python爬虫爬取图片
-
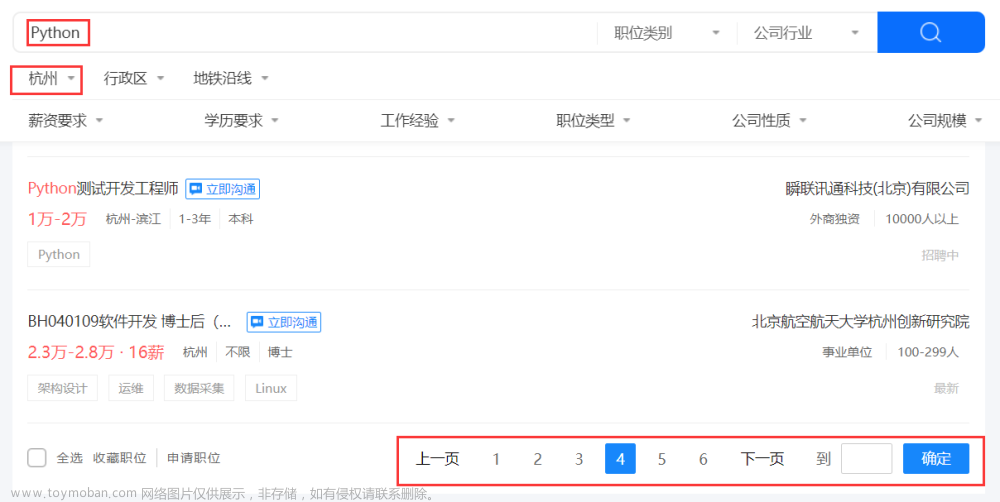
【爬虫系列】Python爬虫实战--招聘网站的职位信息爬取
1. 需求分析 从网上找工作,大家一般都会通过各种招聘网站去检索相关信息,今天利用爬虫采集招聘网站的职位信息,比如岗位名称,岗位要求,薪资,公司名称,公司规模,公司位置,福利待遇等最为关心的内容。在采集和解析完成后,使用 Excel 或 csv 文件保存。 2. 目标
-
使用python爬虫爬取bilibili视频
可以使用 Python 爬虫框架如 Scrapy 来爬取 Bilibili 的视频。首先需要了解 Bilibili 网站的构造,包括数据是如何呈现的,然后构建请求来获取所需的数据。同时需要考虑反爬虫措施,可能需要使用代理 IP 和 User-Agent 等方法来绕过反爬虫机制。 这里提供一个简单的爬取视频标题的
-

Python爬虫—爬取微博评论数据
今日,分享编写Python爬虫程序来实现微博评论数据的下载。 具体步骤如下👇👇👇: Step1 :电脑访问手机端微博_https://m.weibo.cn/_ Step2 :打开一条微博_https://m.weibo.cn/detail/4907031376694279_ Step3 :URL地址中的_49070__31376694279_就是需要爬取的微博ID Step4 :将ID填写到_main_下即可,也支
-
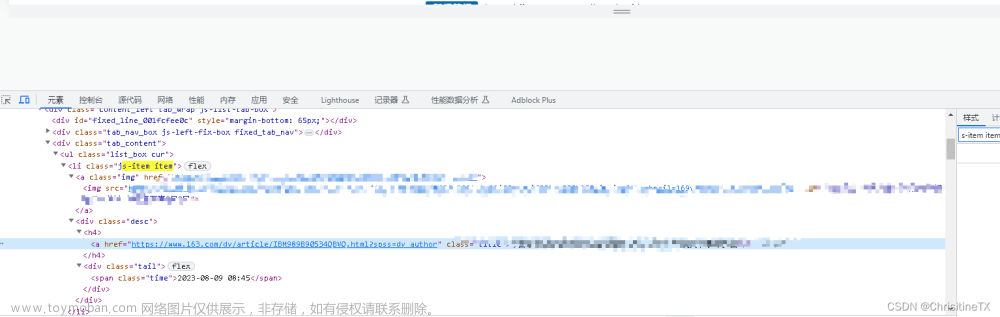
python爬虫实战(1)--爬取新闻数据
想要每天看到新闻数据又不想占用太多时间去整理,萌生自己抓取新闻网站的想法。 使用python语言可以快速实现,调用 BeautifulSoup 包里面的方法 安装BeautifulSoup 完成以后引入项目 定义请求头,方便把请求包装成正常的用户请求,防止被拒绝 定义被抓取的url,并请求加上请求
-
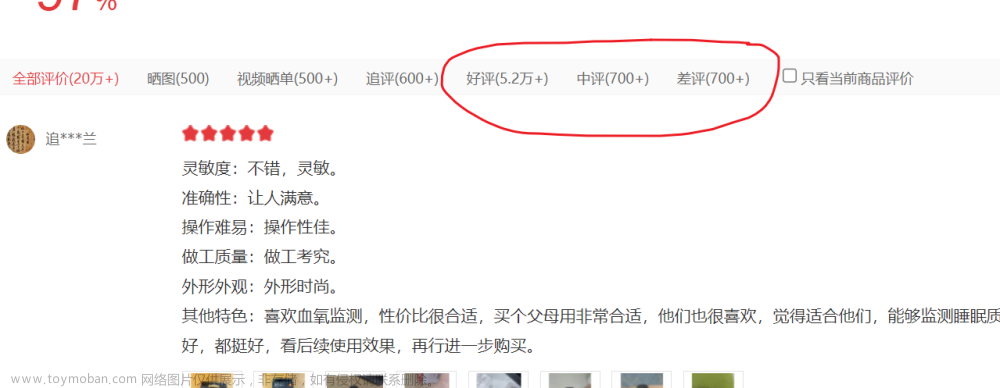
爬虫——python爬取京东商品用户评价
以小米手环7为例,分别爬取小米手环7用户评价中的好评、中评、差评 使用工具:PyCharm Community 需要python库:requests 安装方法:File--Settings--Project --Python Interpreter 代码如下: 好评: 中评: 差评: 其中重要参数来源: 打开开发者工具,快捷键F12键,或鼠标右键--检查--网络
-
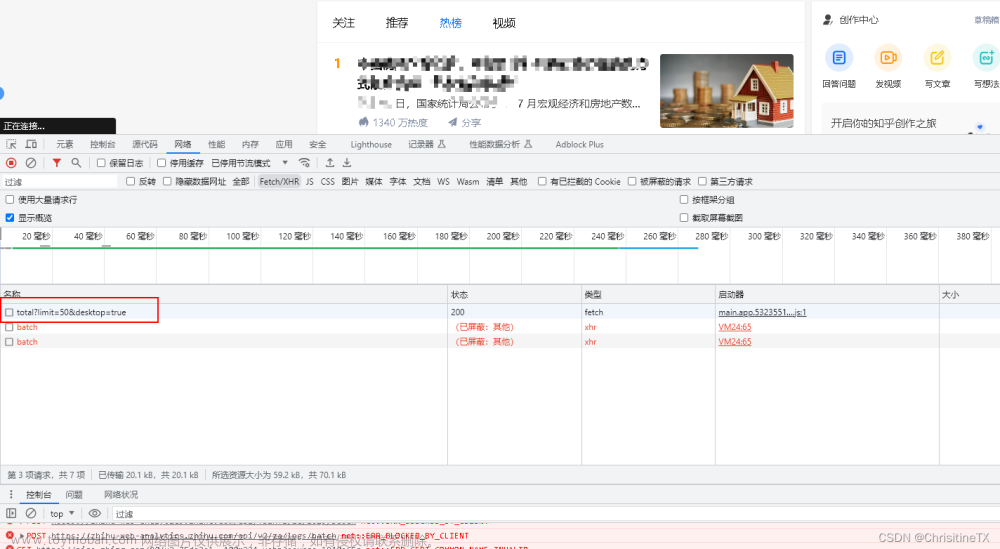
python爬虫实战(3)--爬取某乎热搜
