR]# pip install -U pip
# 如果您的机器是CPU,请运行以下命令安装
[root@localhost PaddleOCR]# pip install paddlepaddle==2.2.2 -i https://mirror.baidu.com/pypi/simple
# 如果您的机器安装的是CUDA9或CUDA10,请运行以下命令安装
# python3 -m pip install paddlepaddle-gpu==2.2.2 -i https://mirror.baidu.com/pypi/simple
# VQA任务中需要用到该库 -- 不安装也没报错
#[root@localhost PaddleOCR]# pip install paddlenlp==2.0.1 -i https://mirror.baidu.com/pypi/simple
安装 PaddleOCR
[root@localhost ~]# cd /opt
# 下载代码
[root@localhost opt]# git clone https://gitee.com/paddlepaddle/PaddleOCR.git
[root@localhost opt]# cd /opt/PaddleOCR
# 安装运行所需要的whl包
[root@localhost PaddleOCR]# pip install -r requirements.txt -i https://mirror.baidu.com/pypi/simple
准备PaddleServing的运行环境,
步骤如下:
[root@localhost PaddleOCR]# pwd
/opt/PaddleOCR
# 安装serving,用于启动服务 https://pypi.tuna.tsinghua.edu.cn/simple/paddle-serving-server/
[root@localhost PaddleOCR]# wget https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_server-0.8.3-py3-none-any.whl
[root@localhost PaddleOCR]# pip install paddle_serving_server-0.8.3-py3-none-any.whl
# GPU 安装下面地址
# wget https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_server_gpu-0.8.3.post102-py3-none-any.whl
# pip3 install paddle_serving_server_gpu-0.8.3.post102-py3-none-any.whl
# 如果是cuda10.1环境,可以使用下面的命令安装paddle-serving-server
# wget https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_server_gpu-0.8.3.post101-py3-none-any.whl
# pip3 install paddle_serving_server_gpu-0.8.3.post101-py3-none-any.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装client,用于向服务发送请求, https://pypi.tuna.tsinghua.edu.cn/simple/paddle-serving-client/
# cp37 => python 3.7, 版本要对应,否则报 ERROR: paddle_serving_client-0.8.3-cp37-none-any.whl is not a supported wheel on this platform.
[root@localhost PaddleOCR]# wget https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_client-0.8.3-cp37-none-any.whl
[root@localhost PaddleOCR]# pip install paddle_serving_client-0.8.3-cp37-none-any.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
# 安装serving-app https://pypi.tuna.tsinghua.edu.cn/simple/paddle-serving-app/
[root@localhost PaddleOCR]# wget https://paddle-serving.bj.bcebos.com/test-dev/whl/paddle_serving_app-0.8.3-py3-none-any.whl
# 需要单独安装一下,否则 pip install paddle_serving_app-0.8.3-py3-none-any.whl 安装时会报 安装 opencv 超时
[root@localhost PaddleOCR]# pip install opencv-python==3.4.17.61 -i https://pypi.tuna.tsinghua.edu.cn/simple --verbose
[root@localhost PaddleOCR]# pip install paddle_serving_app-0.8.3-py3-none-any.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
模型转换
使用PaddleServing做服务化部署时,需要将保存的inference模型转换为serving易于部署的模型。
首先,下载PP-OCR的inference模型
[root@localhost PaddleOCR]# cd /opt/PaddleOCR/deploy/pdserving/
# 下载并解压 OCR 文本检测模型
[root@localhost pdserving]# wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_det_infer.tar -O ch_PP-OCRv3_det_infer.tar && tar -xf ch_PP-OCRv3_det_infer.tar
# 下载并解压 OCR 文本识别模型
[root@localhost pdserving]# wget https://paddleocr.bj.bcebos.com/PP-OCRv3/chinese/ch_PP-OCRv3_rec_infer.tar -O ch_PP-OCRv3_rec_infer.tar && tar -xf ch_PP-OCRv3_rec_infer.tar
