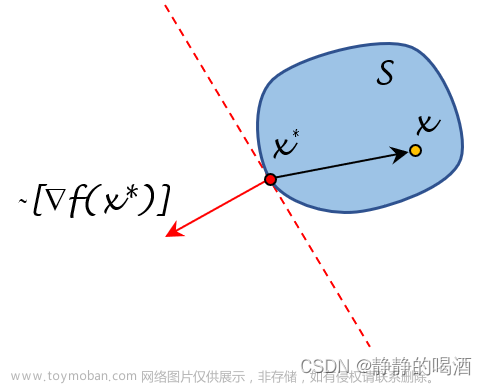
3.10 K-均值聚类
聚类分析是 统计学中的一个基本问题,其在机器学习,数据挖掘,模式识别和图像分析中有着重要应用。聚类不同于分类,在聚类问题中我们仅仅知道数据点本身,而不知道每个数据点具体的标签。聚类分析的任务就是将一些无标签的数据点按照某种相似度来进行归类,进而从数据点本身来学习其内蕴的类别特征。
给定
p
p
p维空间中的
n
n
n个数据点
a
1
,
a
2
,
⋯
,
a
n
a_1,a_2,\cdots,a_n
a1,a2,⋯,an,假定两个数据点之间的相似性可以通过其欧几里得距离来测量,我们的目标是将相似的点归为一类,同时将不相似的点区分开,为了简单起来我们假设类的个数为已知的,不妨记为
k
k
k,且同一个数据点只属于一个类,因此聚类问题就是要找
k
k
k个不相交的非空集合
S
1
,
S
2
,
⋯
,
S
k
S_1,S_2,\cdots,S_k
S1,S2,⋯,Sk,使得
{
a
1
,
a
2
,
⋯
,
a
n
}
=
S
1
∪
S
2
∪
⋯
∪
S
k
\{a_1,a_2,\cdots,a_n\}=S_1\cup{S_2}\cup{\cdots}\cup{S_k}
{a1,a2,⋯,an}=S1∪S2∪⋯∪Sk
且同类点之间的距离要足够近,为了在数学上描述"同类点之间的距离足够近",我们定义组内距离平方和为
W
(
S
1
,
S
2
,
⋯
,
S
k
)
=
∑
i
=
1
k
∑
a
∈
S
i
∣
∣
a
−
c
i
∣
∣
2
(3.10.1)
W(S_1,S_2,\cdots,S_k)=\sum_{i=1}^k\sum_{a{\in}S_i}||a-c_i||^2 \tag{3.10.1}
W(S1,S2,⋯,Sk)=i=1∑ka∈Si∑∣∣a−ci∣∣2(3.10.1)
这里
c
i
c_i
ci为第
i
i
i类数据点的中心,注意在问题中就假设了每类为非空的
定义好聚类标准后,就可以建议优化模型了。我们想要找到一个聚类方法,使得组内距离平方和最小,即
min
S
1
,
S
2
,
⋯
,
S
k
∑
i
=
1
k
∑
a
∈
S
i
∣
∣
a
−
c
i
∣
∣
2
s
.
t
.
