python爬虫爬取网易云音乐
-

网易云音乐小程序案例分享 附完整代码
todo: 添加音乐到收藏(最近)列表 歌词滚动
-

微信小程序之网易云音乐小案例
目录 一.编写对网易云音乐api发起请求的代码 二.编写视频项(组件) 三.编写mv列表:包含(轮播图+视频列表[每个视频项引用组件来呈现]) 四.编写视频详情页 成品图: 准备工作: ——在pages下新建两个page(index,video_detail)mv首页和视频详情 ——在根目录下创建components,并在其中创建
-
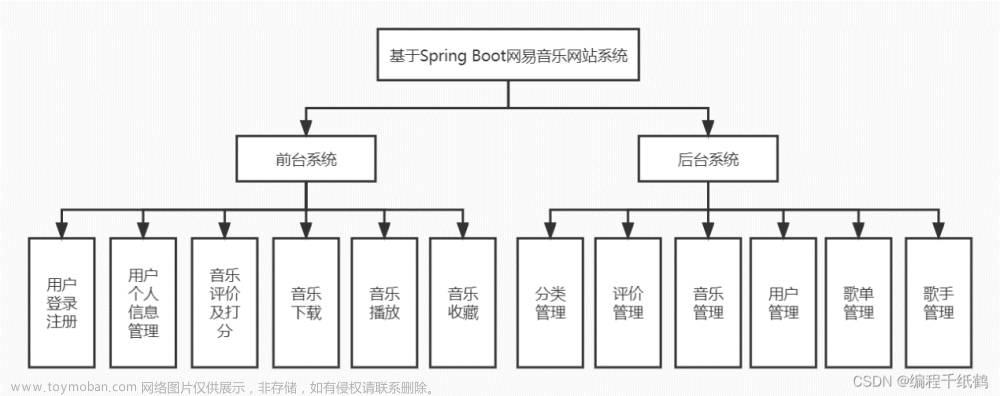
网易音乐网站系统|前后端分离springboot+vue实现在线音乐网站
作者主页:编程千纸鹤 作者简介:Java、前端、Python开发多年,做过高程,项目经理,架构师 主要内容:Java项目开发、毕业设计开发、面试技术整理、最新技术分享 收藏点赞不迷路 关注作者有好处 文末获得源码 项目编号:BS-PT-104 网易音乐网站系统是一个在线的音乐网站
-
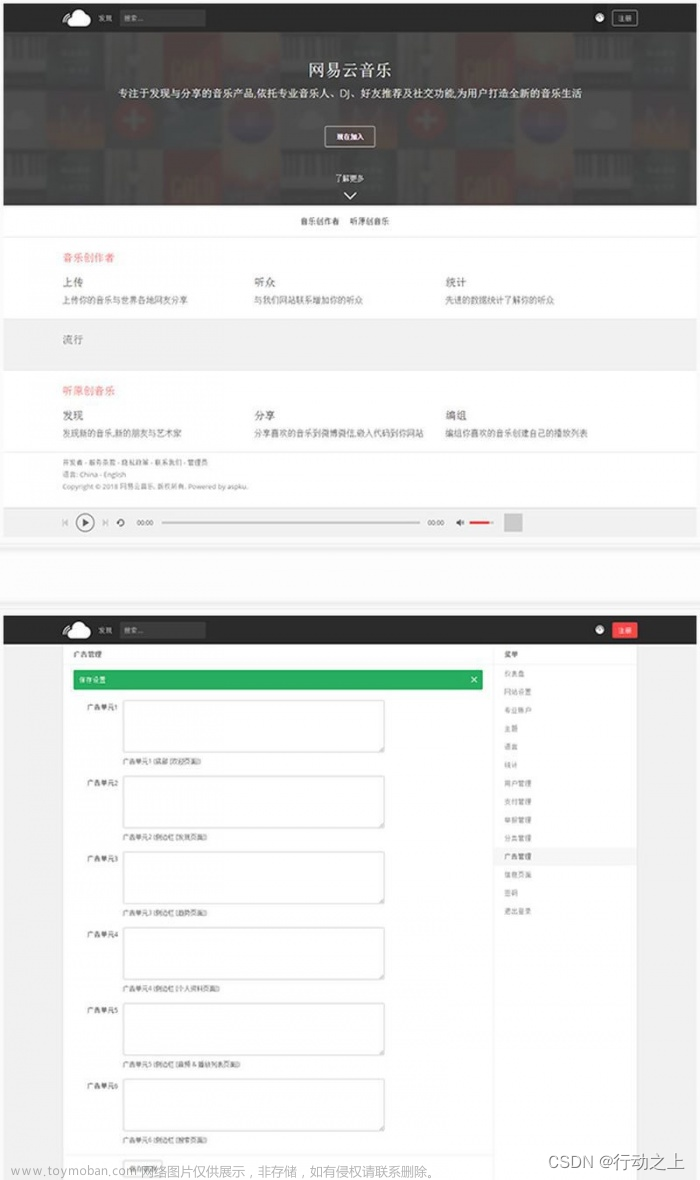
仿网易云音乐网站PHP源码,可运营的音乐分享平台源码,在线音乐库系统
使用PHP和MYSQL开发的原创音乐分享平台源码,仿网易云音乐网站。用户可以在网站上注册并上传自己的音乐作品,系统内置广告系统,为网站创造收入来源。 安装教程 1.导入sql.sql 2.修改 includesconfig.php 数据库信息和网址都改成自己的 后台 域名+/index.php?a=admin 账号 ad
-
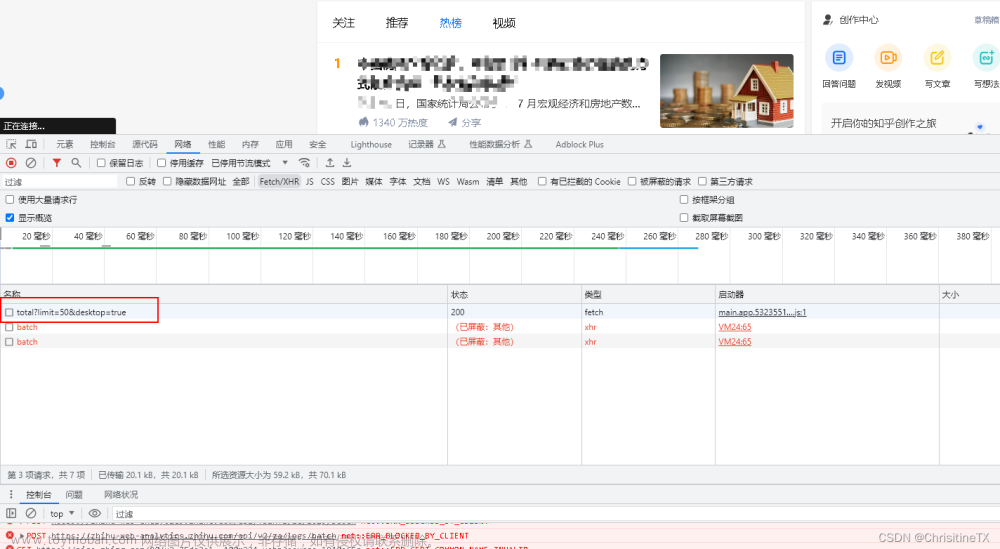
python爬虫实战(3)--爬取某乎热搜
1. 分析爬取地址 打开某乎首页,点击热榜 这个就是我们需要爬取的地址,取到地址 某乎/api/v3/feed/topstory/hot-lists/total?limit=50desktop=true 定义好请求头,从Accept往下的请求头全部复制,转换成json 2. 分析请求结果 通过请求可以看出, hot-lists/total?limit=50desktop=true 请求后的返回参数
-
《python爬虫练习2》爬取网站表情包
运行环境: 1.分析: 目标网址:https://www.runoob.com/ 首先想要获取什么就从哪里入手,打开图所在的网页,F12查看代码的内容,此处抓取的是资源文件,爬取中发现ajax类型的文件加载出来的无法知道图片的源地址所以暂时不能用这种方式获取。因此可以生成第一步的代码。
