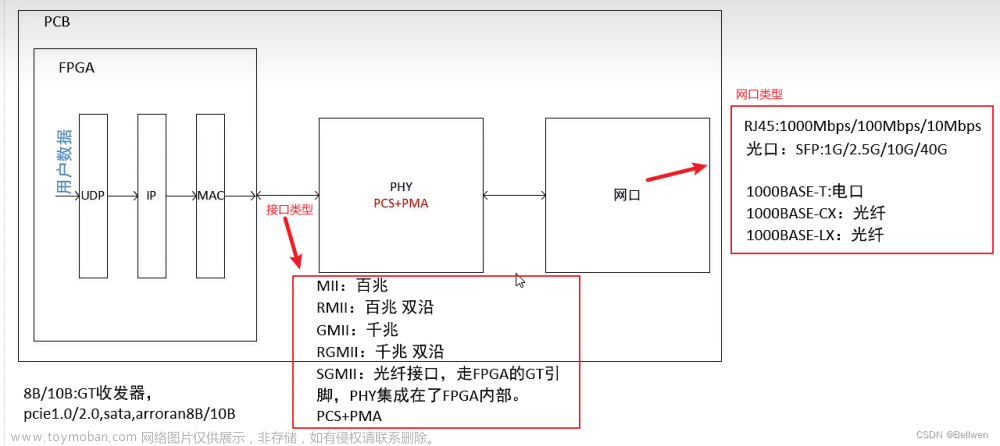
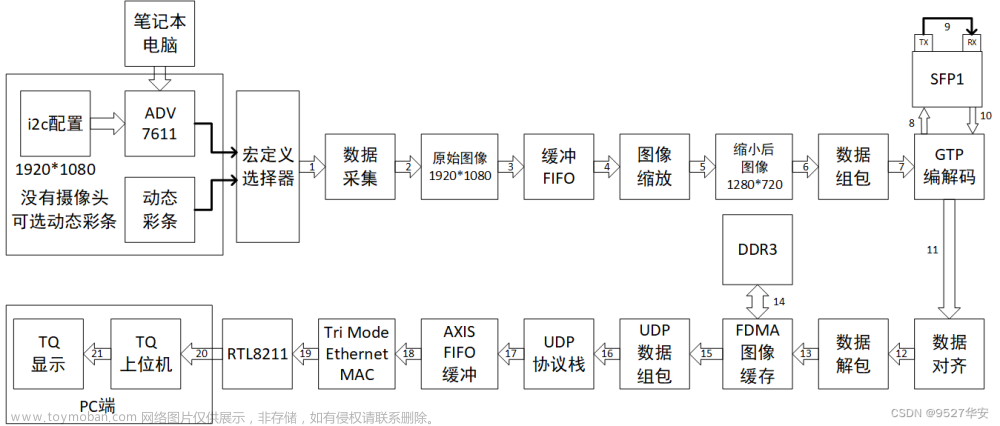
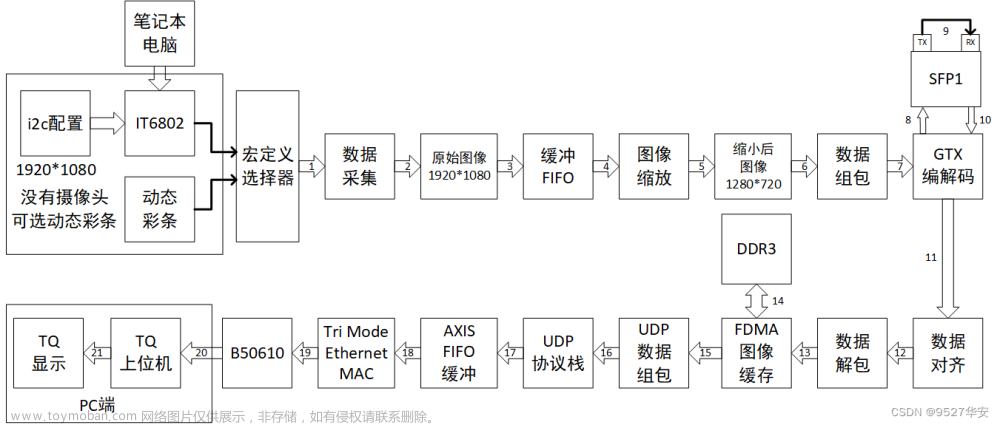
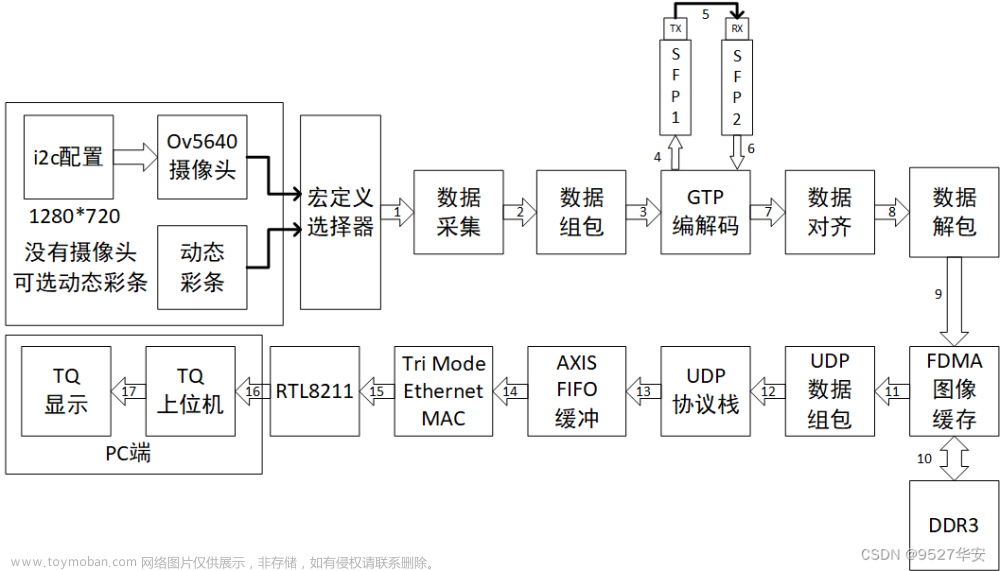
在 MAC 与 PHY 之间,有一个配置接口,即 MDIO(也称 SMI,Serial Management Interface),可以配置 PHY 的工作模式、获取 PHY 芯片的工作状态等。本文以 PHY 芯片 B50610 为例,实现 MDIO 接口,以实现对传输速度、接口类型的自协商。
MDIO 包含 2 根信号线:
- MDC,由 MAC 侧提供给 PHY 的时钟信号,最大 12.5MHz;
- MDIO,inout,数据线
MDIO 的通信协议如下

MDIO 的帧构成如下:
- Preamble,32 位前导码,MAC 端发送 32 位逻辑 1,以同步 PHY 芯片
- Start of Frame,帧开始信号,2’b01
- Operation Code,操作码,2‘b01 表示进行写操作,2’b10 表示读操作
- PHY Address,5 位 PHY 地址,用于决定和哪个 PHY 芯片通信
- Register Address,5 位寄存器地址,最大可表示 32 个寄存器
- Turn Around,2 位转向,在读操作中,MDIO 在此时由 MAC 驱动改为 PHY 驱动,在第一个 TA 位,MDIO 引脚为高阻状态,第二个 TA 位,PHY 将 MDIO 引脚拉低,准备发送数据,MAC 端此两位设为高阻,若 MAC 检测到第二位非低电平,表明对方无应答,可通过这个判断是否读取失败;在写操作中,不需要 MDIO 方向发生变化,MAC 固定输出 2’b10
- Data,16bit 数据
- IDLE,空闲状态下,一般将 MDIO 上拉
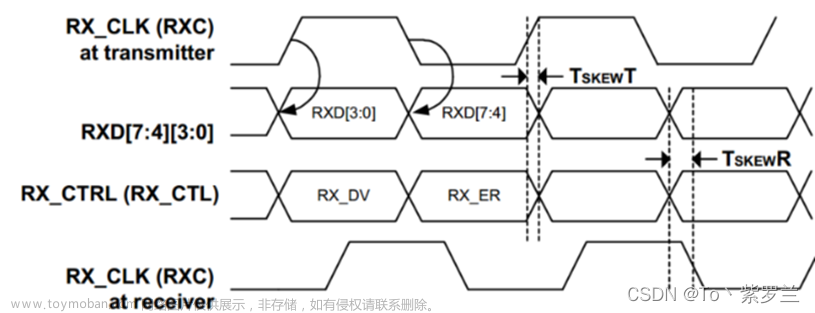
MDIO 的时序如下
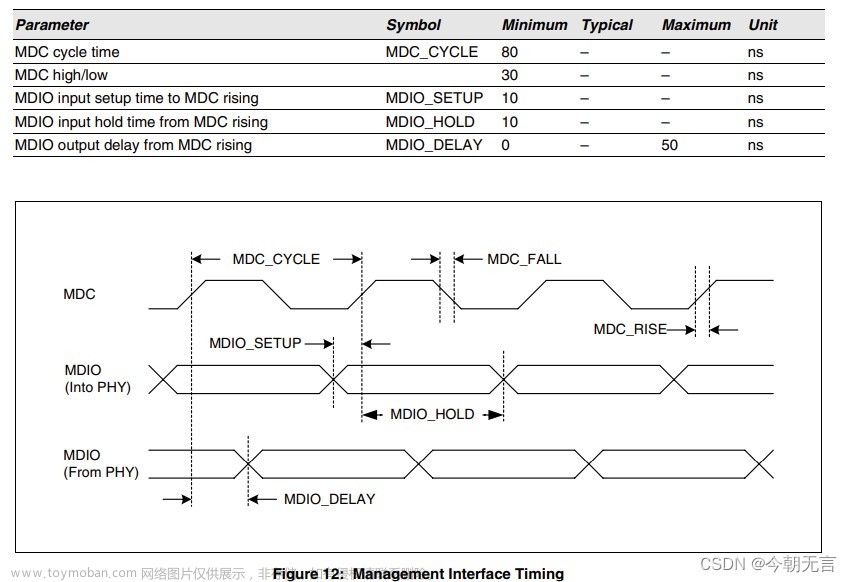
可以看到,PHY 芯片在 MDC 上升沿读取数据,并在上升沿给出数据。因此 MAC 端须在 MDC 下降沿给出数据,而读取数据在上升沿、下降沿均可(不过需要注意,由于 MDIO_DELAY 最大可达 50ns,若使用高于 10M 的 MDC 频率,则下降沿读取可能出现问题,因此推荐 MAC 侧在 MDC 上升沿读取数据)。
由于一次 MDIO 读写,均由 32bit 前导码,以及 32bit 读写比特流组成,因此可以方便地使用一个 5bit 计数器进行计数,然后根据当前的计数值操作 MDIO。Verilog 代码如下
/*