{
a
1
,
a
2
,
⋯
,
a
n
}
=
S
1
∪
S
2
∪
⋯
∪
S
k
S
j
∩
S
j
≠
∅
,
∀
i
≠
j
(3.10.2)
\min_{S_1,S_2,\cdots,S_k}\sum_{i=1}^k\sum_{a{\in}S_i}||a-c_i||^2 \\ s.t. {\quad} \{a_1,a_2,\cdots,a_n\}=S_1\cup{S_2}\cup{\cdots}\cup{S_k} \\ S_j \cap S_j {\not=}\varnothing,\forall{i {\not=}j} \tag{3.10.2}
S1,S2,⋯,Skmini=1∑ka∈Si∑∣∣a−ci∣∣2s.t.{a1,a2,⋯,an}=S1∪S2∪⋯∪SkSj∩Sj=∅,∀i=j(3.10.2)
问题(3.10.2)的自变量是数据点集合的分割方式,看起来比较难以处理,因此有必要将问题写成我们熟悉的形式,接下来给出问题的两种矩阵表达方式,它们之间是等价的。
1. K-均值聚类等价表述一
在原始聚类问题中,组内距离平方和定义为(3.10.1),即需要计算
S
i
S_i
Si中的点到它们中心点
c
i
c_i
ci的平方和,实际上,选取中心点
c
i
c_i
ci作为参考点并不是必须的,我们完全可以选取其他点
h
i
h_i
hi来作为参照来计算组内距离(其实这个
h
i
h_i
hi通过优化最后也是表示的中心点),因此组内距离平方和可以推广为
W
(
S
1
,
S
2
,
⋯
,
S
k
,
H
)
=
∑
i
=
1
k
∑
a
∈
S
i
∣
∣
a
−
h
i
∣
∣
2
W(S_1,S_2,\cdots,S_k,H)=\sum_{i=1}^k\sum_{a{\in}S_i}||a-h_i||^2
W(S1,S2,⋯,Sk,H)=i=1∑ka∈Si∑∣∣a−hi∣∣2
其中
H
∈
R
k
×
p
H{\in}R^{k \times p}
H∈Rk×p(k个类的一个点(维度为p))且第
i
i
i行的向量为
h
i
T
h_i^T
hiT,为了表示聚类方式
S
1
,
S
2
,
⋯
,
S
k
S_1,S_2,\cdots,S_k
S1,S2,⋯,Sk,一个很自然的想法是使用一个向量
ϕ
i
∈
R
k
{\phi_i}{\in}R^k
ϕi∈Rk来表示
a
i
a_i
ai所处的类别
(
ϕ
i
)
j
=
{
1
,
a
i
∈
S
j
0
,
a
i
∉
S
j
{(\phi_i)}_j=\left\{ \begin{matrix} 1,a_i{\in}S_j \\ 0,a_i{\notin}S_j \end{matrix} \right.
(ϕi)j={1,ai∈Sj0,ai∈/Sj
聚类问题等价描述为
min
ϕ
,
H
∣
∣
A
−
Φ
H
∣
∣
F
2
s
.
t
.
Φ
∈
R
n
×
k
,每一行只有一个元素为
1
,其余为
0
H
∈
R
k
×
p
(3.10.3)
\min_{\phi,H}||A-{\Phi}H||_F^2 \\ s.t. {\quad}{\Phi}{\in}R^{n \times k},每一行只有一个元素为1,其余为0 \\ H{\in}R^{k \times p}\tag{3.10.3}
ϕ,Hmin∣∣A−ΦH∣∣F2s.t.Φ∈Rn×k,每一行只有一个元素为1,其余为0H∈Rk×p(3.10.3)
这里的
Φ
{\Phi}
Φ的第
i
i
i行的向量就是
ϕ
i
T
{\phi}_i^T
ϕiT
接下来说明3.10.3和原问题3.10.2是等价的,为此只需要说明参考点集
H
H
H的取法实际上就是每一类的中点,当固定
P
h
i
Phi
Phi时,第
i
i
i类点的组内距离平方和为
∑
a
∈
S
i
∣
∣
a
−
h
i
∣
∣
2
\sum_{a{\in}S_i}||a-h_i||^2
a∈Si∑∣∣a−hi∣∣2
根据二次函数的性质,当
h
i
=
1
n
∑
a
∈
S
i
a
h_i=\frac{1}{n}{\sum_{a{\in}S_i}}a
hi=n1∑a∈Sia时,组内距离平方和最小
所以
h
i
h_i
hi一定会被优化成第
i
i
i类的中心点的
我们引入问题(3.10.3)的理由有两个
(1)形式简洁,且将不易处理的自变量“分割方式”转化为矩阵
(2)可以看成是一个矩阵分解问题,便于我们设计算法
2.K-均值聚类等价表述二
K-均值聚类的第二种等价表述利用了列正交矩阵的性质,这种表达方式比问题(3.10.3)相比更为简洁,首先定义
I
S
t
,
1
≤
t
≤
k
I_{S_t},1{\le}t{\le}k
ISt,1≤t≤k为
n
n
n维空间中每个分量取值0或1的向量,且
I
S
j
(
i
)
=
{
1
,
a
i
∈
S
t
0
,
a
i
∉
S
t
I_{S_j}(i)=\left\{ \begin{matrix} 1,a_i{\in}S_t \\ 0,a_i{\notin}S_t \end{matrix} \right.
