爬取文本数据
-
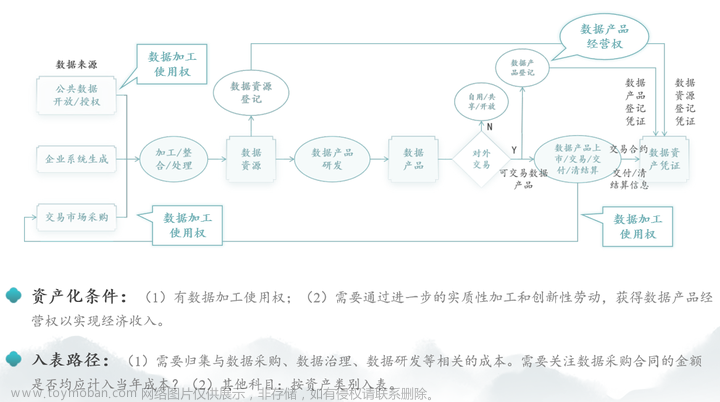
爬取的数据可以入表吗?怎样入表?
合规是数据入表的前提。当前爬虫数据是非常敏感的,因为爬虫极容易造成两大不合规的问题:一是没有经过个人同意获取数据,二是爬取的数据里可能含有个人敏感信息也是一个问题。现在法律对于这部分非常严苛,如果企业里有50条未获得授权的个人信息就已经处于高危
-
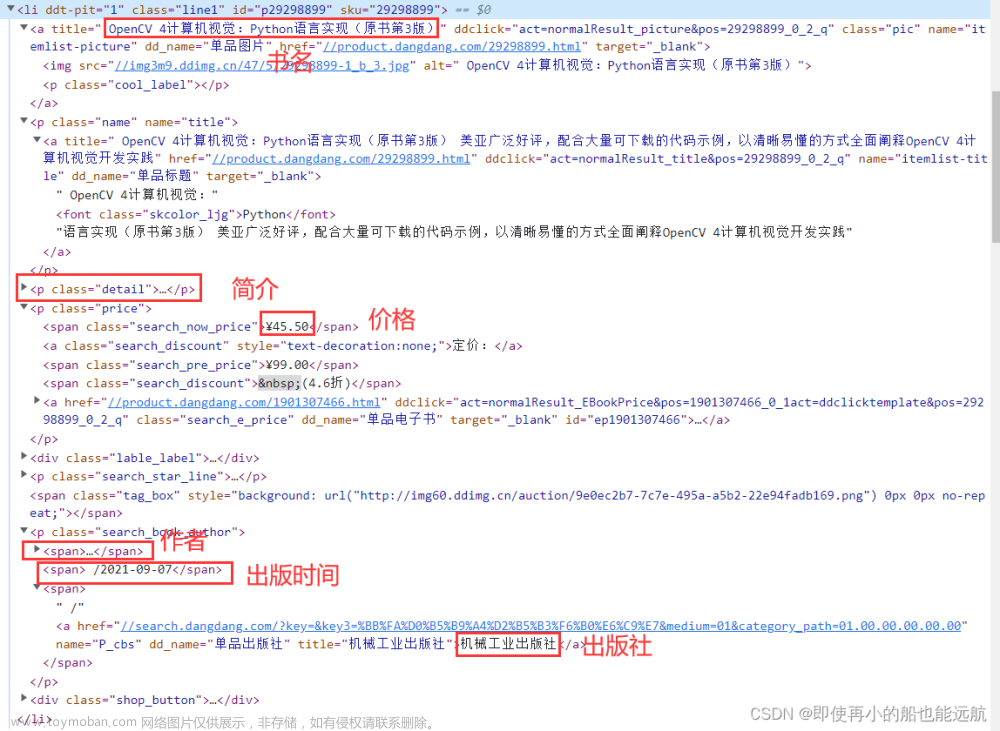
【爬虫】4.5 实践项目——爬取当当网站图书数据
目录 1. 网站图书数据分析 2. 网站图书数据提取 3. 网站图书数据爬取 (1)创建 MySQL 数据库 (2)创建 scrapy 项目 (3)编写 items.py 中的数据项目类 (4)编写 pipelines_1.py 中的数据处理类 (5)编写 pipelines_2.py 中的数据处理类 (6)编写 Scrapy 的配置文件 (7)编写 Scrapy 爬虫程
-

使用selenium爬取猫眼电影榜单数据
近年来,随着互联网的快速发展和人们对电影需求的增加,电影市场也变得日趋繁荣。作为观众或者投资者,我们时常需要了解最新的电影排行榜和票房情况。本文将介绍如何使用Python编写一个爬虫脚本,通过Selenium库自动化操作浏览器,爬取猫眼电影榜单数据,并保存为E
-

