HBase入门与实战


内容要点
- HBase的引入、定义和特点
- NoSQL数据库的概念和与关系型数据库的区别
- HBase的物理架构和逻辑架构
- HBase Shell的基本命令使用
- HBase的应用场景
一、引入HBase
常见的NoSQL数据库:包括Redis和HBase,这些数据库在处理大规模数据集时,相比传统的关系型数据库,提供了更高的灵活性和扩展性。
微服务和高并发:随着传统开发逐渐转向微服务架构,面向"老百姓"的应用需要处理的并发量急剧增加。在这种高并发环境下,传统关系型数据库在增删改查操作上的速度往往跟不上项目的需求。
传统开发解决高并发的策略: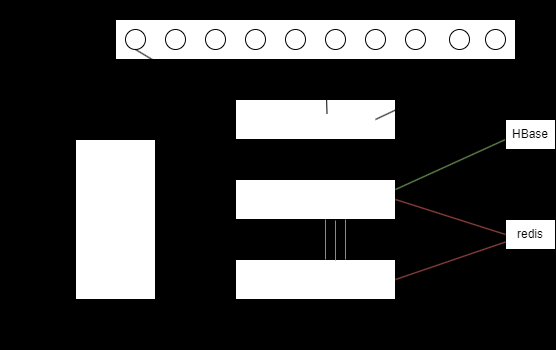
- ① 将数据库中的数据定期存储到Redis中,后端查询操作直接面向Redis来执行。
- ② 构建数据库的Redis的集群化。
引入HBase的原因:当Redis的存储能力不足或主从结构过于复杂导致效率下降,Hbase成为一个优秀的选择。HBase以其【快速的读写速度】和【高吞吐量】,能够有效且快速地处理大数据的增删改查操作。
HBase特点:
-
① 高吞吐量的读写操作
-
为什么HBase有快速的读写速度(高吞吐量)?
-
写操作:
- 内存写入:所有的写操作首先被写入到MemStore中,这一操作是在内存中完成的,高效。并且对于HBase而言,只要数据写入MemStore存储区就标志着写操作已经完成,无需等待落盘。
- 数据备份:在数据刷新到磁盘之前,所有的写操作都会被记录在Hlog,即使故障,也能够恢复数据。
- 并行写操作:HBase的每个列族对应一个MemStore,能够对不同列族的数据进行并行处理。

-
如何理解"无需暂停写入操作以等待数据落盘"的设计理念?
- MemStore提供了一种暂存数据的方式,直至数据被刷新到磁盘上的StoreFile中。
- 通过WAL机制保证MemStore在数据未落盘时发生故障也不会导致数据丢失。
- 保障数据一定能够落盘(即使数据丢失也可以通过HLog恢复数据),此时可以认为操作已经完成。
- 因此写入的数据得到保障后,允许系统在高吞吐量的情况下继续接受和处理新的写请求。
-
读操作:
- 读操作可以直接从内存中的MemStore或者是缓存中的BlockCache获取数据
- 使用Bloom Filter检查所需的数据是否不在StoreFile中,如果数据不在那里,能够及时终止读操作,避免了不必要的磁盘访问。
- (为什么Bloom Filter能够实现快速检查的功能?BloomFilter的算法原理。)
-
-
② HBase天生支持集群部署,无需进行复杂的分表或者分库操作。简化了大规模数据处理的复杂性。
-
③ HBase是列式存储
- 列式存储和行式存储的理解
- 定义
- 列式存储是指每一列的数据存储在一起。
- 行式存储是指每一行的数据存储在一起。
- 列式存储的优势
- 高效的数据存储:当查询特定列的数据(字段)时,数据库可以直接访问这部分连续存储的数据。(相当于索引)
- 对于复杂的分析查询通常只关注数据集中的特定几列,列式存储能够只读取必要的列。
- 压缩与优化:同类型的数据便于压缩与优化。
- 减少冗余:如果存在某部分列数据缺失,则可以在列存储时不存储该部分的值。
HBase 列族:列族是列的逻辑分组,同个列族的所有列存储在一起。
- 定义
- 列式存储和行式存储的理解
二、了解NoSQL的概念
NoSQL(Not Only SQL):非关系型数据库
