python爬虫爬取网页数据代码
-
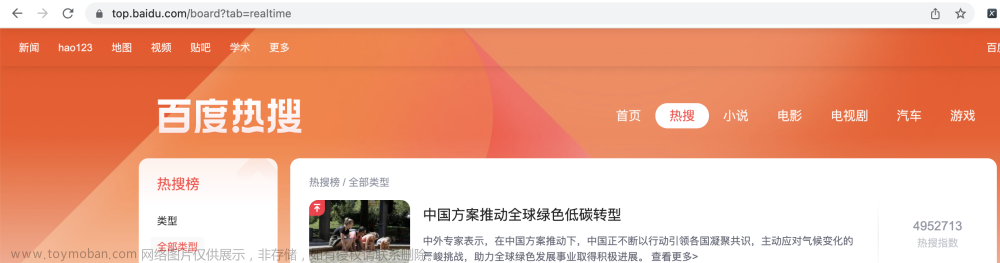
【爬虫案例】用Python爬取百度热搜榜数据!
目录 一、爬取目标 二、编写爬虫代码 三、同步视频讲解 四、完整源码 您好,我是@马哥python说,一名10年程序猿。 本次爬取的目标是:百度热搜榜 分别爬取每条热搜的: 热搜标题、热搜排名、热搜指数、描述、链接地址。 下面,对页面进行分析。 经过分析,此页面有XH
-
Python爬虫 | 爬取微博和哔哩哔哩数据
目录 一、bill_comment.py 二、bili_comment_pic.py 三、bilibili.py 四、bilihot_pic.py 五、bilisearch_pic.py 六、draw_cloud.py 七、weibo.py 八、weibo_comment.py 九、weibo_comment_pic.py 十、weibo_pic.py 十一、weibo_top.py 十二、weibo_top_pic.py 十三、weibo_top_pie.py 十四、pachong.py 十五、代码文件说明 pachong: b站、
-

Python爬虫实战:selenium爬取电商平台商品数据(1)
def index_page(page): “”\\\" 抓取索引页 :param page: 页码 “”\\\" print(‘正在爬取第’, str(page), ‘页数据’) try: url = ‘https://search.jd.com/Search?keyword=iPhoneev=exbrand_Apple’ driver.get(url) if page 1: input = driver.find_element_by_xpath(‘//*[@id=“J_bottomPage”]/span[2]/input’) button = driver.find_element_by_xpath(‘
