Python与Selenium库
简介
Selenium是一个自动化测试工具,利用它可以驱动浏览器模拟用户在页面上的操作,例如:点击,输入,选择等行为,使我们可以通过编写Python脚本来进行web页面的自动化测试。
安装Selenium
Selenium包含三个部分:Selenium IDE、Selenium Grid和Selenium WebDriver,其中,Selenium WebDriver是我们所需要用到的,因为它可以驱动各种浏览器进行页面的自动化测试。
Selenium WebDriver包含多个浏览器驱动程序,比如:ChromeDriver、FireFoxDriver等,这些驱动程序可以根据个人需求进行选择,默认情况下,Selenium WebDriver的驱动程序不包含在Java或Python库中,因此我们需要先从如下地址下载对应的ChromeDriver(以Chrome浏览器为例)。
下载地址:
https://sites.google.com/a/chromium.org/chromedriver/downloads
选择与浏览器对应的版本进行下载,下载后将chromedriver.exe文件放到Python的路径中,例如放入Python36\Scripts文件夹下(如果是其他浏览器,则下载对应驱动进行使用)。
安装Selenium
pip install selenium
使用Selenium
下面我们将学习如何使用Selenium来进行web页面自动化测试。
打开浏览器
使用webdriver的类方法启动所需浏览器。
打开Chrome浏览器:
from selenium import webdriver
driver = webdriver.Chrome()
访问网站
使用get方法访问所需的网站。
driver.get("http://www.baidu.com")
查找元素
根据元素的id、name、class等属性定位元素,使用webdriver的find_element_by_*方法查找,返回一个WebElement对象。
from selenium.webdriver.common.by import By
element = driver.find_element(By.TAG_NAME, "input")
操作元素
可以对找到的元素进行不同的操作,例如:输入文本、点击、选择等行为。
input_element = driver.find_element(By.NAME, "wd")
input_element.send_keys("Selenium")
# 提交搜索
submit_element = driver.find_element(By.ID, "su")
submit_element.click()
等待
在访问某些网站时,网站可能需要一些时间来加载页面或元素,此时我们可以使用Selenium提供的等待机制,以确保所需元素的出现和交互行为的完成。
Selenium提供了两种等待方式:
- 隐式等待(Implicit Wait):如果找到元素不存在,等待一定时间后抛出异常,使用方法driver.implicitly_wait(seconds);
- 显式等待(Explit Wait):在给定的时间内等待指定的条件出现,可以自定义等待的条件,等待超时后抛出异常,使用方法WebDriverWait(driver, timeout, poll_frequency=500, ignored_exceptions=None).until(expected_conditions.条件)。
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 等待元素出现
try:
# 显式等待
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "content_left")))
# 隐式等待
# driver.implicitly_wait(10)
except Exception:
print("元素未找到")
关闭浏览器
在自动测试过程中,需要在最后关闭浏览器。
driver.quit()
示例代码
下面是一个完整的示例代码。该代码实现了打开百度首页,输入文本,点击搜索按钮,等待结果出现并打印第一条搜索结果的标题。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 启动浏览器
driver = webdriver.Chrome()
# 访问网站
driver.get("http://www.baidu.com")
# 输入搜索文本
input_element = driver.find_element(By.NAME, "wd")
input_element.send_keys("Selenium")
# 点击搜索
submit_element = driver.find_element(By.ID, "su")
submit_element.click()
# 显式等待
try:
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "content_left")))
except Exception:
print("元素未找到")
# 查找元素
result_element = driver.find_element(By.CSS_SELECTOR, "#content_left div.c-container h3.t a")