ISj(i)={1,ai∈St0,ai∈/St
可以证明,第
t
t
t类
S
t
S_t
St中每个点到其中心点的距离平方和可以写成
1
2
n
t
T
r
(
D
I
S
t
I
S
t
T
)
\frac{1}{2n_t}Tr(DI_{S_t}I_{S_t}^T)
2nt1Tr(DIStIStT),其中
D
∈
R
n
×
n
D{\in}R^{n \times n}
D∈Rn×n的元素为
D
i
j
=
∣
∣
a
i
−
a
j
∣
∣
2
D_{ij}=||a_i-a_j||^2
Dij=∣∣ai−aj∣∣2。这说明
S
t
S_t
St中每个点到中心点的距离平方和与
S
t
S_t
St中所有点两两之间距离平方和有关,因此,我们将问题(3.10.2)转化为
min
S
1
,
S
2
,
⋯
,
S
k
1
2
T
r
(
D
X
)
s
.
t
.
X
=
∑
t
=
1
k
1
n
t
I
S
t
I
S
t
T
S
1
∪
S
2
∪
⋯
∪
S
k
=
{
a
1
,
a
2
,
⋯
,
a
n
}
S
i
∩
S
j
=
∅
,
∀
i
≠
j
(3.10.4)
\min_{S_1,S_2,\cdots,S_k}\frac{1}{2}Tr(DX) \\ s.t. {\quad}X={\sum}_{t=1}^k\frac{1}{n_t}I_{S_t}I_{S_t}^T \\ S_1{\cup}S_2{\cup}\cdots{\cup}S_k=\{a_1,a_2,\cdots,a_n\} \\ S_i{\cap}S_j={\varnothing},\forall{i{\not=}j}\tag{3.10.4}
S1,S2,⋯,Skmin21Tr(DX)s.t.X=∑t=1knt1IStIStTS1∪S2∪⋯∪Sk={a1,a2,⋯,an}Si∩Sj=∅,∀i=j(3.10.4)
对半正定举证
X
X
X进行分解
X
=
Y
Y
T
,
Y
∈
R
n
×
k
X=YY^T,Y{\in}R^{n \times k}
X=YYT,Y∈Rn×k,我们可以进一步得到如下矩阵优化问题(这里
I
I
I是
n
n
n维向量且分量全为1)
min
Y
∈
R
n
×
k
T
r
(
Y
T
D
Y
)
s
.
t
.