淘宝资源采集(从零开始学习淘宝数据爬取)
1. 为什么要进行淘宝数据爬取? 淘宝数据爬取是指通过自动化程序从淘宝网站上获取数据的过程。这些数据可以包括商品信息、销售数据、评论等等。淘宝数据爬取可以帮助您了解市场趋势、优化您的产品选择以及提高销售额。 淘宝作为全球的电商平台,每天都有数以百万
-

Python爬取天气数据并进行分析与预测
随着全球气候的不断变化,对于天气数据的获取、分析和预测显得越来越重要。本文将介绍如何使用Python编写一个简单而强大的天气数据爬虫,并结合相关库实现对历史和当前天气数据进行分析以及未来趋势预测。 1 、数据源选择 选择可靠丰富的公开API或网站作为我们所需的
-
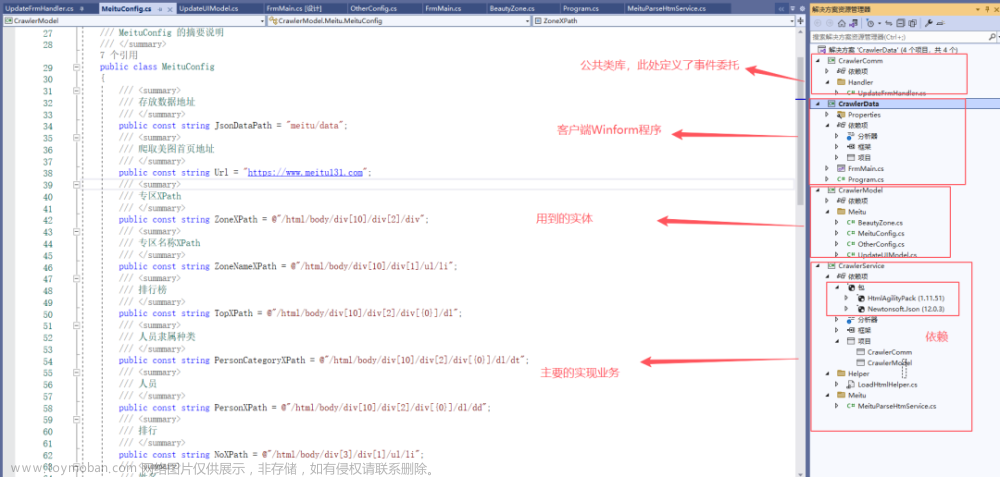
.NET爬取美图官网首页数据实战
在当今信息化社会,网络数据分析越来越受到重视。而作为开发人员,掌握一门能够抓取网页内容的语言显得尤为重要。在此篇文章中,将分享如何使用 .NET构建网络抓取工具。详细了解如何执行 HTTP 请求来下载要抓取的网页,然后从其 DOM 树中选择 HTML 元素,进行匹配需要的
-
基于Python的bilibili会员购数据爬取
一、确定好需要爬取的网站 二、右键检查网页源码,找到所需要爬取的数据所在的位置 通过分析链接可得所需要爬取的数据都在这个页面,并且通过链接可以看到不通的页面page和不通的类型type之间都有差别,可以通过这些差别来爬取不同页面或不同类型的数据
-

Python爬取猫眼电影票房 + 数据可视化
对猫眼电影票房进行爬取,首先我们打开猫眼 接着我们想要进行数据抓包,就要看网站的具体内容,通过按F12,我们可以看到详细信息。 通过两个对比,我们不难发现 User-Agent 和 signKey 数据是变化的(平台使用了数据加密) 所以我们需要对User-Agent与signKey分别进行解密。 通
-
使用Python进行Facebook数据爬取教程
在本教程中,我们将探讨如何使用Python爬取Facebook数据。我们将使用Python的 requests 库和 BeautifulSoup 库进行网络请求和网页解析。请注意,根据Facebook的服务条款,爬取其数据可能会违反其政策。本教程仅用于学术目的,不建议用于商业用途。 环境准备 获取访问令牌 使用Face
-
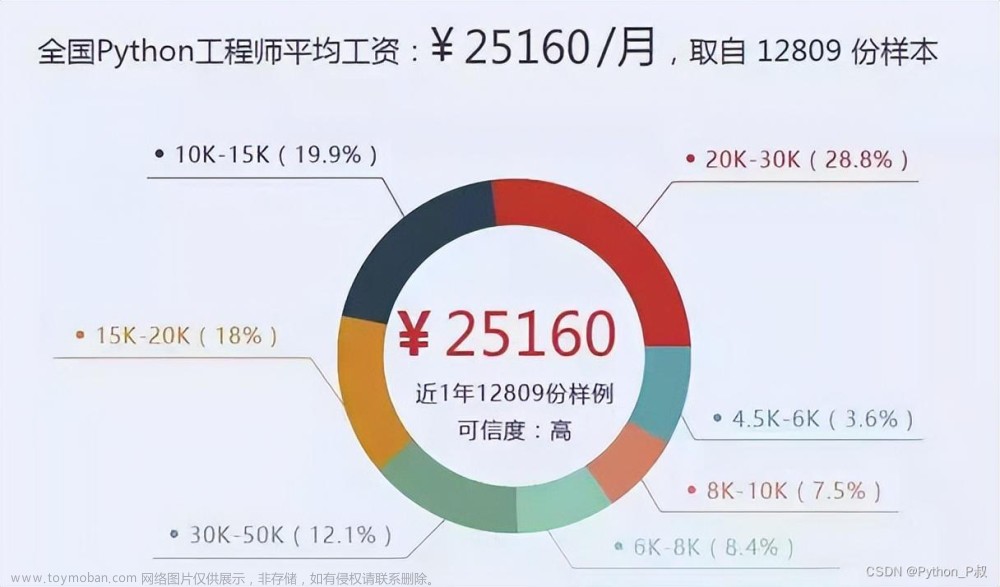
Python 爬虫:如何用 BeautifulSoup 爬取网页数据
在网络时代,数据是最宝贵的资源之一。而爬虫技术就是一种获取数据的重要手段。Python 作为一门高效、易学、易用的编程语言,自然成为了爬虫技术的首选语言之一。而 BeautifulSoup 则是 Python 中最常用的爬虫库之一,它能够帮助我们快速、简单地解析 HTML 和 XML 文档,从而
-
Python爬虫:如何使用Python爬取网站数据
更新:2023-08-13 15:30 想要获取网站的数据?使用Python爬虫是一个绝佳的选择。Python爬虫是通过自动化程序来提取互联网上的信息。本文章将会详细介绍Python爬虫的相关技术。 在使用Python爬虫之前,我们需要理解网络协议和请求。HTTP是网络传输的重要协议,它是在Web浏览器和
-

