1、任务描述
1.1、需求分析
-
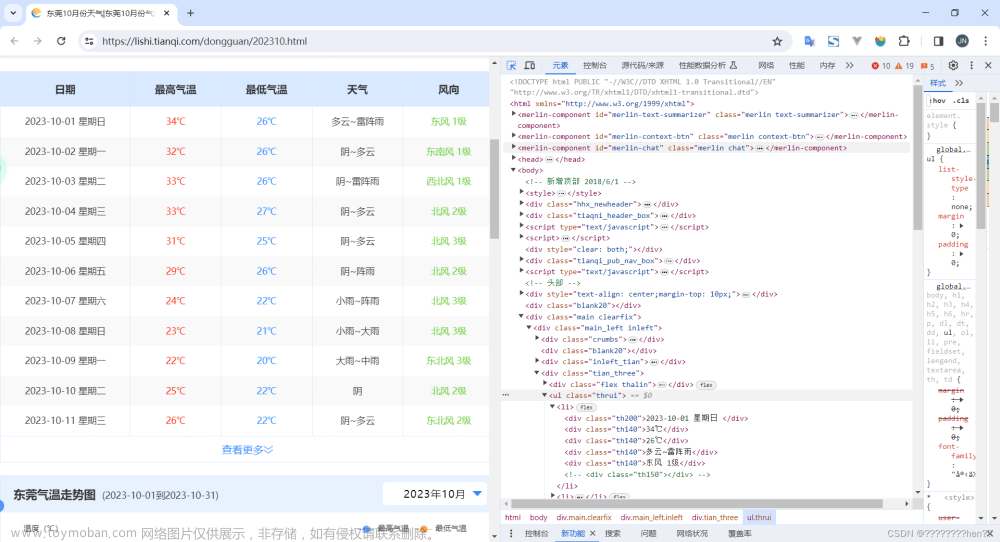
在2345天气信息网2345天气网依据地点和时间对相关城市的历史天气信息进行爬取。
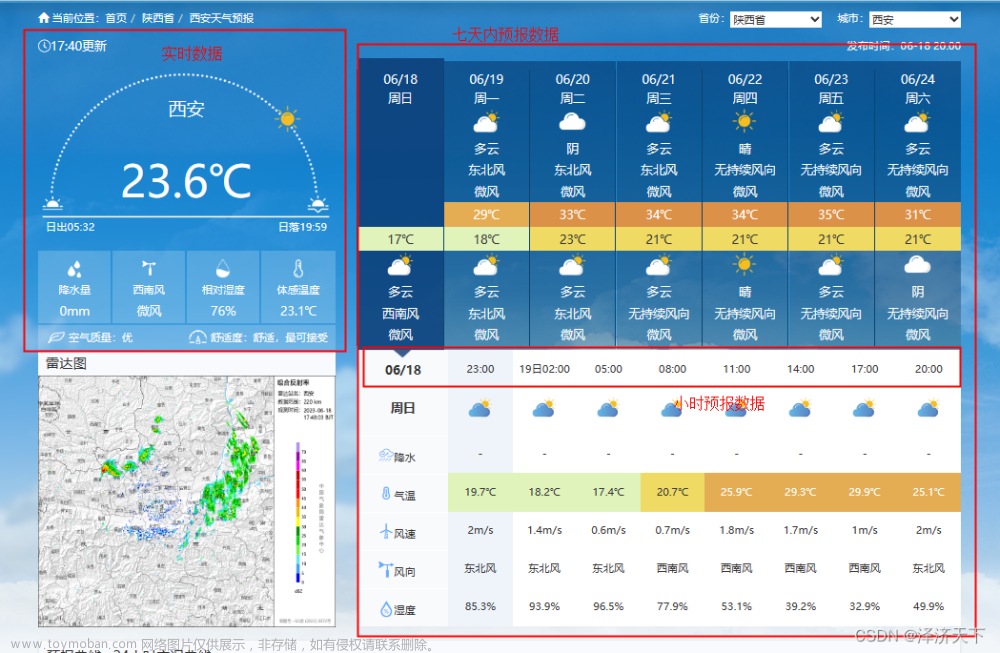
1.2 页面分析
-
网页使用get方式发送请求,所需参数包括areaInfo[areaId]、areaInfo[areaType]、date[year]、date[month],分别为城市id、城市类型,年、月。
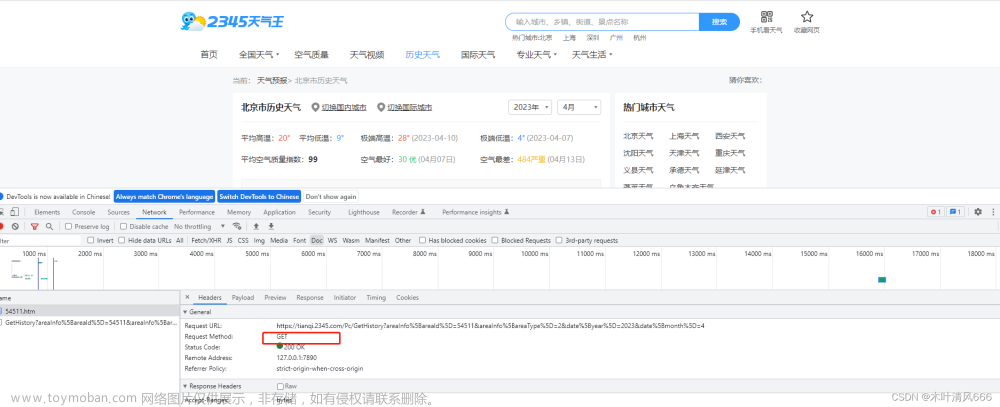
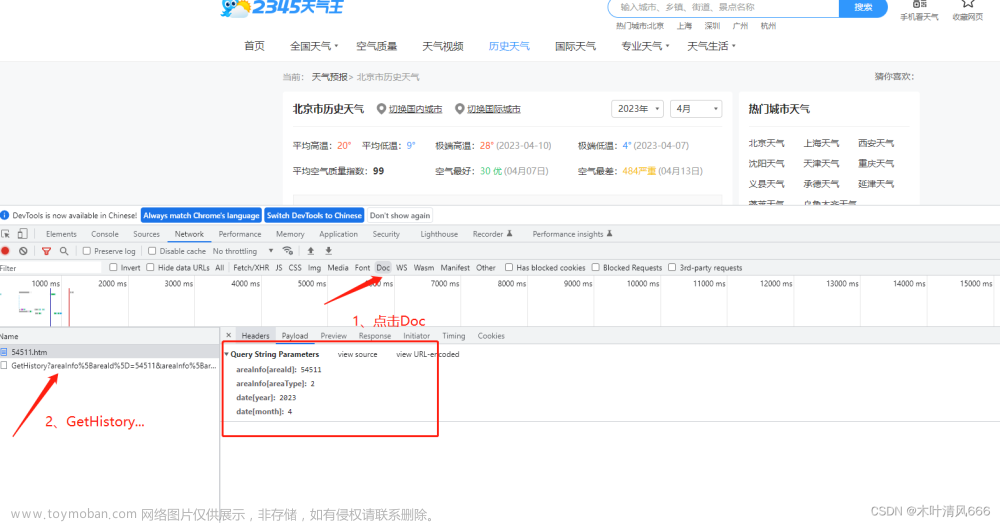
2、获取网页源码、解析、保存数据
import pandas as pd
import requests
from bs4 import BeautifulSoup
url = "https://tianqi.2345.com/Pc/GetHistory"
def crawl_html(year, month):
"""依据年月爬取对应的数据"""
params = {'areaInfo[areaId]': 54511,
'areaInfo[areaType]': 2,
'date[year]': year,
'date[month]': month}
headers = {'User-Agent':'''Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/116.0.0.0 Safari/537.36'''}