-
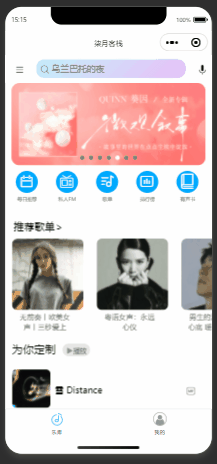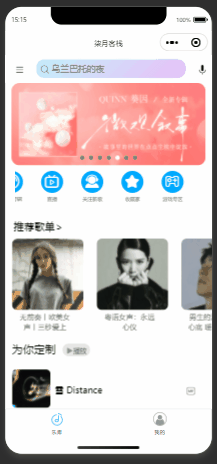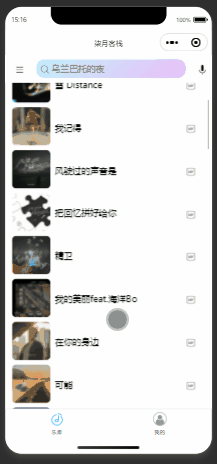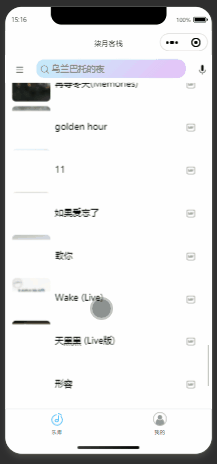
微信小程序仿网易音乐播放器项目
主页样式 播放页样式 搜索页样式 排行榜页样式 小控件样式 网易云音乐API接口 后端接口,使用node写的,使用了网易云音乐API: 封装的api文件 主页面功能点 banner,滑动菜单栏采用微信的API( swiper 与 scroll-view )进行开发 滑动到底部重新获取后续的歌曲,使用onReachBottom周期
-

获取网易云音乐开放接口api的推荐歌单
网易云音乐开放api接口 网址:https://binaryify.github.io/NeteaseCloudMusicApi/#/?id=neteasecloudmusicapi 项目地址:https://github.com/Binaryify/NeteaseCloudMusicApi 下载下来之后,安装依赖:npm install 启动服务: node app.js 启动成功之后,根据api接口文档就可以获取请求的url了。 本文需求是,获取推荐
-
![[MAUI]模仿网易云音乐黑胶唱片的交互实现](https://imgs.yssmx.com/Uploads/2024/02/424568-1.gif)
[MAUI]模仿网易云音乐黑胶唱片的交互实现
@ 目录 创建页面布局 创建手势控件 创建影子控件 唱盘拨动交互 唱盘和唱针动画 项目地址 用过网易云音乐App的同学应该都比较熟悉它播放界面。 这是一个良好的交互设计,留声机的界面隐喻准确地向人们传达产品概念和使用方法:当手指左右滑动时,便模拟了更换唱盘从而
-
网易云音乐微信小程序 毕业设计
本期我们将讲解网易云音乐微信小程序。 之前我已经讲过网易云音乐小程序的旧版本。现在是全新的版本,涉及的功能点非常多。接下来,我们将对这个项目进行详细介绍。 首先,我们来看整个网易云音乐小程序的主页,也就是音乐界面。首页中有一个 banana 轮播图,下面是
-

网易云音乐API部署Vercel获取接口过程
