爬取文本数据
-

Python--爬取天气网站天气数据并进行数据分析
目的:从天气网站中爬取数据,生成excel表格,里面存储南昌市近十一年的天气情况,并对爬取产生的数据进行数据分析。 第一步:编写代码进行数据爬取 首先,导入 requests 模块,并调用函数 requests.get(),从天气的网站上面获 取该函数所需要的各种参数,然后对里面的参
-

Python爬虫入门:使用selenium库,webdriver库模拟浏览器爬虫,模拟用户爬虫,爬取网站内文章数据,循环爬取网站全部数据。
*严正声明:本文仅限于技术讨论与分享,严禁用于非法途径。 目录 准备工具: 思路: 具体操作: 调用需要的库: 启动浏览器驱动: 代码主体: 完整代码(解析注释): Python环境; 安装selenium库; Python编辑器; 待爬取的网站; 安装好的浏览器; 与浏览器版本相对应的
-
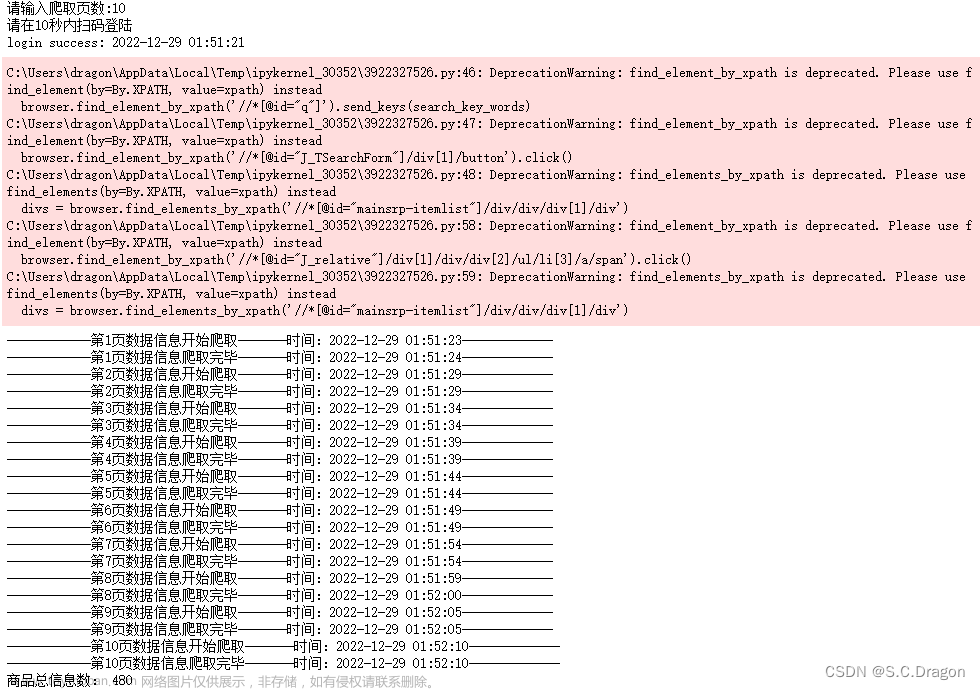
selenium自动翻页爬取数据信息
运行结果: 运行结果:
-
Python定时爬取东方财富行情数据
学习主要内容:使用Python定时在非节假日爬取东方财富股行情数据存入数据库中, 东方财富行情中心网地址如下: http://quote.eastmoney.com/center/gridlist.html#hs_a_board 东方财富行情中心网地址 通过点击该网站的下一页发现,网页内容在变化,但是网站的 URL 却不变,说明这里使用了
-
python爬取网站数据(含代码和讲解)
提示:本次爬取是利用xpath进行,按文章的顺序走就OK的; 文章目录 前言 一、数据采集的准备 1.观察url规律 2.设定爬取位置和路径(xpath) 二、数据采集 1. 建立存放数据的dataframe 2. 开始爬取 3. 把数据导出成csv表格 总结 这次爬取的网站是房天下网站; 其中包含很多楼盘信息
-