* file : smi_top.v
* author : 今朝无言
* date : 2023-05-31
* version : v2.0
* description : SMI(MDIO)Read/Write
*/
module smi_top(
input clk,
input rst_n,
output mdc,
inout mdio,
input [4:0] phy_addr,
input [4:0] reg_addr,
input [15:0] wrdata,
input write_req,
//req 信号上升沿有效,应维持至少一个 mdc 周期,可在检测到 busy 后再置低,下同
output reg [15:0] rddata,
input read_req,
output reg busy,
output reg rd_failed //对方无应答
);
parameter CLK_FREQ = 100_000_000;
parameter MDC_FREQ = 100_000;
clkdiv #(.N(CLK_FREQ/MDC_FREQ))
clkdiv_inst(
.clk_in (clk),
.clk_out (mdc)
);
reg mdio_buf;
reg link; //MAC是否占有MDIO控制权
assign mdio = link? mdio_buf : 1'bz;
//-----------------edge detect---------------------------
wire write_req_pe;
reg write_req_d0;
reg write_req_d1;
wire read_req_pe;
reg read_req_d0;
reg read_req_d1;
always @(posedge mdc) begin
write_req_d0 <= write_req;
write_req_d1 <= write_req_d0;
read_req_d0 <= read_req;
read_req_d1 <= read_req_d0;
end
assign write_req_pe = write_req_d0 & (~write_req_d1);
assign read_req_pe = read_req_d0 & (~read_req_d1);
//---------------------FSM-------------------------------
localparam S_IDLE = 8'h01;
localparam S_ARB = 8'h02;
localparam S_PRE_R = 8'h04;
localparam S_RD = 8'h08;
localparam S_PRE_W = 8'h10;