Y
Y
T
I
=
I
,
Y
Y
T
=
I
k
,
Y
≥
0
(3.10.5)
\min_{Y{\in}R^{n \times k}}Tr(Y^TDY) \\ s.t.{\quad}YY^TI=I, \\ YY^T=I_k,Y{\ge}0\tag{3.10.5}
Y∈Rn×kminTr(YTDY)s.t.YYTI=I,YYT=Ik,Y≥0(3.10.5)
求得3.10.5的解
Y
Y
T
YY^T
YYT就对应(3.10.4)的解(说实话这一块我没看懂,Kmeans直接去做的话还是蛮简单的)
3.11 图像处理中的全变差模型
这一块可能需要对图像处理有基础的同学才好看懂,反正我目前是看的云里雾里
简要介绍一下基于全变差(TV)的图像处理模型,对于定义在区域
Ω
⊂
R
2
{\Omega}\subset{R^2}
Ω⊂R2的函数
u
(
x
,
y
)
u(x,y)
u(x,y),其全变差
∣
∣
u
∣
∣
T
V
=
∫
Ω
∣
∣
D
u
∣
∣
d
x
(3.11.1)
||u||_{TV}=\int_{\Omega}||Du||dx\tag{3.11.1}
∣∣u∣∣TV=∫Ω∣∣Du∣∣dx(3.11.1)
其中梯度算子
D
D
D满足:
D
u
=
(
∂
u
∂
x
,
∂
u
∂
y
)
Du=(\frac{\partial{u}}{\partial{x}},\frac{\partial{u}}{\partial{y}})
Du=(∂x∂u,∂y∂u)
这里,
∣
∣
D
u
∣
∣
||Du||
∣∣Du∣∣可以采用
l
1
l_1
l1范数,即
∣
∣
D
u
∣
∣
1
=
∣
∂
u
∂
x
∣
+
∣
∂
u
∂
y
∣
||Du||_1=|\frac{\partial{u}}{\partial{x}}|+|\frac{\partial{u}}{\partial{y}}|
∣∣Du∣∣1=∣∂x∂u∣+∣∂y∂u∣
称对应的全变差是各向异性的
如果采用
l
2
l_2
l2范数,即
∣
∣
D
u
∣
∣
2
=
(
∂
u
∂
x
)
2
+
(
∂
u
∂
y
)
2
||Du||_2=\sqrt{(\frac{\partial{u}}{\partial{x}})^2+({\frac{\partial{u}}{\partial{y}})^2}}
∣∣Du∣∣2=(∂x∂u)2+(∂y∂u)2
称对应的全变差是各向同性的。
令
b
(
x
,
y
)
b(x,y)
b(x,y)是观测到的带噪声的图像,
A
A
A是线性算子,在经典的
R
u
d
i
n
−
O
s
h
e
r
−
F
a
t
e
m
i
(
R
O
F
)
Rudin-Osher-Fatemi(ROF)
Rudin−Osher−Fatemi(ROF)模型下,图像去噪和去模糊问题可以写成
min
u
∣
∣
A
u
−
b
∣
∣
L
2
2
+
λ
∣
∣
u
∣
∣
T
V
(3.11.2)
\min_u||Au-b||_{L2}^2+{\lambda}||u||_{TV}\tag{3.11.2}
umin∣∣Au−b∣∣L22+λ∣∣u∣∣TV(3.11.2)
这里,定义域为
Ω
\Omega
Ω的函数
f
f
f的
L
2
L_2
L2范数定义为
∣
∣
f
∣
∣
L
2
=
(
∫
Ω
f
2
d
x
)
1
2
||f||_{L2}=(\int_{\Omega}f^2dx)^{\frac{1}{2}}
∣∣f∣∣L2=(∫Ωf2dx)21
如果
A
A
A是单位算子或模糊算子,则上述模型分别对应图像去噪和去模糊,目标函数第一项是数据保真项,即重构出的照片要与已有的采集信息相容。第二项是正则项,用来保证重构出的图像的阶跃是稀疏的,或者说使得重构出的图像类似于一个分片常数函数。
下面给出连续模型(3.11.2)的离散格式,为简单起见,假设区域
Ω
=
[
0
,
1
]
×
[
0
,
1
]
\Omega=[0,1] \times [0,1]
Ω=[0,1]×[0,1]并且将它离散为
n
×
n
n \times n
n×n的网格,则格点
(
i
n
,
j
n
)
(\frac{i}{n},\frac{j}{n})
(ni,nj)对应指标
(
i
,
j
)
(i,j)
(i,j),我们将图像
u
u
u表示矩阵
U
∈
R
n
×
n
U{\in}R^{n \times n}
U∈Rn×n,其元素
u
i
,
j
u_{i,j}
ui,j对应指标
(
i
,
j
)
(i,j)
(i,j)运用前向差分离散梯度算子
D
D
D得到
(
D
U
)
i
,
j
=
(
(
D
1
U
)
i
,
j
,
(
D
2
U
)
i
,
j
)
(DU)_{i,j}=((D_1U)_{i,j},(D_2U)_{i,j})
(DU)i,j=((D1U)i,j,(D2U)i,j),且有
(
D
1
U
)
i
,
j
=
{
u
i
+
1
,
j
−
u
i
,
j
,
i
<
n
0
,
i
=
n
(D_1U)_{i,j}=\left\{ \begin{matrix} u_{i+1,j}-u_{i,j},i<n \\ 0,i=n \end{matrix} \right.