如何使用Ruby 多线程爬取数据
现在比较主流的爬虫应该是用python,之前也写了很多关于python的文章。今天在这里我们主要说说ruby。我觉得ruby也是ok的,我试试看写了一个爬虫的小程序,并作出相应的解析。 Ruby中实现网页抓取,一般用的是mechanize,使用非常简单。 首先安装sudo gem install mechanize 然后抓取网
-
Python实战:用Selenium爬取网页数据
网络爬虫是Python编程中一个非常有用的技巧,它可以让您自动获取网页上的数据。在本文中,我们将介绍如何使用Selenium库来爬取网页数据,特别是那些需要模拟用户交互的动态网页。 Selenium是一个自动化测试工具,它可以模拟用户在浏览器中的操作,比如点击按钮、填写表
-
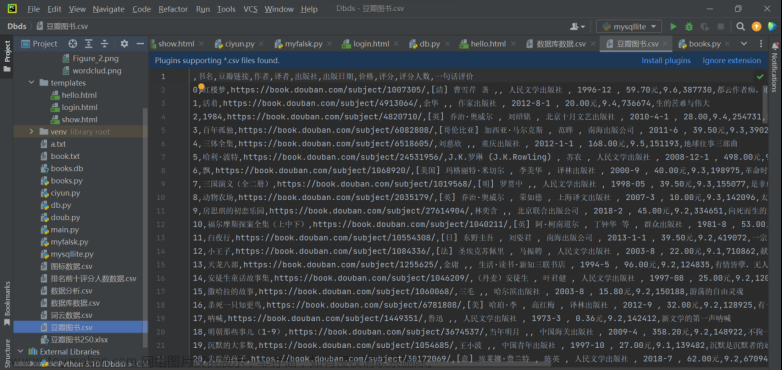
豆瓣读书网站的数据爬取与分析
目录 Python应用程序设计 豆瓣读书网站的数据爬取与分析 一、 项目背景与需求分析 二、数据抓取与分析 三、数据库设计 四、展示系统 选题背景 本设计作品选取了豆瓣读书网站,主要爬取的是豆瓣读书的TOP250,通过爬取的数据进行对信息的进一步的数据分析。豆瓣读书TOP25
-
【爬虫】4.3 Scrapy 爬取与存储数据
目录 1. 建立 Web 网站 2. 编写数据项目类 3. 编写爬虫程序 MySpider 4. 编写数据管道处理类 5. 设置 Scrapy 的配置文件 从一个网站爬取到数据后,往往要存储数据到数据库中,scrapy 框架有十分方便的存储方法,为了说明这个存储过程,首先建立一个简单的网站,然后写
-

X书打击爬取平台数据行为
7月8日,X书宣布正式对蝉妈妈、艺恩星数、常州积奇等几家公司提起民事诉讼,称这些公司利用不正当技术手段爬取小红书平台信息内容及数据,同时对爬取后的数据内容进行存储、加工并予以商业化利用,损害了用户及小红书公司的合法权益。请求法院责令其立即停止上
-

