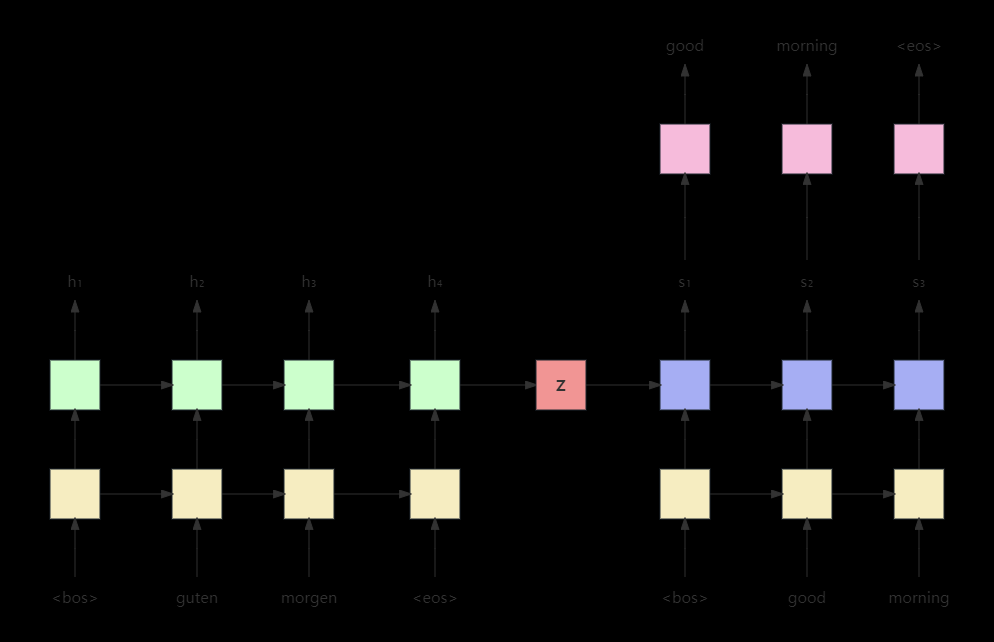
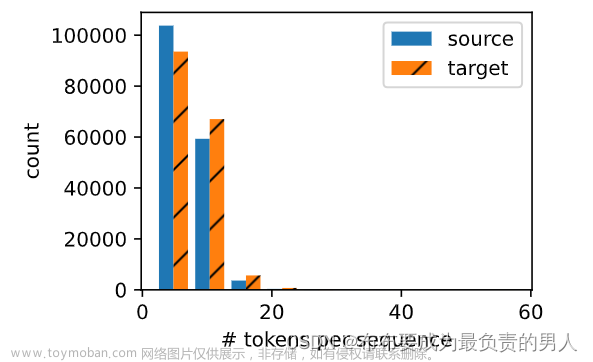
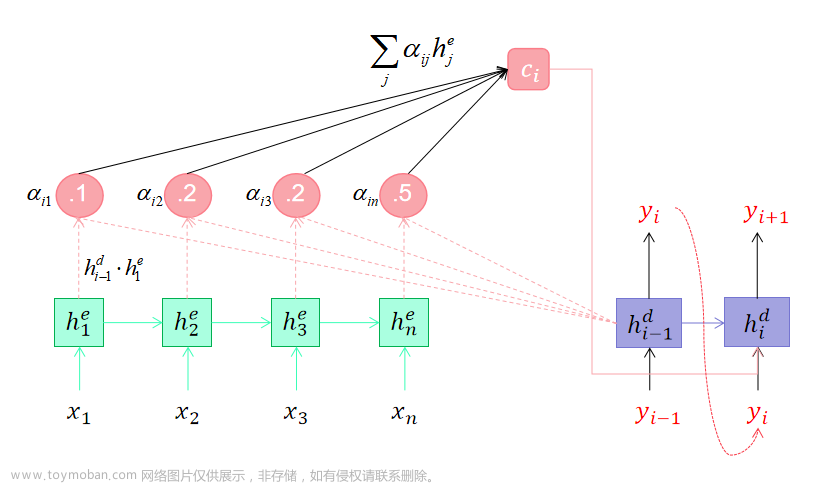
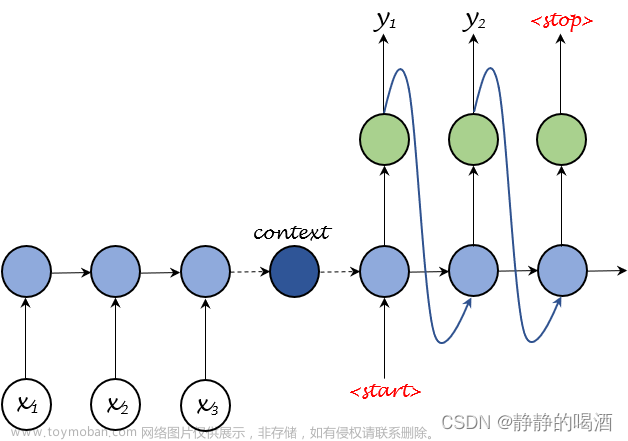
文章来源:https://www.toymoban.com/news/detail-647485.html
文章来源:https://www.toymoban.com/news/detail-647485.html
💥项目专栏:【深度学习时间序列预测案例】零基础入门经典深度学习时间序列预测项目实战(附代码+数据集+原理介绍)文章来源地址https://www.toymoban.com/news/detail-647485.html
到了这里,关于LSTM实现多变量输入多步预测(Seq2Seq多步预测)时间序列预测(PyTorch版)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!