【小白必看】Python爬取NBA球员数据示例
使用 Python 爬取 NBA 球员数据的示例代码。通过发送 HTTP 请求,解析 HTML 页面,然后提取出需要的排名、姓名、球队和得分信息,并将结果保存到文件中。 使用 requests 库发送HTTP请求。 使用 lxml 库进行HTML解析。 设置请求头信息,包括用户代理(User-Agent)。 设置请求的地址为
-
【爬虫】2.6 实践项目——爬取天气预报数据
在中国天气网(天气网)中输入一个城市的名称,例如输入深圳,那么会转到地址深圳天气预报,深圳7天天气预报,深圳15天天气预报,深圳天气查询的网页显示深圳的天气预报,其中101280601是深圳的代码,每个城市或者地区都有一个代码。如下图: 在上图中可以看到,深圳今天,
-
Selenium实战案例之爬取js加密数据
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。这个工具的主要功能包括:测试与浏览器的兼容性——测试应用程序看是否能够很好得
-

前端远原生js爬取数据的小案例
注意分页的字段需要在代码里面定制化修改,根据你爬取的接口,他的业务规则改代码中的字段。比如我这里总条数叫total,人家的不一定。返回的数据我这里是data.rows,看看人家的是叫什么字段,改改代码。再比如我这里的分页叫pageNum,人家的可能叫pageNo 分页下载 开始在
-
Java基于API接口爬取淘宝商品数据
随着互联网的普及和电子商务的快速发展,越来越多的商家选择在淘宝等电商平台上销售商品。对于开发者来说,通过API接口获取淘宝商品数据,可以更加便捷地进行数据分析和商业决策。本文将介绍如何使用Java基于淘宝API接口爬取商品数据,包括请求API、解析JSON数据、存
-

python爬取boss直聘数据(selenium+xpath)
以boss直聘为目标网站,主要目的是爬取下图中的所有信息,并将爬取到的数据进行持久化存储。(可以存储到数据库中或进行数据可视化分析用web网页进行展示,这里我就以csv形式存在了本地) python3.8 pycharm Firefox 环境安装: pip install selenium 版本对照表(火狐的) https://firefox-s
-
爬取微博热搜榜并进行数据分析
:爬取微博热搜榜数据。 用requests库访问页面用get方法获取页面资源,登录页面对页面HTML进行分析,用beautifulsoup库获取并提取自己所需要的信息。再讲数据保存到CSV文件中,进行数据清洗,数据可视化分析,绘制数据图表,并用最小二乘法进行拟合分析。 :通过观察页面HT
-

爬虫爬取黑马程序员论坛的网页数据
输入完成后运行将会是这样: 例如: 输入起始页码\\\"1\\\" 结束页码\\\"6\\\" 那么将会保存1—6页的网络代码 保存后也页面可以本地文件夹中查看 打开任意一个本地网页文件,将可以看到论坛上对应的内容 这样看来是不是很简单呢
-

Python爬虫|使用Selenium轻松爬取网页数据
1. 什么是selenium? Selenium是一个用于Web应用程序自动化测试工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作浏览器一样。支持的浏览器包括IE,Firefox,Safari,Chrome等。 Selenium可以驱动浏览器自动执行自定义好的逻辑代码,也就是可以通过代码完全模拟成人类使用