1. 分析爬取地址 打开某乎首页,点击热榜 这个就是我们需要爬取的地址,取到地址 某乎/api/v3/feed/topstory/hot-lists/total?limit=50desktop=true 定义好请求头,从Accept往下的请求头全部复制,转换成json 2. 分析请求结果 通过请求可以看出, hot-lists/total?limit=50desktop=true 请求后的返回参数
-
《python爬虫练习2》爬取网站表情包
运行环境: 1.分析: 目标网址:https://www.runoob.com/ 首先想要获取什么就从哪里入手,打开图所在的网页,F12查看代码的内容,此处抓取的是资源文件,爬取中发现ajax类型的文件加载出来的无法知道图片的源地址所以暂时不能用这种方式获取。因此可以生成第一步的代码。
-
爬虫学习记录之Python 爬虫实战:爬取研招网招生信息详情
【简介】本篇博客 为爱冲锋 ,爬取北京全部高校的全部招生信息,最后持久化存储为表格形式,可以用作筛选高校。 此处导入本次爬虫所需要的全部依赖包分别是以下内容,本篇博客将爬取研招网北京所有高校的招生信息,主要爬取内容为学校,考试方式,所在学院,专业
-

Python爬虫入门:使用selenium库,webdriver库模拟浏览器爬虫,模拟用户爬虫,爬取网站内文章数据,循环爬取网站全部数据。
*严正声明:本文仅限于技术讨论与分享,严禁用于非法途径。 目录 准备工具: 思路: 具体操作: 调用需要的库: 启动浏览器驱动: 代码主体: 完整代码(解析注释): Python环境; 安装selenium库; Python编辑器; 待爬取的网站; 安装好的浏览器; 与浏览器版本相对应的
-
用python爬取某个图片网站的图片
1、爬取单张图片 2、爬取批量图片 3、如果一个网页的图片很多,可以进行分页爬取
-
![[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频](https://imgs.yssmx.com/Uploads/2024/04/855397-1.png)
[爬虫篇]Python爬虫之爬取网页音频_爬虫怎么下载已经找到的声频
audio_DATA_get = requests.get(url=audio_DATA,headers=headers) audio_DATA_get_text = audio_DATA_get.text audio_DATA_download_url = re.findall(‘“src”:“(.*?)”’,audio_DATA_get_text) print(audio_DATA_download_url) download_data_url = audio_DATA_download_url[0] try: open_download_data_url = urllib.request.urlopen(download_data_url) except: print(downlo