NoSQL 与 RDBMS 的区别: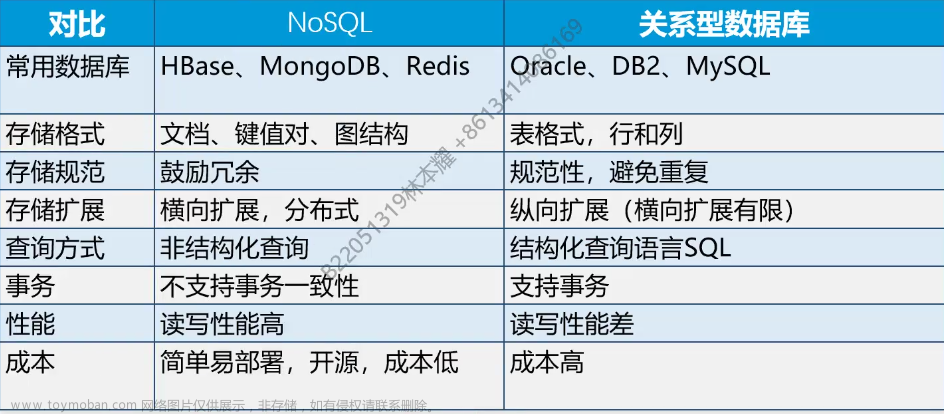
- 数据模型
- 非关系型 VS 关系型
- 查询语言
- 不使用SQL,有独特指令。
- 可【伸缩性】和【可用性】问题
- 伸缩性
- 数据分裂【伸】和 分布式架构
- 文件合并【缩】
- 数据分裂
- 数据分裂是HBase中自动管理数据存储容量的一种机制。
- 当表初始创建时,可能只有一个Region。随着数据量的不断增加,一个HBase表的数据量可能会增长到超出单个Region的承载能力。
- 为了有效管理这种情况,HBase通过数据分裂自动地将表分割为N部分,每个Region包含一部分的数据。
- Region:
- HBase的基本存储单元,由一系列行组成,内部的数据是按照行键(row key)排序的。
- 自动分裂:
- Region大小达到的分裂阈值、RegionServer的数量都可以进行配置。(RegionServer的数量可以进行手动添加)
- 得到的新Region可以被分配到新的RegionServer上(保证负载均衡)
- 分裂的缺陷:分裂阶段处于阻塞状态,往里面写数据可能会导致数据丢失。
- 【优化:可以通过预分裂的方式确定数据规模大概需要分为多少个Region,并在相应的HRegionServer中提前建好Region,就无需做分裂了。能够大大提高写的效率】
- 分裂的过程是由HMaster主导,告诉该台HRegionServer应该迁移到哪一台不同的服务器上面。并且会在HMaster中存储元数据信息的表中记录某张HBase表的数据分别存储在哪几台RegionServer中的哪几个Region?
- 文件合并:
- min_compact:
- 合并较小的、最近生成的
HFiles - 不会丢弃任何删除标记的数据(即使数据被标记为删除,物理上仍然存在于合并过后的文件中)
- 合并较小的、最近生成的
- major_compact:
- 合并一个表中的所有
HFiles - 会彻底删除标记为删除的数据
- 通常是手动触发
- 合并一个表中的所有
- compact后的数据【实际存储】在HDFS上,小的
HFile应该远小于128M
- min_compact:
- 数据分裂
- 分布式架构
- HBase表:抽象概念,物理存储上被细分为多个Region。
- Region:数据存储和访问的基本单元。
- RegionServer:运行在集群中的服务器,负责管理和服务其上存储的一个或多个Region。
- HBase采用的是典型的Master/Slave架构。HBase Master负责管理表和Region的元数据信息,以及RegionServer的负载均衡。而RegionServers负责处理客户端的读写请求,并管理存储在其上的Regions。
- 可用性
- ZooKeeper实现了Client和HMaster之间的协调管理
- HLog(WAL:Write Ahead Log 当数据写入具体的磁盘之前,先将其写一份在日志文件上)
- HLog能够将死去的RegionServer"复活",获取其原来的表数据。
- 当HRegionServer死的时候,则将HLog的数据迁移到另一台服务器上。
- 而数据迁移又依靠HMaster,因此HMaster也需要容灾机制,则出现了HMaster Backup和ZooKeeper进行协调管理。
- 如果ZooKeeper和HMaster之间心跳"断"了,则启用HMaster Backup.
