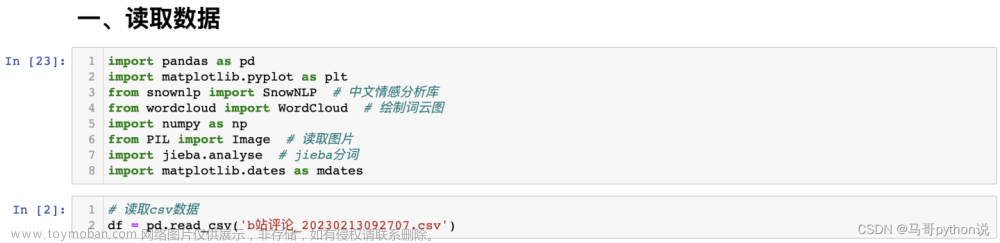
可以使用 Python 爬虫框架如 Scrapy 来爬取 Bilibili 的视频。首先需要了解 Bilibili 网站的构造,包括数据是如何呈现的,然后构建请求来获取所需的数据。同时需要考虑反爬虫措施,可能需要使用代理 IP 和 User-Agent 等方法来绕过反爬虫机制。文章来源:https://www.toymoban.com/news/detail-720886.html
这里提供一个简单的爬取视频标题的例子文章来源地址https://www.toymoban.com/news/detail-720886.html
import requests
from bs4 import BeautifulSoup
url = 'https://www.bilibili.com/video/av12345'
response = requests.get(url)
soup =
到了这里,关于使用python爬虫爬取bilibili视频的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!