(D1U)i,j={ui+1,j−ui,j,i<n0,i=n
(
D
2
U
)
i
,
j
=
{
u
i
,
j
+
1
−
u
i
,
j
,
j
<
n
0
,
j
=
n
(D_2U)_{i,j}=\left\{ \begin{matrix} u_{i,j+1}-u_{i,j},j<n \\ 0,j=n \end{matrix} \right.
(D2U)i,j={ui,j+1−ui,j,j<n0,j=n
这里对于
i
,
j
=
n
i,j=n
i,j=n的点使用诺依曼边界条件
∂
u
∂
n
=
0
\frac{\partial{u}}{\partial{n}}=0
∂n∂u=0且有
D
U
∈
R
n
×
n
×
2
DU{\in}R^{n \times n \times 2}
DU∈Rn×n×2那么离散全变差可以定义为
∣
∣
U
∣
∣
T
V
=
∑
i
≤
i
,
j
≤
n
∣
∣
(
D
U
)
i
,
j
∣
∣
(3.11.3)
||U||_{TV}=\sum_{i{\le}i,j{\le}n}||(DU)_{i,j}||\tag{3.11.3}
∣∣U∣∣TV=i≤i,j≤n∑∣∣(DU)i,j∣∣(3.11.3)
其中
∣
∣
⋅
∣
∣
||·||
∣∣⋅∣∣可以是
l
1
l_1
l1或
l
2
l_2
l2范数
对于任意的
U
,
V
∈
R
n
×
n
×
2
U,V{\in}R^{n \times n \times 2}
U,V∈Rn×n×2,我们定义内积
<
U
,
V
>
=
∑
1
≤
i
,
j
≤
n
,
1
≤
k
≤
2
u
i
,
j
,
k
v
i
,
j
,
k
<U,V>={\sum_{1{\le}i,j{\le}n,1{\le}k{\le}2}}u_{i,j,k}v_{i,j,k}
<U,V>=1≤i,j≤n,1≤k≤2∑ui,j,kvi,j,k
那么根据定义,离散的散度算子
G
G
G需满足
<
U
,
G
V
>
=
−
<
D
U
,
V
>
,
∀
U
∈
R
n
×
n
,
V
∈
R
n
×
n
×
2
<U,GV>=-<DU,V>,\forall{U}{\in}R^{n \times n},V{\in}R^{n \times n \times 2}
<U,GV>=−<DU,V>,∀U∈Rn×n,V∈Rn×n×2
(这里散度算子干嘛的我也不太清楚)
记
w
i
j
=
(
w
i
,
j
,
1
,
w
i
,
j
,
2
)
T
,
W
=
(
w
i
j
)
i
,
j
=
1
n
∈
R
n
×
n
×
2
w_{ij}=(w_{i,j,1},w_{i,j,2})^T,W=(w_{ij})_{i,j=1}^n{\in}R^{n \times n \times 2}
wij=(wi,j,1,wi,j,2)T,W=(wij)i,j=1n∈Rn×n×2
我们有
(
G
W
)
i
j
=
Δ
i
,
j
,
1
+
Δ
i
,
j
,
2
(3.11.4)
(GW)_{ij}={\Delta_{i,j,1}}+{\Delta}_{i,j,2}\tag{3.11.4}
(GW)ij=Δi,j,1+Δi,j,2(3.11.4)
其中
Δ
i
,
j
,
1
=
{
w
i
,
j
,
1
−
w
i
−
1
,
j
,
1
,
1
<
i
<
n
w
i
,
j
,
1
,
i
=
1
−
w
i
,
j
,
1
,
i
=
n
{\Delta_{i,j,1}}=\left\{ \begin{matrix} w_{i,j,1}-w_{i-1,j,1},1<i<n \\ w_{i,j,1},i=1 \\ -w_{i,j,1},i=n \end{matrix} \right.