- 伸缩性
- 事务性
-
NoSQL 更加注重 性能、扩展性、灵活性,不像RDBMS一样强调原子性或一致性。
-
一致性问题

- 发生场景:通常发生在实时数仓。
- 批处理:规定记录数达到一定值才发送,可能导致时效性差(前后两条记录的时间间隔长)。
- 流处理:采用每隔一段时间(水位线)就进行数据发送的策略。面临的挑战是如何确保在时间范围内的数据都被纳入处理。
- 解决方案:允许一定的延迟(例如,计算3秒内的数据,但结果会在5秒内出来),这是为了等待那些符合时间范围但尚未被处理的数据。
- 流批一体:流处理和批处理结合的处理模式(Flink)
- 侧输出流:
- 为了保证最终一致性,对因延迟未能纳入批次的数据放入侧输出流中。
- 例如:如果在一个设定的时间窗口(如秒级窗口)内,某些数据未能被处理,这些数据就可以被放入侧输出流中。随后,可以在一个更长的时间窗口(如分钟窗口)内对这些数据进行处理。
- 实时数仓 VS 离线数仓
- 数据准确性:离线数仓高于实时数仓
- 时间范围:
- 实时数仓的时间范围:秒、分、时、天
- 离线数仓的时间范围:天、周、月、年
- 数据校准:
- 可以使用离线数仓的数据去校准实施数仓中同维度的数据(如天),以检测实时数仓的实时性。
- 这种校准通常使用大量模拟数据进行。
-
三、NoSQL、BI、大数据的关系
- BI:商务智能
- 它是一套完整的解决方案
- BI应用设计模型,模型依赖于模式
- BI主要支持标准SQL(RDB)
- 难在业务掌握和熟悉的能力
- NoSQL和大数据相关性较高,但是NoSQL!=大数据
- NoSQL主要帮助大数据解决数据存储问题
四、HBase概述
-
定义
- 是一个面向列存储的NoSQL数据库
- 是一个分布式HashMap,底层数据是Key-Value格式
- 使用HDFS作为存储并利用其可靠性
什么是【分布式HashMap】?
HashMap的本质是用一个简单的值形式映射一个复杂的值形式。
HBase通过一个RowKey提取该RowKey下多个列族下多个列的多个值。
-
特点
- 数据访问速度快,响应时间约2~20ms。
- 实时数仓和离线数仓都会用到HBase:
- 实时数仓
- 响应速度快
- 离线数仓
- 宽表列存储
- 实时数仓
- 支持随机读写,每个节点20k~100k+ ops/s
- 哈希表也可以随机读写
- 可扩展性
- 对Hadoop,1个NameNode只能带1024(实际1009)台DataNode
- 但是HBase可以扩展到20000+节点
- 高并发
-
HBase的物理架构

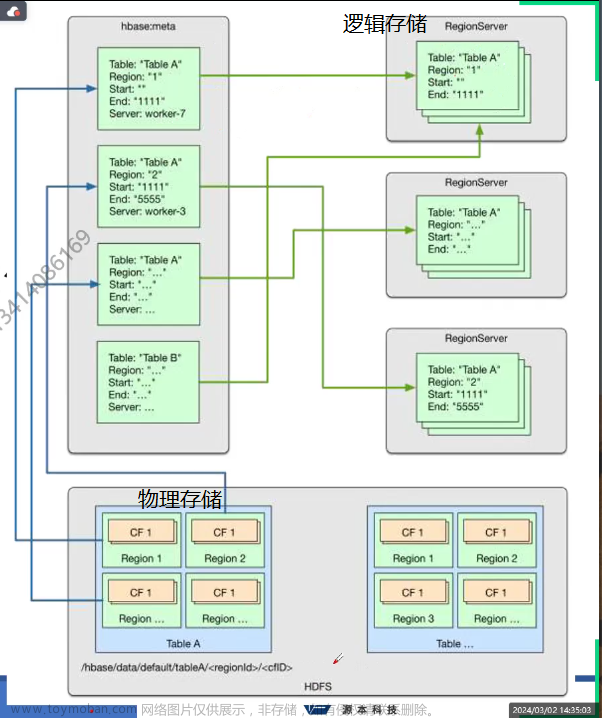
这张图描述了HBase的物理架构,主要包括以下几个部分:
- Client: 客户端,用于与Zookeeper和HMaster进行交互。
- Zookeeper: 用于维护HBase集群的状态和元数据信息。(协调 管理)
- HMaster: HBase集群的主控制节点,负责监控集群状态和管理区域服务器(RegionServer)。
- HRegionServer: 区域服务器,负责存储和管理HBase数据。每个RegionServer管理着多个HRegion。