# 降级,否则转换模型会报错,-> ImportError: urllib3 v2.0 only supports OpenSSL 1.1.1+, currently the 'ssl' module is compiled with OpenSSL 1.0.2k-fips 26 Jan 2017
[root@localhost pdserving]# pip install urllib3==1.25.6 -i https://pypi.tuna.tsinghua.edu.cn/simple --verbose
[root@localhost pdserving]# pip show urllib3
Name: urllib3
Version: 1.25.6
接下来,用安装的paddle_serving_client把下载的inference模型转换成易于server部署的模型格式。
# 转换检测模型
[root@localhost pdserving]# python -m paddle_serving_client.convert --dirname ./ch_PP-OCRv3_det_infer/ \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--serving_server ./ppocr_det_v3_serving/ \
--serving_client ./ppocr_det_v3_client/
# 转换识别模型
[root@localhost pdserving]# python -m paddle_serving_client.convert --dirname ./ch_PP-OCRv3_rec_infer/ \
--model_filename inference.pdmodel \
--params_filename inference.pdiparams \
--serving_server ./ppocr_rec_v3_serving/ \
--serving_client ./ppocr_rec_v3_client/
# 安装 tree 工具
[root@localhost pdserving]# yum -y install tree
# 查看文件夹
[root@localhost pdserving]# tree -h *_client *_serving
ppocr_det_v3_client
├── [ 214] serving_client_conf.prototxt
└── [ 56] serving_client_conf.stream.prototxt
ppocr_rec_v3_client
├── [ 229] serving_client_conf.prototxt
└── [ 59] serving_client_conf.stream.prototxt
ppocr_det_v3_serving
├── [2.3M] inference.pdiparams
├── [1.3M] inference.pdmodel
├── [ 214] serving_server_conf.prototxt
└── [ 56] serving_server_conf.stream.prototxt
ppocr_rec_v3_serving
├── [ 10M] inference.pdiparams
├── [1.2M] inference.pdmodel
├── [ 229] serving_server_conf.prototxt
└── [ 59] serving_server_conf.stream.prototxt
0 directories, 12 files
[root@localhost pdserving]#
检测模型转换完成后,会在当前文件夹多出ppocr_det_v3_serving 和ppocr_det_v3_client的文件夹,具备如下格式:
|- ppocr_det_v3_serving/
|- __model__
|- __params__
|- serving_server_conf.prototxt
|- serving_server_conf.stream.prototxt
|- ppocr_det_v3_client
|- serving_client_conf.prototxt
|- serving_client_conf.stream.prototxt
Paddle Serving pipeline部署
确认工作目录下文件结构:
注意: 将PaddleOCR/deploy/pdserving/config.yml文件中的两个model_config字段,对应模型转换的文件夹。
pdserver目录包含启动pipeline服务和发送预测请求的代码,包括:
__init__.py
config.yml # 启动服务的配置文件
ocr_reader.py # OCR模型预处理和后处理的代码实现
pipeline_http_client.py # 发送pipeline预测请求的脚本
web_service.py # 启动pipeline服务端的脚本
启动服务可运行如下命令:
[root@localhost pdserving]# cd /opt/PaddleOCR/deploy/pdserving/
# 如果报错,执行 ImportError: libGL.so.1: cannot open shared object file: No such file or directory
[root@localhost pdserving]# yum -y install libGL
# 启动服务,运行日志保存在log.txt
[root@localhost pdserving]# nohup python web_service.py --config=config.yml &>log.txt &
[root@localhost pdserving]# tail -f ./log.txt
成功启动服务后,log.txt中会打印类似如下日志
测试
Python发送服务请求:
[root@localhost PaddleOCR]# cd /opt/PaddleOCR/deploy/pdserving/
[root@localhost pdserving]# python pipeline_http_client.py
**********../../doc/imgs/00006737.jpg**********
erro_no:0, err_msg:
('登机牌', 0.98663443), [[156.0, 27.0], [353.0, 24.0], [354.0, 67.0], [157.0, 70.0]]
('BOARDING PASS', 0.92134), [[422.0, 23.0], [819.0, 15.0], [820.0, 55.0], [423.0, 63.0]]
('序号SERIALNO.', 0.90068984), [[490.0, 103.0], [663.0, 101.0], [663.0, 120.0], [490.0, 122.0]]
('CLASS', 0.9126972), [[398.0, 106.0], [455.0, 104.0], [456.0, 122.0], [399.0, 124.0]]
('舱位', 0.997319), [[343.0, 107.0], [385.0, 107.0], [385.0, 125.0], [343.0, 125.0]]