-
如何使用python实现简单爬取网页数据并导入MySQL中的数据库
前言:要使用 Python 爬取网页数据并将数据导入 MySQL 数据库,您需要使用 Requests 库进行网页抓取,使用 BeautifulSoup 库对抓取到的 HTML 进行解析,并使用 PyMySQL 库与 MySQL 进行交互。 以下是一个简单的示例: 1. 安装所需库: ``` ``` 2. 导入所需库: ``` ``` 3. 建立数据库连接:
-
python爬虫爬取中关村在线电脑以及参数数据
python爬虫爬取中关村在线电脑以及参数数据 2.1vsCode 2.2Anaconda version: conda 22.9.0 3.1 代码 解析都在代码里面 3.2 结果展示 这是保存到数据,用json保存的
-

Python中使用隧道爬虫ip提升数据爬取效率
作为专业爬虫程序员,我们经常面临需要爬取大量数据的任务。然而,有些网站可能会对频繁的请求进行限制,这就需要我们使用隧道爬虫ip来绕过这些限制,提高数据爬取效率。本文将分享如何在Python中使用隧道爬虫ip实现API请求与响应的技巧。并进行详细的解析和实际代码
-
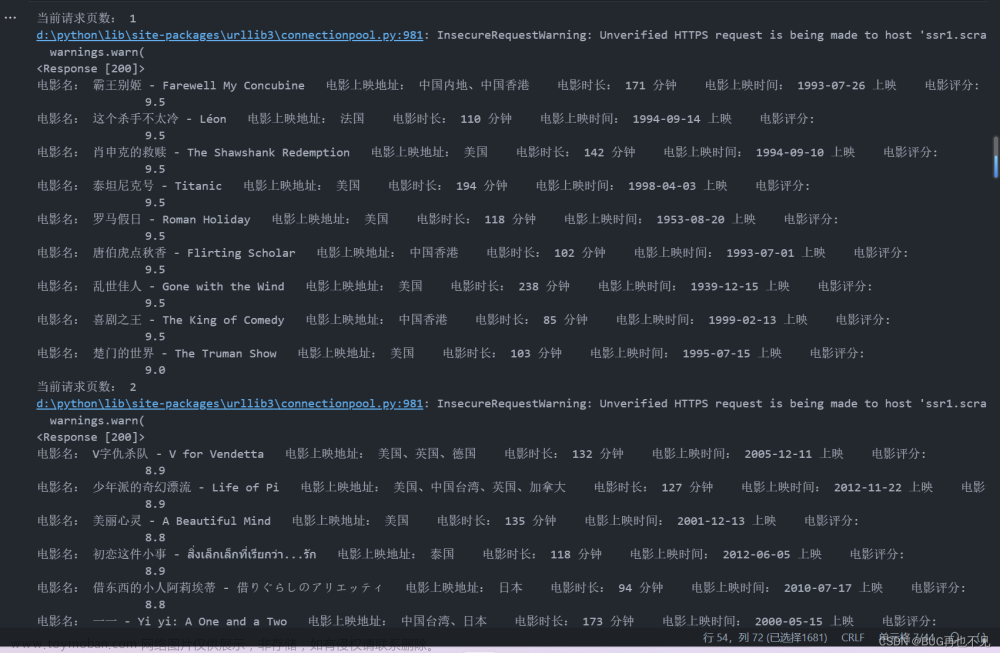
python爬虫爬取电影数据并做可视化
1、发送请求,解析html里面的数据 2、保存到csv文件 3、数据处理 4、数据可视化 需要用到的库: 注意:后续用到分词库jieba以及词频统计库nltk 解释器: python 3.10.5 编辑器:VsCode -jupyter-notebook 使用ipynb文件的扩展名 vscode会提示安装jupyter插件 效果: 注意:使用jieba分词,
-
Python爬虫:实现爬取、下载网站数据的几种方法