localparam S_WR = 8'h20;
localparam S_STOP = 8'h40;
localparam ST = 2'b01;
localparam R_OP = 2'b10;
localparam W_OP = 2'b01;
localparam W_TA = 2'b10;
reg [4:0] cnt; //一次读写正好 32bit Pre + 32bit WR/RD
reg [7:0] state = S_IDLE;
reg [7:0] next_state;
always @(posedge mdc or negedge rst_n) begin
if(~rst_n) begin
state <= S_IDLE;
end
else begin
state <= next_state;
end
end
always @(*) begin
case(state)
S_IDLE: begin
next_state <= S_ARB;
end
S_ARB: begin
if(write_req_pe) begin //写优先
next_state <= S_PRE_W;
end
else if(read_req_pe) begin
next_state <= S_PRE_R;
end
else begin
next_state <= S_ARB;
end
end
S_PRE_R: begin
if(cnt==5'd31) begin
next_state <= S_RD;
end
else begin
next_state <= S_PRE_R;
end
end
S_RD: begin
if(cnt==5'd31) begin
next_state <= S_STOP;
end
else begin
next_state <= S_RD;
end
end
S_PRE_W: begin
if(cnt==5'd31) begin
next_state <= S_WR;
end
else begin
next_state <= S_PRE_W;
end
end
S_WR: begin
if(cnt==5'd31) begin
next_state <= S_STOP;
end
else begin
next_state <= S_WR;
end
end
S_STOP: begin
next_state <= S_IDLE;
end
default: begin
next_state <= S_IDLE;
end
endcase
end
//cnt
always @(posedge mdc) begin
case(state)
S_IDLE: begin
cnt <= 5'd0;
end
S_PRE_R, S_RD, S_PRE_W, S_WR: begin
cnt <= cnt + 1'b1;
end