前提 :部署自己的网易云接口主要用途在于在完成前端的仿网易云播放器的时候,根据自己部署的接口可以用于获取数据。大体流程是通过在github上fork别人的API接口项目,然后在Vercel部署即可获得自己的网易云后端数据接口了,不过根据我之前参考的博客来看,好像22年下之
-
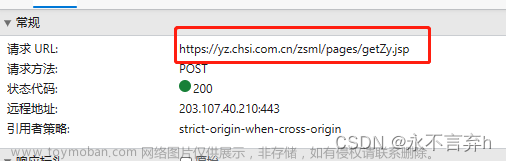
爬虫学习记录之Python 爬虫实战:爬取研招网招生信息详情
【简介】本篇博客 为爱冲锋 ,爬取北京全部高校的全部招生信息,最后持久化存储为表格形式,可以用作筛选高校。 此处导入本次爬虫所需要的全部依赖包分别是以下内容,本篇博客将爬取研招网北京所有高校的招生信息,主要爬取内容为学校,考试方式,所在学院,专业
-

Python爬虫入门:使用selenium库,webdriver库模拟浏览器爬虫,模拟用户爬虫,爬取网站内文章数据,循环爬取网站全部数据。
*严正声明:本文仅限于技术讨论与分享,严禁用于非法途径。 目录 准备工具: 思路: 具体操作: 调用需要的库: 启动浏览器驱动: 代码主体: 完整代码(解析注释): Python环境; 安装selenium库; Python编辑器; 待爬取的网站; 安装好的浏览器; 与浏览器版本相对应的
-
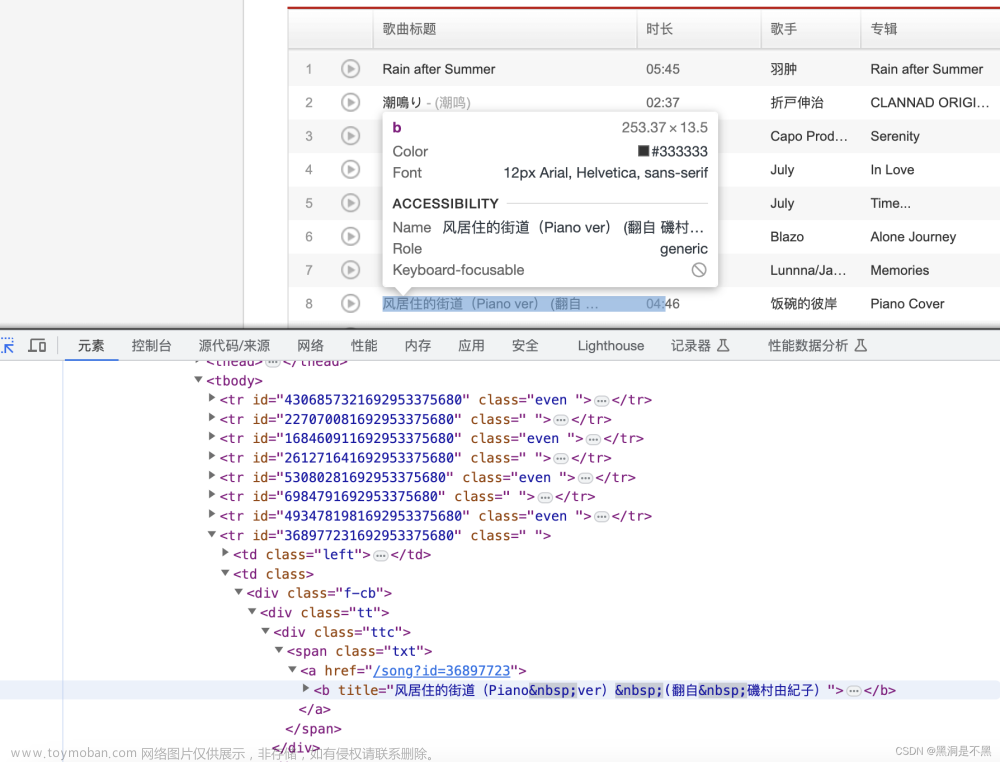
python爬虫实战零基础(3)——某云音乐
声明:仅供参考学习,参考,若有不足,欢迎指正 你是不是遇到过这种情况,在pc端上音乐无法下载,必须下载客户端才能下载? 那么,爬虫可以解决这个麻烦!继续实战利用request和xpath爬取网上音乐。 本文主要是在网页端下载音乐,如果你有客户端也可以,太高级的笔者
-
![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频](https://imgs.yssmx.com/Uploads/2024/04/855397-1.png)
[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频
audio_DATA_get = requests.get(url=audio_DATA,headers=headers) audio_DATA_get_text = audio_DATA_get.text audio_DATA_download_url = re.findall(‘“src”:“(.