response = requests.get(url, headers=headers, params=params)
data = response.json()["data"]
df = pd.read_html(data)[0]
return df
# 下载2015-2023年北京历史天气数据
df_list = []
for year in range(2015, 2023):
for month in range(1, 13):
print("爬取:%d年 %d月"%(year, month))
df = crawl_html(year, month)
df_list.append(df)
pd.concat(df_list).to_excel("practice04_BeijingWeather.xlsx", index=False)
3、结果展示
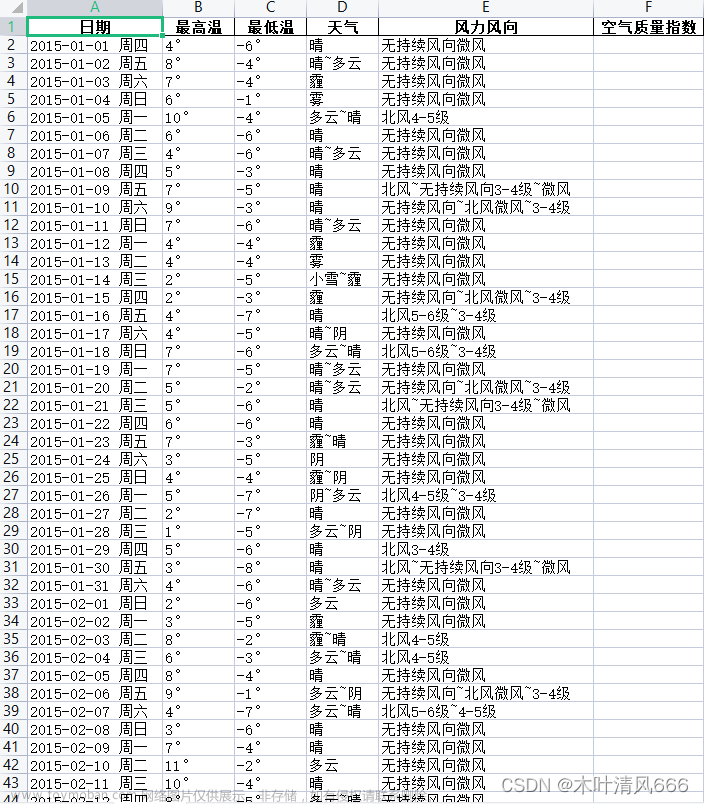 文章来源地址https://www.toymoban.com/news/detail-732400.html
文章来源地址https://www.toymoban.com/news/detail-732400.html
文章来源:https://www.toymoban.com/news/detail-732400.html
到了这里,关于【python爬虫】——历史天气信息爬取的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!