default: begin
cnt <= 5'd0;
end
endcase
end
//mdio_buf
always @(negedge mdc) begin //必须下降沿发送数据
case(state)
S_IDLE: begin
mdio_buf <= 1'b1;
end
S_PRE_R, S_PRE_W: begin
mdio_buf <= 1'b1;
end
S_WR: begin
case(cnt)
5'd0: mdio_buf <= ST[1];
5'd1: mdio_buf <= ST[0];
5'd2: mdio_buf <= W_OP[1];
5'd3: mdio_buf <= W_OP[0];
5'd4: mdio_buf <= phy_addr[4];
5'd5: mdio_buf <= phy_addr[3];
5'd6: mdio_buf <= phy_addr[2];
5'd7: mdio_buf <= phy_addr[1];
5'd8: mdio_buf <= phy_addr[0];
5'd9: mdio_buf <= reg_addr[4];
5'd10: mdio_buf <= reg_addr[3];
5'd11: mdio_buf <= reg_addr[2];
5'd12: mdio_buf <= reg_addr[1];
5'd13: mdio_buf <= reg_addr[0];
5'd14: mdio_buf <= W_TA[1];
5'd15: mdio_buf <= W_TA[0];
5'd16: mdio_buf <= wrdata[15];
5'd17: mdio_buf <= wrdata[14];
5'd18: mdio_buf <= wrdata[13];
5'd19: mdio_buf <= wrdata[12];
5'd20: mdio_buf <= wrdata[11];
5'd21: mdio_buf <= wrdata[10];
5'd22: mdio_buf <= wrdata[9];
5'd23: mdio_buf <= wrdata[8];
5'd24: mdio_buf <= wrdata[7];
5'd25: mdio_buf <= wrdata[6];
5'd26: mdio_buf <= wrdata[5];
5'd27: mdio_buf <= wrdata[4];
5'd28: mdio_buf <= wrdata[3];
5'd29: mdio_buf <= wrdata[2];
5'd30: mdio_buf <= wrdata[1];
5'd31: mdio_buf <= wrdata[0];
default: begin
mdio_buf <= 1'b1;
end
endcase
end