- HRegion: 表的水平分区,一个Region包含一个或多个MemStore和多个StoreFile。
- MemStore: 内存存储区,用于缓存新写入的数据。
- StoreFile: 持久化存储文件,用于存储从MemStore刷新的数据。
- HFile: StoreFile中的底层物理文件,实际存储数据。
- DFS Client: 与底层HDFS集群交互的客户端。
- HDFS: 底层的分布式文件系统,用于持久化存储HBase数据。
箭头表示各组件之间的交互和数据流向:
- Client与Zookeeper和HMaster交互,用于读写数据。
- HMaster管理和监控RegionServer。
- RegionServer管理MemStore和StoreFile,用于读写数据。
- MemStore中的数据定期刷新到StoreFile。
- StoreFile的数据持久化存储在HDFS上
各组件的作用
-
HMaster
- 是HBase集群的主节点,可以配置多个,用来实现HA
- 一般backup-masters并不配置主机器(master01)
- 处理元数据的变更
- HBase元数据:
- 命名空间名字、表名字、列族的名字、列族内部的schema…
- HBase元数据:
- 监控RegionServer
- 负责RegionServer的负载均衡(分裂时告知将新增数据迁移到哪台RegionServer)
- 处理RegionServer故障转移
- 通过ZooKeeper发布自己的位置到客户端
- 是HBase集群的主节点,可以配置多个,用来实现HA
-
RegionServer
-
负责管理维护Region,负责存储HBase实际数据
- 一个RegionServer包含一个Hlog,一个BlockCache,多个Region(可以是一张表,也可以是不同的表)
- HFile和HLog作为序列化文件保存在HDFS上
- Client直接与RegionServer进行交互
-
功能
- 负责管理HBase的实际数据
- 处理分配给它的Region
- 刷新缓存到HDFS
- 维护HLog
- 执行Compaction
- 负责处理Region分片
-
读写缓存
- 读缓存:BlockCache
- 将最近或频繁访问的数据块(blocks)缓存到内存中,HBase可以快速响应读请求。
- 写缓存:MemStore
- 暂存写入数据,直至达到一定的阈值,然后批量写入磁盘,形成新的StoreFile(HFile)
- 读缓存:BlockCache
-
-
Bloom Filter
-
快速确定数据是否不在StoreFile中,如果不在,读操作即刻终止。
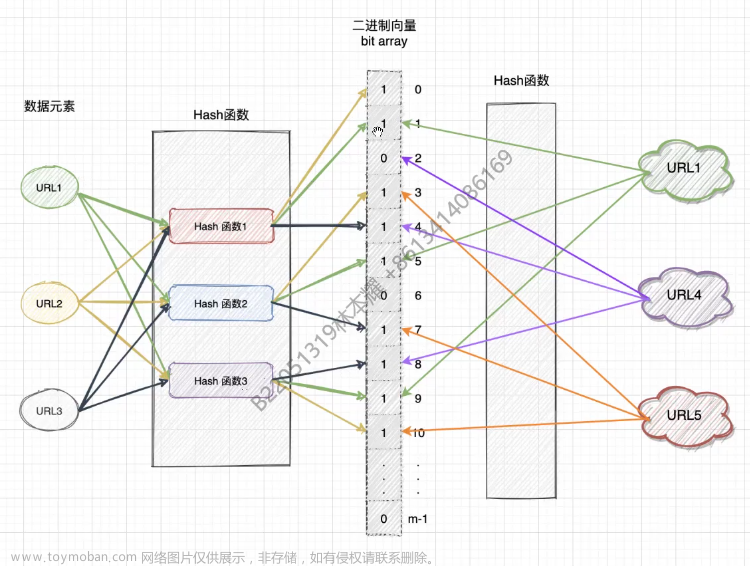
-
工作原理:
- 初始化:创建一个m位的位数组(bit array),初始时将所有位都设为0
- 添加元素:当一个元素(如URL1、URL2、URL3)被加入集合时,通过k个哈希函数生成k个位置索引,并将这些位设置为1。
- 查询元素:要检查一个元素是否存在于集合中,再次通过相同的k个哈希函数生成k个位置索引。
如果所有这些位置的位都是1,那么该元素可能在集合中(存在误判可能)。如果任何一个位置的位时0,则该元素绝对不在集合中。
- 为什么要使用多个哈希函数?