Δi,j,1=⎩
⎨
⎧wi,j,1−wi−1,j,1,1<i<nwi,j,1,i=1−wi,j,1,i=n
Δ
i
,
j
,
2
=
{
w
i
,
j
,
1
−
w
i
,
j
−
1
,
1
,
1
<
j
<
n
w
i
,
j
,
1
,
j
=
1
−
w
i
,
j
,
1
,
j
=
n
{\Delta_{i,j,2}}=\left\{ \begin{matrix} w_{i,j,1}-w_{i,j-1,1},1<j<n \\ w_{i,j,1},j=1 \\ -w_{i,j,1},j=n \end{matrix} \right.
Δi,j,2=⎩
⎨
⎧wi,j,1−wi,j−1,1,1<j<nwi,j,1,j=1−wi,j,1,j=n
运用合适的离散格式处理后,我们可得到离散的线性算子
A
A
A和图像
B
B
B(这里运用了连续情形的记号,但
A
A
A的含义完全不同),因此由连续问题得到离散问题
min
U
∈
R
n
×
n
∣
∣
A
U
−
B
∣
∣
F
2
+
λ
∣
∣
U
∣
∣
T
V
(3.11.5)
\min_{U{\in}R^{n \times n}}||AU-B||_F^2+\lambda||U||_{TV}\tag{3.11.5}
U∈Rn×nmin∣∣AU−B∣∣F2+λ∣∣U∣∣TV(3.11.5)
在实际中,除了考虑
R
O
F
ROF
ROF模型外,我们还考虑其一个变形,
T
V
−
L
1
TV-L^1
TV−L1模型,离散格式为
min
U
∈
R
n
×
n
∣
∣
A
U
−
B
∣
∣
1
+
λ
∣
∣
U
∣
∣
T
V
(3.11.6)
\min_{U{\in}R^{n \times n}}||AU-B||_1+\lambda||U||_{TV}\tag{3.11.6}
U∈Rn×nmin∣∣AU−B∣∣1+λ∣∣U∣∣TV(3.11.6)
上述模型的一个好处是可以更好地处理非高斯噪声的情形,比如椒盐噪声等等
3.12 小波模型
书上写的小波模型才抽象了,很多变量没告诉什么意思就直接说了,这里直接跳过了。。以后要是用到了再去细看
3.13 强化学习
A
l
p
h
a
G
o
Z
e
r
o
AlphaGo Zero
AlphaGoZero就采用了强化学习,他只需要掌握围棋的基本规则,不需要任何的人类经验,就能从零开始学习。
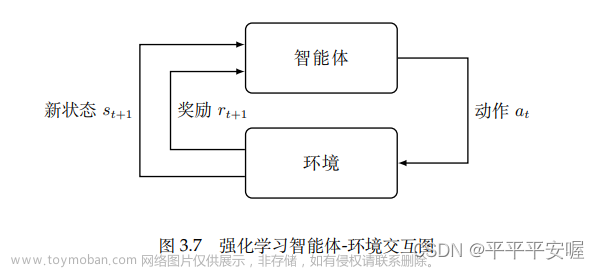
虽然强化学习处理的实际问题千差万别,但是他们一般可以抽象出智能体(agent)和环境(environment)两个概念,智能体持续地与环境互动并从环境中学到经验和规则。如图3.7所示,智能体在状态
s
t
s_t
st下执行动作
a
t
a_t
at后,环境根据其内在的规则回应,到达新的状态
s
t
+
1
s_{t+1}
st+1,奖励
r
t
+
1
r_{t+1}
rt+1,这个系统不断地重复这个过程,直到系统终止。想象一个机器人从A走到B,为了实现这个目标,它尝试了很多不同的移动方式,既从成功的动作中学到了经验,又从失败的摔倒中学到了教训,最终得到最有效,最快捷的行走方式,这种反复试错也是强化学习所使用的思想。强化学习跟其他机器学习相比有如下不同点:
(1)这个过程是无监督的,没有标签告诉智能体做什么动作是最好的,,只有之前动作所获得的奖励会让智能体更偏向于执行某一类动作
(2)环境给智能体动作反馈是有延迟的,当前动作的效果也许不会立刻体现,但是它可能影响许多步后的奖励
(3)时间顺序在强化学习中是非常重要的,所做决策的顺序会决定最终的结果