*?)”’,audio_DATA_get_text) print(audio_DATA_download_url) download_data_url = audio_DATA_download_url[0] try: open_download_data_url = urllib.request.urlopen(download_data_url) except: print(downlo
-
Python爬虫实战入门:爬取360模拟翻译(仅实验)
需求 目标网站: https://fanyi.so.com/# 要求:爬取360翻译数据包,实现翻译功能 所需第三方库 requests 简介 requests 模块是 python 基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。 安装 pip install -i https://py
-
Python应用-爬虫实战-求是网周刊文章爬取
任务描述 本关任务:编写一个爬虫,并使用正则表达式获取求是周刊 2019 年第一期的所有文章的 url 。详情请查看《求是》2019年第1期 。 相关知识 获取每个新闻的 url 有以下几个步骤: 首先获取 2019 年第 1 期页面的源码,需要解决部分反爬机制; 找到目标 url 所在位置,观
-
Python 爬虫:如何用 BeautifulSoup 爬取网页数据
在网络时代,数据是最宝贵的资源之一。而爬虫技术就是一种获取数据的重要手段。Python 作为一门高效、易学、易用的编程语言,自然成为了爬虫技术的首选语言之一。而 BeautifulSoup 则是 Python 中最常用的爬虫库之一,它能够帮助我们快速、简单地解析 HTML 和 XML 文档,从而
-
Python如何运用爬虫爬取京东商品评论
打开京东商品网址(添加链接描述) 查看商品评价 。我们点击评论翻页,发现网址未发生变化,说明该网页是动态网页。 我们在 浏览器右键点击“检查” ,,随后 点击“Network” ,刷新一下,在搜索框中 输入”评论“ ,最终找到 网址(url) 。我们点击Preview,发现了我们需要
-

Python爬虫:从后端分析为什么你爬虫爬取不到数据
仅仅是小编总结的三点而已,可能不是很全面,如果之后小编了解到新的知识点,可能还会增加的哈! 1. 最简单的爬虫代码 也就是各位最常使用的,直接利用requests模块访问当前网站链接,利用相关解析模块从而获取得到自己想要的数据,如下(利用python爬虫爬取自己csdn个人