S_RD: begin
case(cnt)
5'd0: mdio_buf <= ST[1];
5'd1: mdio_buf <= ST[0];
5'd2: mdio_buf <= R_OP[1];
5'd3: mdio_buf <= R_OP[0];
5'd4: mdio_buf <= phy_addr[4];
5'd5: mdio_buf <= phy_addr[3];
5'd6: mdio_buf <= phy_addr[2];
5'd7: mdio_buf <= phy_addr[1];
5'd8: mdio_buf <= phy_addr[0];
5'd9: mdio_buf <= reg_addr[4];
5'd10: mdio_buf <= reg_addr[3];
5'd11: mdio_buf <= reg_addr[2];
5'd12: mdio_buf <= reg_addr[1];
5'd13: mdio_buf <= reg_addr[0];
default: begin
mdio_buf <= 1'b1;
end
endcase
end
default: begin
mdio_buf <= 1'b1;
end
endcase
end
//data_tmp
reg [15:0] data_tmp;
always @(posedge mdc) begin //在上升沿读数据
case(state)
S_RD: begin
case(cnt)
5'd15: rd_failed <= mdio; //若对方应答,此处会被拉低,否则失败
5'd16: data_tmp[15] <= mdio;
5'd17: data_tmp[14] <= mdio;
5'd18: data_tmp[13] <= mdio;
5'd19: data_tmp[12] <= mdio;
5'd20: data_tmp[11] <= mdio;
5'd21: data_tmp[10] <= mdio;
5'd22: data_tmp[9] <= mdio;
5'd23: data_tmp[8] <= mdio;
5'd24: data_tmp[7] <= mdio;
5'd25: data_tmp[6] <= mdio;
5'd26: data_tmp[5] <= mdio;
5'd27: data_tmp[4] <= mdio;
5'd28: data_tmp[3] <= mdio;
5'd29: data_tmp[2] <= mdio;
5'd30: data_tmp[1] <= mdio;
5'd31: data_tmp[0] <= mdio;
default: begin
data_tmp <= data_tmp;
end
endcase
end
default: begin