- 降低误判率,避免哈希冲突。
-
-
Region和Table
- 单个Table被分区成大小大致相同的Region
- 一个Region只能分配给一个RegionServer
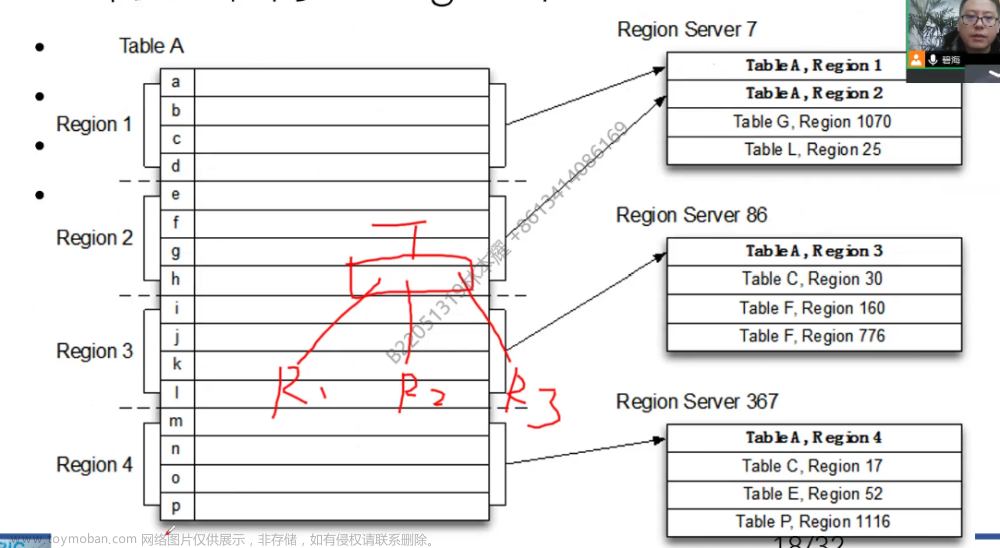
-
HBase逻辑架构
-
Row
- Rowkey(行键)是唯一的并已排序
- Schema可以定义何时插入数据、要保留多少历史版本、分区策略如何、列族叫什么名字
- 每个Row都可以定义自己的列,即使其他Row不使用
- 相关列定义为列族
- 使用唯一时间戳维护多个Row版本
- 在不同版本中值类型可以不同(但不建议)
- HBase数据全部以字节存储
-
RowKey的设计
- 越短越好,不超过16个字节
- 在前缀加随机数使数据均匀地分布到不同的RegionServer。
- 保证RowKey的唯一
-
热点问题
- HBase中的行是按照RowKey的字典顺序排序的,但可能会导致大量的client直接访问集群的一个或极少数个节点
- 大量的访问会使热点Region所在的单个机器超出自身承受能力,引起性能下降甚至Region不可用。
-
常见的设计RowKey的手段("_"的意义是让其分布均匀又不破坏实际意义)
-
加盐
给RowKey加上随机前缀
“456165181_henry@hotmail.com” -
哈希
给RowKey加上哈希前缀
“hashcode(“henry”)_henry@hotmail.com”
-
-
-
HBase的读流程
- 读取:如果Bloom Filter检查通过,或者没有Bloom Filter参与,HBase会从相应的StoreFile读取数据。
- 合并:从不同的StoreFile和MemStore中读取的数据需要被合并,以获得最终的结果,因为一个键的多个版本可能分布在不同的文件和MemStore中。
- Scanner Cache:合并后的数据可以被Scanner Cache暂存,以便快速响应相同的后续读请求。
- 客户端:最后,合并后的数据被发送到客户端。

-
HBase元数据管理
- 数据管理目录
- 系统目录表 hbase:meta(命名空间和表、字段和列族之间都是用":"分开的)
- 存储元数据
- ZooKeeper存储hbase:meta表的位置信息
- 系统目录表 hbase:meta(命名空间和表、字段和列族之间都是用":"分开的)
- HBase实际数据存储在HDFS上
- 数据管理目录
-
HBase Shell
详见HBase Shell汇总
五、HBase应用场景
-
增量数据——时间序列数据
- 高容量、高速写入
- HBase之上有OpenTSDB模块,可以满足时序类场景,比如传感器,系统监控,股票行情监控等。
-
信息交换——消息传递文章来源:https://www.toymoban.com/news/detail-843530.html
- 高容量、高速读写
- 消息应用的软件建立在HBase之上
-
内容服务——Web后端应用程序文章来源地址https://www.toymoban.com/news/detail-843530.html
- 高容量,高速读写
- 头条类、新闻类的新闻、网页、图片存储在HBase上
到了这里,关于【HBase入门与实战】一文搞懂HBase!的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!