# 打印第一条搜索结果的标题
print(result_element.text)
# 关闭浏览器
driver.quit()
总结
通过Python与Selenium的结合,我们可以进行网站自动化测试,实现自动化输入、点击、选择等行为,以及对搜索结果进行定位和获取等操作,从而提高测试效率和可靠性,也可以应用于爬虫程序中。
爬虫实战
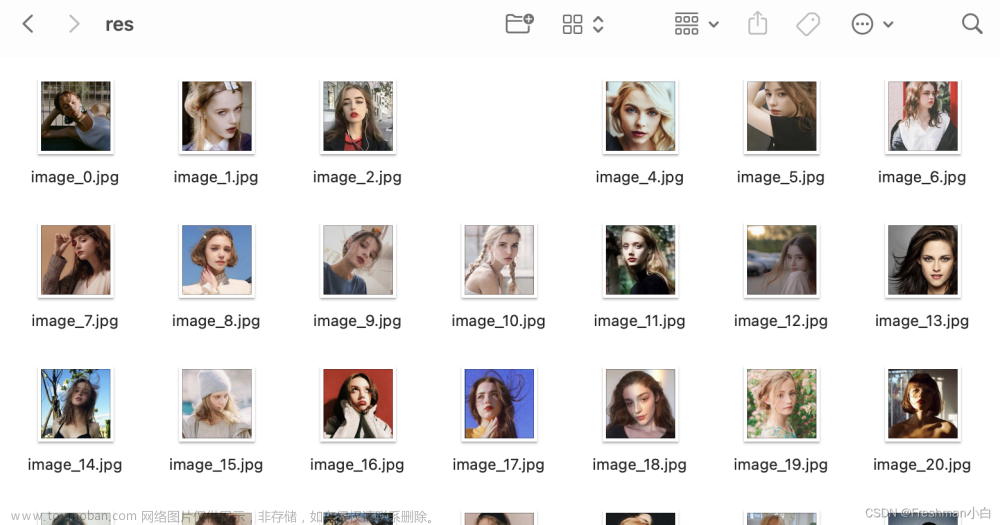
批量获取bing图片搜索引擎中的欧美头像文章来源:https://www.toymoban.com/news/detail-787871.html
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
driver = webdriver.Safari()#选择驱动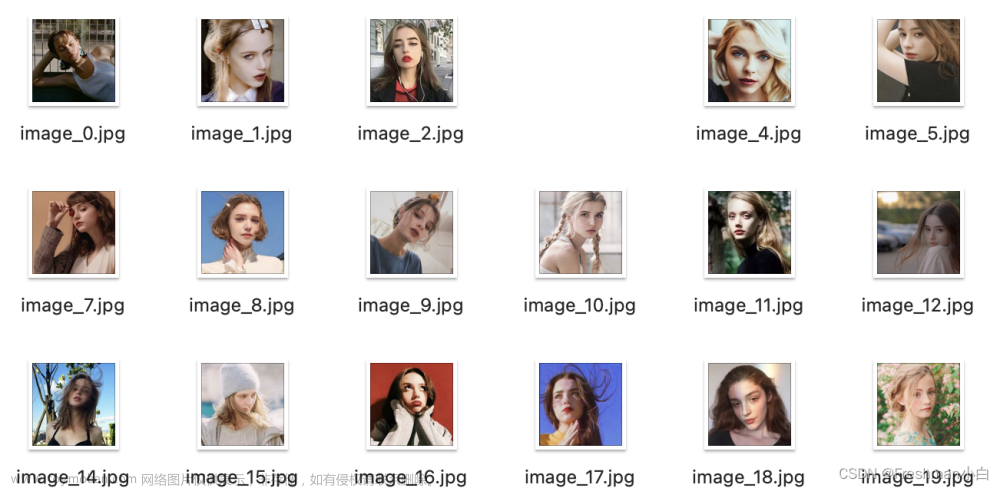 driver.get("https://www.bing.com/images")
# 找到搜索框并输入关键字
search_box = driver.find_element(By.NAME,"q")
search_box.send_keys("欧美头像")
search_box.send_keys(Keys.RETURN)
# 等待页面加载完成
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "mmComponent_images_1")))
# 模拟下拉到底部的操作,让更多的图片显示出来
SCROLL_PAUSE_TIME = 1
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(SCROLL_PAUSE_TIME)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
# 找到所有图片的元素
images = driver.find_elements(By.XPATH,"//img[contains(@class,'mimg')]")
urls = []
for image in images:
# 仅保留纵横比为1:1的图片
width = int(image.get_attribute("width"))
height = int(image.get_attribute("height"))
if width == height:
url = image.get_attribute("src")
urls.append(url)
# 输出图片url
# 关闭浏览器
driver.quit()
import urllib.request
# 保存图片到本地
for i, url in enumerate(urls):
urllib.request.urlretrieve(url, f"image_{i}.jpg")
driver.get("https://www.bing.com/images")
# 找到搜索框并输入关键字
search_box = driver.find_element(By.NAME,"q")
search_box.send_keys("欧美头像")
search_box.send_keys(Keys.RETURN)
# 等待页面加载完成
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, "mmComponent_images_1")))
# 模拟下拉到底部的操作,让更多的图片显示出来
SCROLL_PAUSE_TIME = 1
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(SCROLL_PAUSE_TIME)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
# 找到所有图片的元素
images = driver.find_elements(By.XPATH,"//img[contains(@class,'mimg')]")
urls = []
for image in images:
# 仅保留纵横比为1:1的图片
width = int(image.get_attribute("width"))
height = int(image.get_attribute("height"))
if width == height:
url = image.get_attribute("src")
urls.append(url)
# 输出图片url
# 关闭浏览器
driver.quit()
import urllib.request
# 保存图片到本地
for i, url in enumerate(urls):
urllib.request.urlretrieve(url, f"image_{i}.jpg")
 文章来源地址https://www.toymoban.com/news/detail-787871.html
文章来源地址https://www.toymoban.com/news/detail-787871.html
完
到了这里,关于Python与Selenium库(含爬虫实战例子)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!