(4)智能体所做的动作会影响观察到的环境状态,在这个学习过程中观察到的环境状态或接受到的反馈不是独立的,它们是智能体动作的函数,这一点与监督学习中的样本独立性假设有很大差别
强化学习经常可以用马尔可夫决策过程(MDP)来描述,在马尔可夫决策过程中,环境状态转移的概率只取决于当前的状态和动作,而与所有历史信息无关,即
P
(
s
t
+
1
=
s
′
∣
s
t
,
a
t
,
⋯
,
s
0
,
a
0
)
=
P
(
s
t
+
1
=
s
′
∣
s
t
,
a
t
)
P(s_{t+1}=s'|s_t,a_t,\cdots,s_0,a_0)=P(s_{t+1}=s'|s_{t},a_t)
P(st+1=s′∣st,at,⋯,s0,a0)=P(st+1=s′∣st,at)
其次,环境所反馈的奖励的期望也只依赖于当前的状态和动作,所以该期望可以表示成
E
[
r
t
+
1
∣
s
t
,
a
t
,
⋯
,
s
0
,
a
0
]
=
E
[
r
t
+
1
∣
s
t
=
s
,
a
t
=
a
]
=
r
(
s
,
a
)
E[r_{t+1}|s_t,a_t,\cdots,s_0,a_0]=E[r_{t+1}|s_t=s,a_t=a]=r(s,a)
E[rt+1∣st,at,⋯,s0,a0]=E[rt+1∣st=s,at=a]=r(s,a)
智能体要做的是通过在环境中不断尝试学习得到一个策略(policy)
π
\pi
π,根据这个策略,智能体可以知道在状态
s
s
s下该执行什么动作,假设
S
S
S和
A
A
A是正整数,令
S
=
{
1
,
2
,
⋯
,
S
}
S=\{1,2,\cdots,S\}
S={1,2,⋯,S}和
A
=
{
1
,
2
,
⋯
,
A
}
A=\{1,2,\cdots,A\}
A={1,2,⋯,A}分别为状态空间和决策空间。用
Δ
X
\Delta_X
ΔX来表示在集合
X
X
X上的概率分布构成的集合。策略
π
:
S
→
Δ
X
\pi:S{\rightarrow}\Delta_X
π:S→ΔX是定义在状态空间上的一个映射,我们用
π
(
a
∣
s
)
\pi(a|s)
π(a∣s)表示使用策略
π
\pi
π时,在当前状态
s
s
s下选择策略
a
a
a的概率。状态转移算子
P
:
S
×
A
→
Δ
X
P:S \times A{\rightarrow}{\Delta}_X
P:S×A→ΔX为状态空间和决策空间的乘积空间到状态空间上的概率分布的映射(在当前状态做某个动作导致到下一个状态的概率)用
P
a
(
i
,
j
)
P_a(i,j)
Pa(i,j)表示采用决策
i
i
i跳到决策
j
j
j的概率。令单步奖励函数
r
:
S
×
A
→
R
r:S \times A{\rightarrow}R
r:S×A→R为状态和决策乘积空间上的实值函数,用
r
(
s
,
a
)
r(s,a)
r(s,a)表示在状态
s
s
s下采用决策
a
a
a得到的奖励的期望。
由于在某一个状态下最优的动作选择并不一定产生全局最优的策略。比较理想的方式应该能最大化某种形式的累计奖励。例如有限时间的累计奖励,或是有限时间的有折扣奖励之和,亦或者是无限时间的累计奖励或平均奖励,一条轨道
τ
\tau
τ是一系列的状态和动作的集合
τ
=
{
s
0
,
a
0
,
s
1
,
a
1
,
⋯
}
\tau=\{s_0,a_0,s_1,a_1,\cdots\}
τ={s0,a0,s1,a1,⋯}
给定折扣因子
γ
∈
[
0
,
1
)
\gamma{\in}[0,1)
γ∈[0,1),有折扣累计奖励可以表示为
R
(
τ
)
=
∑
t
=
0
∞
γ
′
r
t
R(\tau)=\sum_{t=0}^{\infty}\gamma'r_t