如何使用JS逆向爬取网站数据
引言: JS逆向是指利用编程技术对网站上的JavaScript代码进行逆向分析,从而实现对网站数据的抓取和分析。这种技术在网络数据采集和分析中具有重要的应用价值,能够帮助程序员获取网站上的有用信息,并进行进一步的处理和分析。 基础知识: JavaScript解析引擎是爬虫JS逆
-
用Scrapy和Selenium爬取动态数据
文章参考千锋教育大佬的课程: https://www.bilibili.com/video/BV1QY411F7Vt?p=1vd_source=5f425e0074a7f92921f53ab87712357b ,多谢大佬的课程 因为TB网的搜索功能需要登录之后才能使用,所以我们要通过程序去控制浏览器实现登录功能,然后再获取登录之后的Cookie. 首先创建一个Chrome浏览
-
用Python实现对Ajax数据爬取
爬取Ajax数据通常涉及到模拟浏览器行为,因为Ajax(Asynchronous JavaScript and XML)是一种在浏览器端与服务器之间进行异步通信的技术。传统的网页爬虫方法(如 requests 库)通常无法直接获取Ajax请求的数据,因为这些数据是动态加载的,并不直接包含在HTML页面中。 为了爬取Aj
-
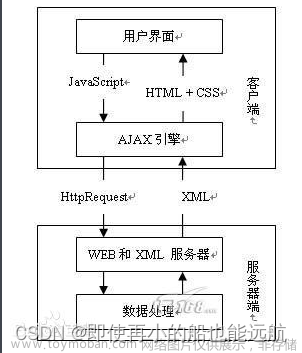
【爬虫】5.5 Selenium 爬取Ajax网页数据
目录 AJAX 简介 任务目标 创建Ajax网站 创建服务器程序 编写爬虫程序 AJAX(Asynchronous JavaScript And XML,异步 JavaScript 及 XML) Asynchronous 一种创建 交互式 、 快速动态 网页应用的网页开发技术 通过在后台与服务器进行少量数据交换,无需重新加载整个网页的情况下
-
数据分析4 -- 将爬取的数据保存成CSV格式
什么是 CSV 文件 CSV(Comma-Separated Values) 是一种使用逗号分隔来实现存储表格数据的文本文件。 我们都知道表格有多种形式的存储,比如 Excel 的格式或者数据库的格式。CSV 文件也可以存储表格数据,并且能够被多种软件兼容,比如 Excel 就能直接打开 CSV 文件的表格,很多数
-
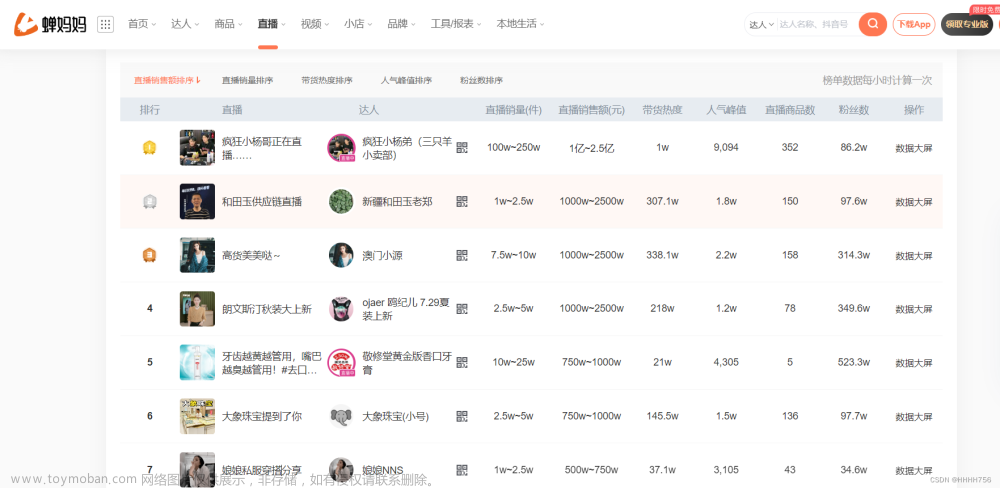
爬虫——有关抖音商品数据的爬取(蝉妈妈数据平台)
抖音带货的兴起,让抖音电商一跃成为与淘宝电商、京东电商等电商平台共同争夺电商市场的存在,与淘宝电商、京东电商等电商平台相比,抖音电商拥有独特的优势,抖音以短视频的形式能够带来巨大的流量和热度,抖音以此为基础带来全新的带货方式——短视频带货,除
-
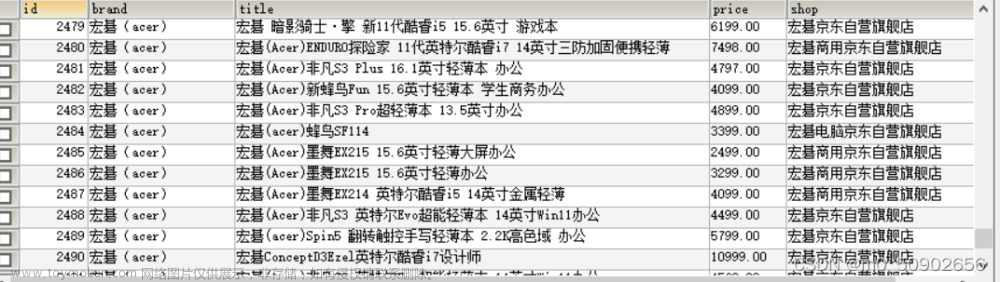
爬虫案例—京东数据爬取、数据处理及数据可视化(效果+代码)
使用PyCharm(引用requests库、lxml库、json库、time库、openpyxl库和pymysql库)爬取京东网页相关数据(品牌、标题、价格、店铺等) 数据展示(片段): 京东网页有反爬措施,需要自己在网页登录后,获取cookie,加到请求的header中(必要时引入time库,设置爬取
-
淘宝商品数据爬取商品信息采集数据分析API接口
数据采集是数据可视化分析的第一步,也是最基础的一步,数据采集的数量和质量越高,后面分析的准确的也就越高,我们来看一下淘宝网的数据该如何爬取。 点此获取淘宝API测试key密钥 淘宝网站是一个动态加载的网站,我们之前可以采用解析接口或者用Selenium自动化
-

使用Selenium和bs4进行Web数据爬取和自动化(爬取掘金首页文章列表)
2024软件测试面试刷题,这个小程序(永久刷题),靠它快速找到工作了!(刷题APP的天花板)_软件测试刷题小程序-CSDN博客 文章浏览阅读2.9k次,点赞85次,收藏12次。你知不知道有这么一个软件测试面试的刷题小程序。里面包含了面试常问的软件测试基础题,web自动化测试、
-
Selenium实战案例之爬取js加密数据
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera,Edge等。这个工具的主要功能包括:测试与浏览器的兼容性——测试应用程序看是否能够很好得