使用脚本进行下载的需求很常见,可以是常规文件、web页面、Amazon S3和其他资源。Python 提供了很多模块从 web 下载文件。下面介绍 requests 模块是模仿网页请求的形式从一个URL下载文件 示例代码: 安装 wget 库 示例代码 有些 URL 会被重定向到另一个 URL,后者是真正的下载链接
-
【Python爬虫】基于selenium库爬取京东商品数据——以“七夕”为例
小白学爬虫,费了一番功夫终于成功了哈哈!本文将结合本人踩雷经历,分享给各位学友~ 用写入方式打开名为data的csv文件,并确定将要提取的五项数据。 上面第一行代码值得一提,driver = webdriver.Edge()括号内为Edge浏览器驱动程序地址,需要在Edge浏览器设置中查找Edge浏览器
-
Python爬虫基础之如何对爬取到的数据进行解析
原文地址: https://www.program-park.top/2023/04/13/reptile_2/ 在上一篇博客中,讲了如何使用 urllib 库爬取网页的数据,但是根据博客流程去操作的人应该能发现,我们爬取到的数据是整个网页返回的源码,到手的数据对我们来说是又乱又多的,让我们不能快速、准确的定位到所需
-

【Python】爬虫练习-爬取豆瓣网电影评论用户的观影习惯数据
目录 前言 一、配置环境 1.1、 安装Python 1.2、 安装Requests库和BeautifulSoup库 1.3.、安装Matplotlib 二、登录豆瓣网(重点) 2.1、获取代理 2.2、测试代理ip是否可用 2.3、设置大量请求头随机使用 2.4、登录豆瓣网 三、爬取某一部热门电影数据 3.1、爬取全部长、短评论 3.2、获取用户
-
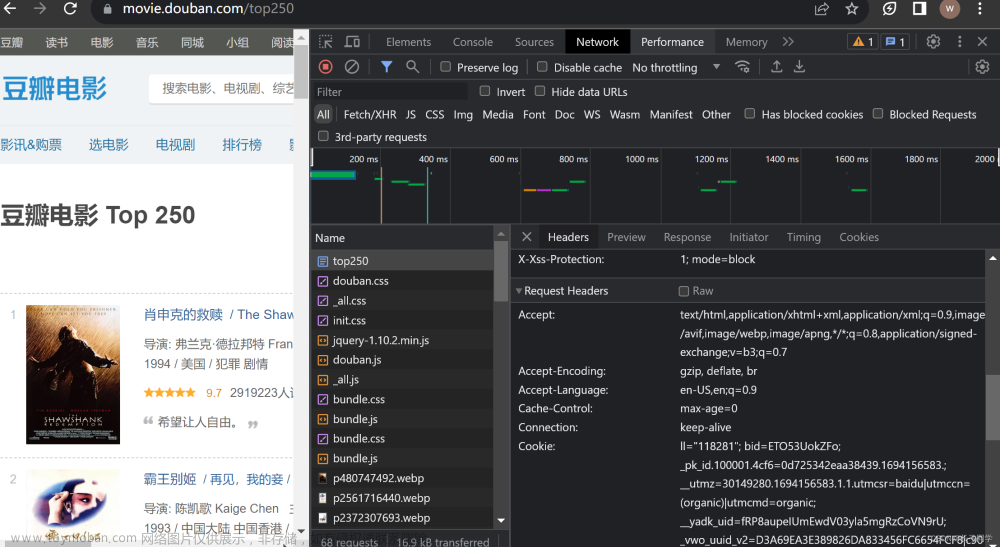
python爬虫——爬取豆瓣top250电影数据(适合初学者)