R(τ)=t=0∑∞γ′rt
其中
r
t
=
r
(
s
t
,
a
t
)
r_t=r(s_t,a_t)
rt=r(st,at),那么最优的策略是能最大化MDP收益的策略:
max
π
E
τ
∼
π
[
R
(
τ
)
]
(3.13.1)
\max_{\pi}E_{\tau\sim\pi}[R(\tau)]\tag{3.13.1}
πmaxEτ∼π[R(τ)](3.13.1)
其中
τ
∼
π
\tau\sim\pi
τ∼π表示轨道
τ
\tau
τ是按照策略
π
\pi
π生成的,令
V
(
i
)
V(i)
V(i)为最优策略在任意时刻从状态
i
i
i出发得到的期望奖励,那么问题(3.13.1)也等价于求解
V
(
i
)
=
max
a
{
∑
j
P
a
(
i
,
j
)
(
r
(
i
,
a
)
+
γ
V
(
j
)
)
}
(3.13.2)
V(i)=\max_{a}\{\sum_jP_a(i,j)(r(i,a)+\gamma{V(j)})\}\tag{3.13.2}
V(i)=amax{j∑Pa(i,j)(r(i,a)+γV(j))}(3.13.2)
这个方程可以拆开来看,第一个P就是从i到j的概率嘛,然后
r
(
i
,
a
)
r(i,a)
r(i,a)就是表示你在当前环境下做
a
a
a所带来的奖励,
V
(
j
)
V(j)
V(j)就表示从状态
j
j
j出发得到的期望奖励,这样一直顺延下去,就等表示整局的奖励了
该方程称为
B
e
l
l
m
a
n
Bellman
Bellman方程,在任意时刻,状态
i
i
i处的决策
a
(
i
)
a(i)
a(i)要满足
a
(
i
)
=
arg max
a
{
∑
j
P
a
(
i
,
j
)
(
r
(
i
,
a
)
+
γ
V
(
j
)
)
}
a(i)=\argmax_{a}\{\sum_jP_a(i,j)(r(i,a)+\gamma{V(j)})\}
a(i)=aargmax{j∑Pa(i,j)(r(i,a)+γV(j))}i
可以看到 V ( i ) V(i) V(i)和 a ( i ) a(i) a(i)都不依赖于时间 t t t,其根本原因是下一步的状态仅依赖于当前状态和动作,且转移概率和奖励函数也与时间无关
很多时候,解决实际问题的困难往往在于状态集合或者动作集合中元素的数量非常多,甚至是天文数字,常用的一个方法是将策略用神经网络或者深度神经网络来表达,比如策略的输出是一个可计算的函数,它依赖于一系列参数,如神经网络的权重,为简单起见,人们经常将
π
\pi
π写为
π
θ
\pi_{\theta}
πθ(
θ
\theta
θ是神经网络的参数),问题3.13.1则表示为
max
π
θ
E
τ
∼
π
θ
[
R
(
τ
)
]
(3.13.3)
\max_{\pi_{\theta}}E_{\tau\sim\pi_{\theta}}[R(\tau)]\tag{3.13.3}
πθmaxEτ∼πθ[R(τ)](3.13.3)
到此!第三章over!!
总结:文章来源:https://www.toymoban.com/news/detail-705086.html
 文章来源地址https://www.toymoban.com/news/detail-705086.html
文章来源地址https://www.toymoban.com/news/detail-705086.html
到了这里,关于最优化:建模、算法与理论(优化建模——2)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!