('日期 DATE', 0.8522339), [[213.0, 108.0], [317.0, 107.0], [317.0, 127.0], [213.0, 128.0]]
('座位号SEAT NO', 0.9227149), [[677.0, 99.0], [833.0, 96.0], [833.0, 116.0], [677.0, 119.0]]
('航班 FLIGHT', 0.9386937), [[64.0, 112.0], [191.0, 108.0], [191.0, 128.0], [64.0, 132.0]]
('W', 0.818372), [[406.0, 132.0], [430.0, 132.0], [430.0, 157.0], [406.0, 157.0]]
('035', 0.881623), [[511.0, 130.0], [567.0, 130.0], [567.0, 155.0], [511.0, 155.0]]
('O3DEC', 0.96435463), [[233.0, 138.0], [325.0, 136.0], [325.0, 157.0], [233.0, 159.0]]
('MU2379', 0.99732345), [[83.0, 140.0], [212.0, 137.0], [212.0, 160.0], [83.0, 162.0]]
('登机口', 0.82893676), [[489.0, 174.0], [553.0, 173.0], [553.0, 193.0], [490.0, 195.0]]
('GATE', 0.99797326), [[566.0, 174.0], [612.0, 172.0], [613.0, 190.0], [567.0, 192.0]]
('始发地', 0.9969302), [[343.0, 175.0], [409.0, 174.0], [410.0, 194.0], [344.0, 196.0]]
('FROM', 0.9880336), [[404.0, 175.0], [468.0, 175.0], [468.0, 193.0], [404.0, 193.0]]
('登机时间BDT', 0.96257985), [[678.0, 170.0], [810.0, 168.0], [810.0, 188.0], [678.0, 190.0]]
('目的地TO', 0.93609524), [[67.0, 181.0], [168.0, 178.0], [168.0, 198.0], [68.0, 202.0]]
('福州', 0.99901855), [[97.0, 207.0], [167.0, 206.0], [168.0, 227.0], [98.0, 229.0]]
('TAIYUAN', 0.950216), [[338.0, 219.0], [473.0, 216.0], [473.0, 235.0], [338.0, 239.0]]
('G11', 0.6856508), [[505.0, 214.0], [553.0, 214.0], [553.0, 235.0], [505.0, 235.0]]
('FUZHOU', 0.9885346), [[91.0, 231.0], [201.0, 227.0], [202.0, 248.0], [91.0, 251.0]]
('身份识别ID NO', 0.89463985), [[345.0, 240.0], [482.0, 236.0], [482.0, 256.0], [345.0, 259.0]]
('姓名NAME', 0.974122), [[67.0, 251.0], [172.0, 249.0], [172.0, 268.0], [67.0, 270.0]]
('ZHANGQIWET', 0.89279824), [[77.0, 278.0], [262.0, 274.0], [262.0, 294.0], [77.0, 297.0]]
('票号 TKTNO', 0.92473453), [[462.0, 297.0], [578.0, 295.0], [578.0, 315.0], [462.0, 317.0]]
('张祺伟', 0.9672684), [[103.0, 313.0], [208.0, 311.0], [208.0, 334.0], [103.0, 336.0]]
('票价FARE', 0.9370956), [[70.0, 344.0], [164.0, 341.0], [165.0, 362.0], [70.0, 364.0]]
('ETKT7813699238489/1', 0.9605237), [[346.0, 349.0], [660.0, 347.0], [660.0, 366.0], [346.0, 368.0]]
Postman 发送请求
Python 读取图片 转 base64 并生成 JSON
import json
import base64
img_path = r'D:\OpenSource\PaddleOCR-release-2.6\doc\imgs\00006737.jpg';
with open(img_path, 'rb') as file:
image_data1 = file.read()
image = base64.b64encode(image_data1).decode('utf8')
data = {"key": ["image"], "value": [image]}
# 转成 json 字符串
json_str = json.dumps(data)
print(json_str)
{"key": ["image"], "value": ["image base64"]}
将生成的 json - 图片base64,复制到 Postman 中执行如下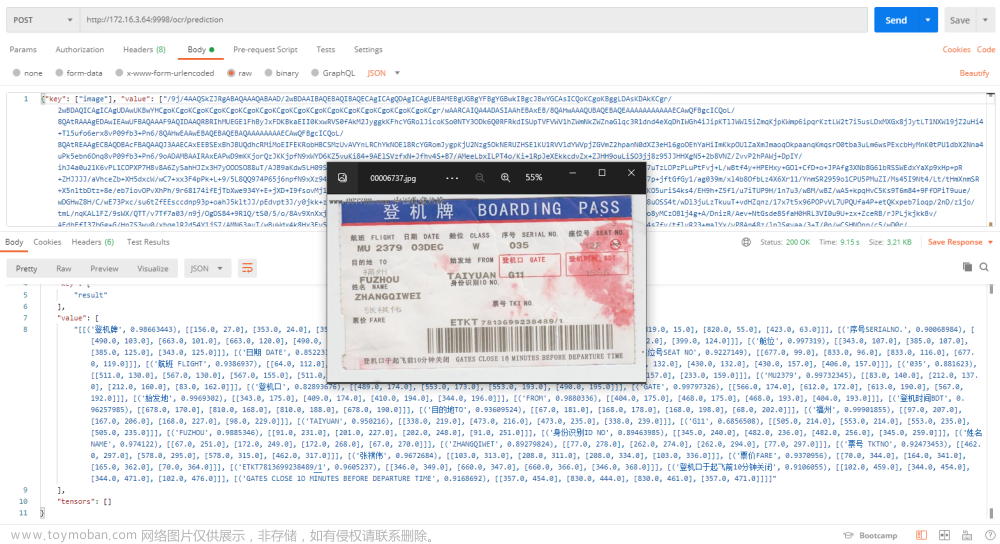
参数调整
调整 config.yml 中的并发个数获得最大的QPS, 一般检测和识别的并发数为2:1
det:
#并发数,is_thread_op=True时,为线程并发;否则为进程并发
concurrency: 8
...
rec:
#并发数,is_thread_op=True时,为线程并发;否则为进程并发
concurrency: 4
...
预测性能数据会被自动写入 PipelineServingLogs/pipeline.tracer 文件中。文章来源:https://www.toymoban.com/news/detail-465531.html
参考:https://gitee.com/paddlepaddle/PaddleOCR/tree/release/2.6/deploy/pdserving文章来源地址https://www.toymoban.com/news/detail-465531.html
到了这里,关于百度飞桨(PaddlePaddle) - PP-OCRv3 文字检测识别系统 基于 Paddle Serving快速使用(服务化部署 - CentOS 7)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!