爬取豆瓣top250其实是初学者用于练习和熟悉爬虫技能知识的简单实战项目,通过这个项目,可以让小白对爬虫有一个初步认识,因此,如果你已经接触过爬虫有些时间了,可以跳过该项目,选择更有挑战性的实战项目来提升技能。当然,如果你是小白,这个项目就再适合不过
-
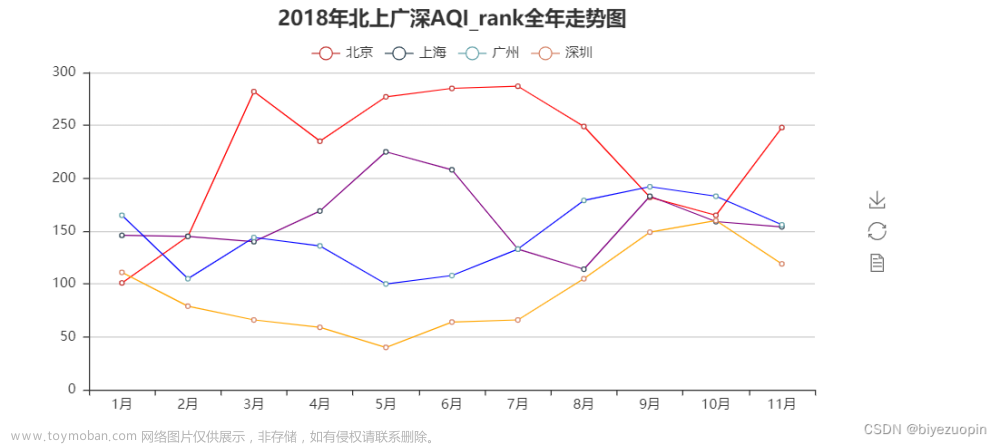
基于Python的网络爬虫爬取天气数据可视化分析
目录 摘 要 1 一、 设计目的 2 二、 设计任务内容 3 三、 常用爬虫框架比较 3 四、网络爬虫程序总体设计 3 四、 网络爬虫程序详细设计 4 4.1设计环境和目标分析 4 4.2爬虫运行流程分析 5 爬虫基本流程 5 发起请求 5 获取响应内容 5 解析数据 5 保存数据 5 Request和Response 5 Request 5
-
〖Python网络爬虫实战㉕〗- Ajax数据爬取之Ajax 案例实战
订阅:新手可以订阅我的其他专栏。免费阶段订阅量1000+ python项目实战 Python编程基础教程系列(零基础小白搬砖逆袭) 说明:本专栏持续更新中,目前专栏免费订阅,在转为付费专栏前订阅本专栏的,可以免费订阅付费专栏,
-
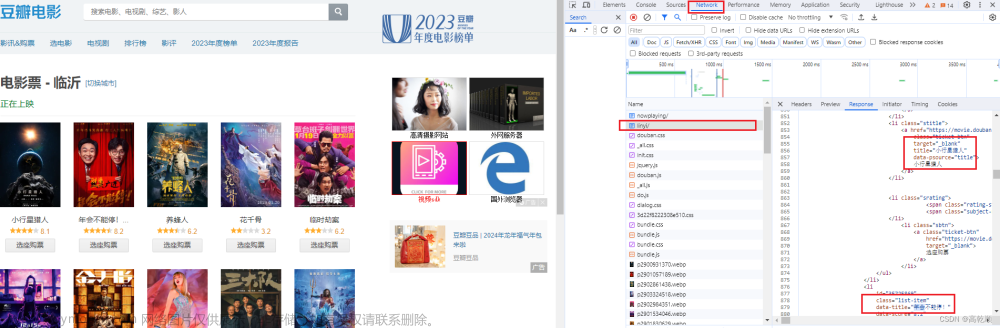
【Python网络爬虫】三分钟教会你使用SeleniumWire快速爬取数据
在终端使用pip进行安装 pip install xxx 这里我使用的是Chrome,其中列举了几个常用的option,供大家学习使用 option = webdriver.ChromeOptions():设置Chrome启动选项 option.add_argument(‘headless’):不打开浏览器进行数据爬取,因为没有可视化过程,所以推荐整个流程开发完毕后,在使用此条
-
〖Python网络爬虫实战㉔〗- Ajax数据爬取之Ajax 分析案例