data_tmp <= data_tmp;
end
endcase
end
//rddata
always @(posedge mdc) begin
case(state)
S_STOP: begin
rddata <= data_tmp;
end
default: begin
rddata <= rddata;
end
endcase
end
//link
always @(posedge mdc) begin
case(state)
S_PRE_W, S_PRE_R, S_WR: begin
link <= 1'b1;
end
S_RD: begin
if(cnt<=13) begin
link <= 1'b1;
end
else begin
link <= 1'b0;
end
end
default: begin
link <= 1'b0;
end
endcase
end
//busy
always @(posedge mdc) begin
case(state)
S_IDLE, S_ARB: begin
busy <= 1'b0;
end
S_PRE_R, S_RD, S_PRE_W, S_WR, S_STOP: begin
busy <= 1'b1;
end
default: begin
busy <= busy;
end
endcase
end
endmodule
测试
B50610 的 PHY 地址通过 PHYA0、TEST3、TEST2 三个引脚进行配置

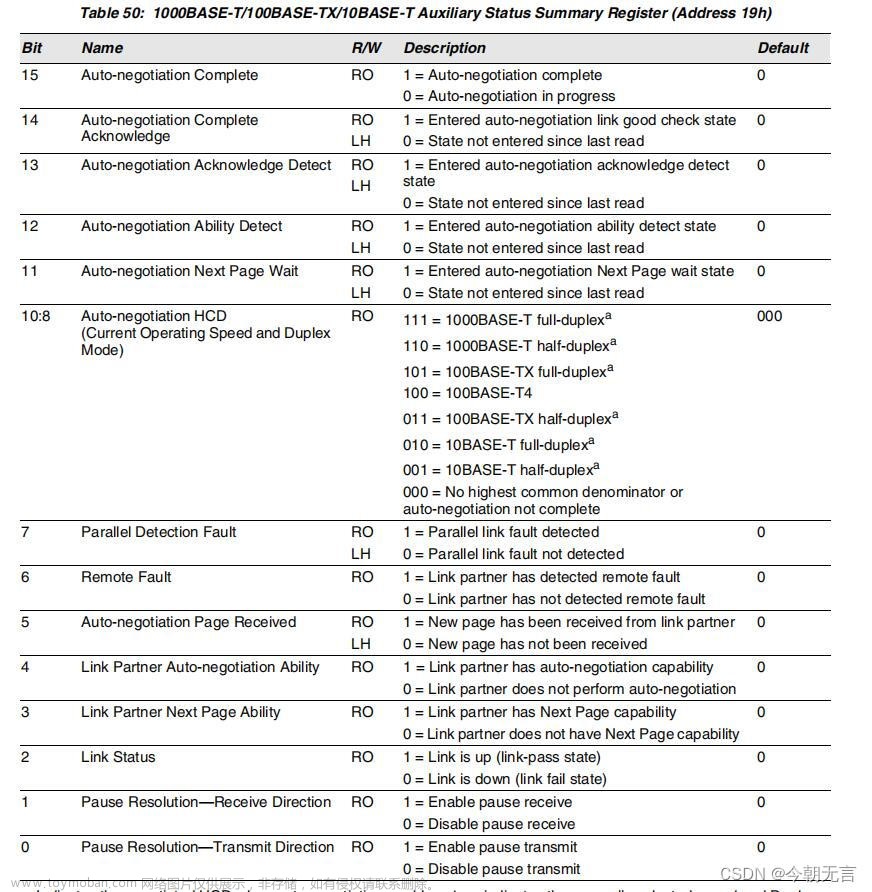
比如我们想查看下网络是否连接、当前操作速度等信息,可以查看 Auxiliary Status Summary Register 寄存器,地址 0x19。各比特含义如下
测试代码略.
连接路由器(100BASE)后:
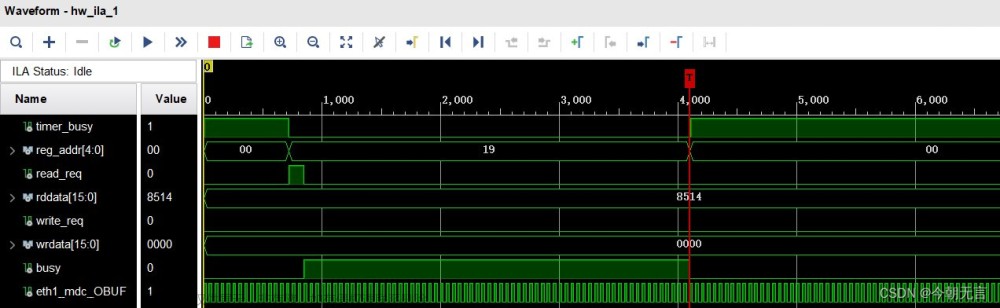
可以看到网络已连接(bit2=1),自协商已完成(bit15=1),当前网速 100M 全双工(bit10:8=0b101)。
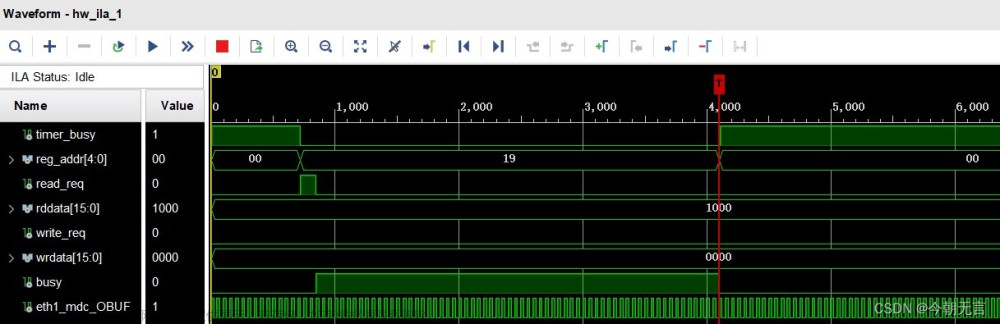
拔掉网线:
 文章来源:https://www.toymoban.com/news/detail-561600.html
文章来源:https://www.toymoban.com/news/detail-561600.html
可以检测到网络断开(bit2=0),正在自协商过程中(bit15=0)。文章来源地址https://www.toymoban.com/news/detail-561600.html
到了这里,关于以太网——MDIO(SMI)接口的FPGA实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!