订阅:新手可以订阅我的其他专栏。免费阶段订阅量1000+ python项目实战 Python编程基础教程系列(零基础小白搬砖逆袭) 说明:本专栏持续更新中,目前专栏免费订阅,在转为付费专栏前订阅本专栏的,可以免费订阅付费专栏,
-

【Python】实现爬虫(完整版),爬取天气数据并进行可视化分析
✌️✌️✌️大家好呀,你们的作业侠又轰轰轰的出现了,这次给大家带来的是python爬虫,实现的是爬取某城市的天气信息并使用matplotlib进行图形化分析✌️✌️✌️ 要源码可私聊我。 大家的关注就是我作业侠源源不断的动力,大家喜欢的话,期待三连呀😊😊😊 往期源码
-

爬虫入门指南(4): 使用Selenium和API爬取动态网页的最佳方法
随着互联网的发展,许多网站开始采用动态网页来呈现内容。与传统的静态网页不同,动态网页使用JavaScript等脚本技术来实现内容的动态加载和更新。这给网页爬取带来了一定的挑战,因为传统的爬虫工具往往只能获取静态网页的内容。本文将介绍如何使用Selenium和API来实现
-
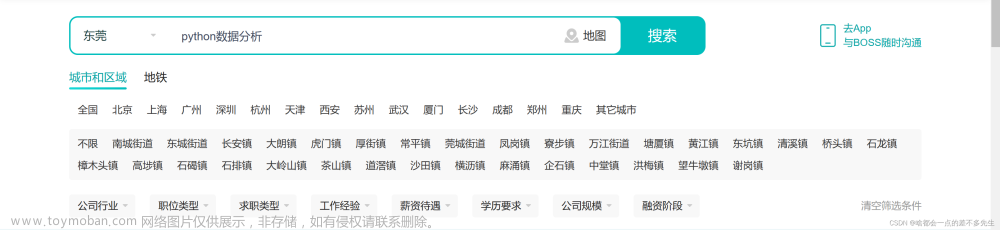
Python网络爬虫爬取招聘数据(利用python简单零基础)可做可视化
身为一个求职者,或者说是对于未来的职业规划还没明确目标的大学生来说,获取各大招聘网上的数据对我们自身的发展具有的帮助作用,本文章就简答零基础的来介绍一下如何爬取招聘数据。 我们以东莞的Python数据分析师这个职位来做一个简单的分析,页面如下图所示:
-
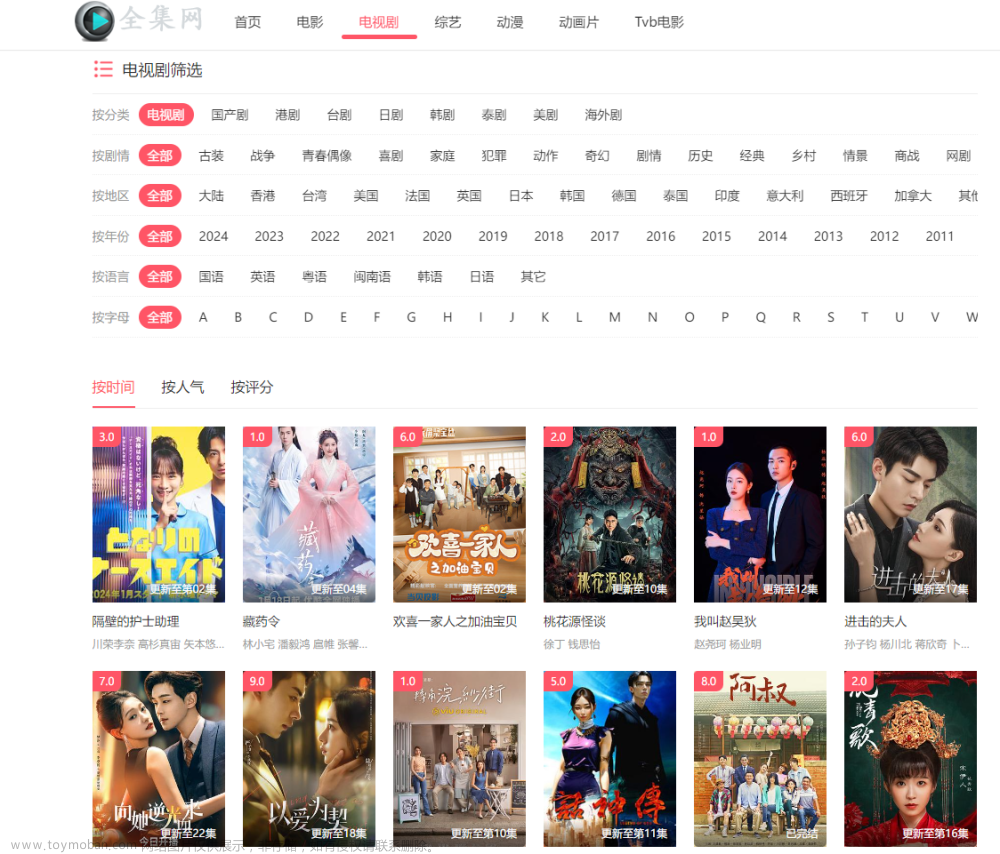
快乐学Python,使用爬虫爬取电视剧信息,构建评分数据集
在前面几篇文章中,我们了解了Python爬虫技术的三个基础环节:下载网页、提取数据以及保存数据。 这一篇文章,我们通过实际操作来将三个环节串联起来,以国产电视剧为例,构建我们的电视剧评分数据集。 收集目前国产电视剧的相关数据,需要构建国产电视剧和评分的