-
Python爬取pexels图片
研究Python爬虫,网上很多爬取pexels图片的案例,我下载下来运行没有成功,总量有各种各样的问题。 作为菜鸟初学者,网上的各个案例代码对我还是有不少启发作用,我用搜索引擎+chatGPT逐步对代码进行了完善。 最终运行成功。特此记录。 运行环境:Win10,Python3.10、 Google
-
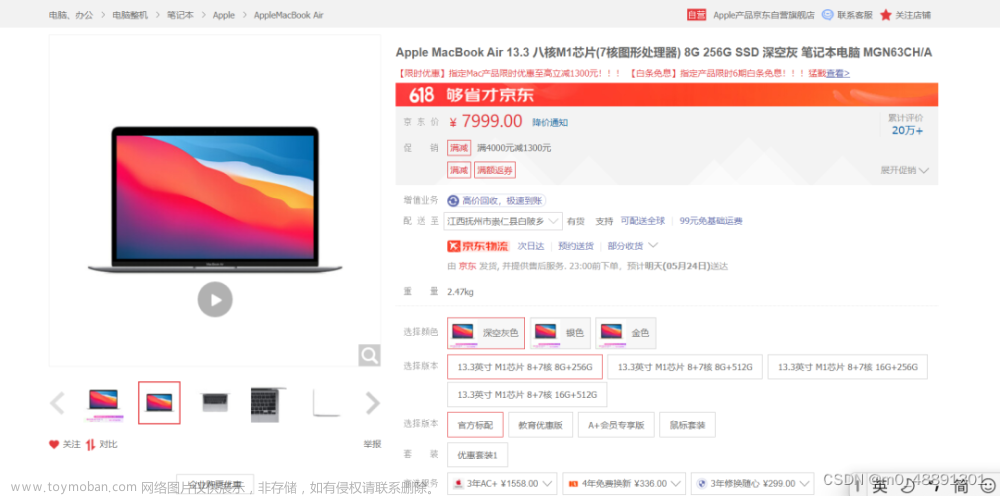
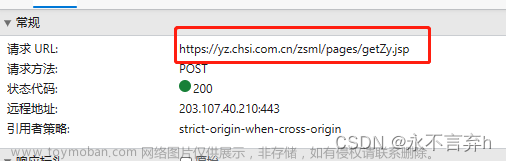
Python如何运用爬虫爬取京东商品评论
打开京东商品网址(添加链接描述) 查看商品评价 。我们点击评论翻页,发现网址未发生变化,说明该网页是动态网页。 我们在 浏览器右键点击“检查” ,,随后 点击“Network” ,刷新一下,在搜索框中 输入”评论“ ,最终找到 网址(url) 。我们点击Preview,发现了我们需要
-
Python爬虫实战入门:爬取360模拟翻译(仅实验)
需求 目标网站: https://fanyi.so.com/# 要求:爬取360翻译数据包,实现翻译功能 所需第三方库 requests 简介 requests 模块是 python 基于 urllib,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。 安装 pip install -i https://py
-
Python应用-爬虫实战-求是网周刊文章爬取
任务描述 本关任务:编写一个爬虫,并使用正则表达式获取求是周刊 2019 年第一期的所有文章的 url 。详情请查看《求是》2019年第1期 。 相关知识 获取每个新闻的 url 有以下几个步骤: 首先获取 2019 年第 1 期页面的源码,需要解决部分反爬机制; 找到目标 url 所在位置,观
-
Python 爬虫:如何用 BeautifulSoup 爬取网页数据
在网络时代,数据是最宝贵的资源之一。而爬虫技术就是一种获取数据的重要手段。Python 作为一门高效、易学、易用的编程语言,自然成为了爬虫技术的首选语言之一。而 BeautifulSoup 则是 Python 中最常用的爬虫库之一,它能够帮助我们快速、简单地解析 HTML 和 XML 文档,从而
-

Python爬虫:从后端分析为什么你爬虫爬取不到数据
仅仅是小编总结的三点而已,可能不是很全面,如果之后小编了解到新的知识点,可能还会增加的哈! 1. 最简单的爬虫代码 也就是各位最常使用的,直接利用requests模块访问当前网站链接,利用相关解析模块从而获取得到自己想要的数据,如下(利用python爬虫爬取自己csdn个人
-
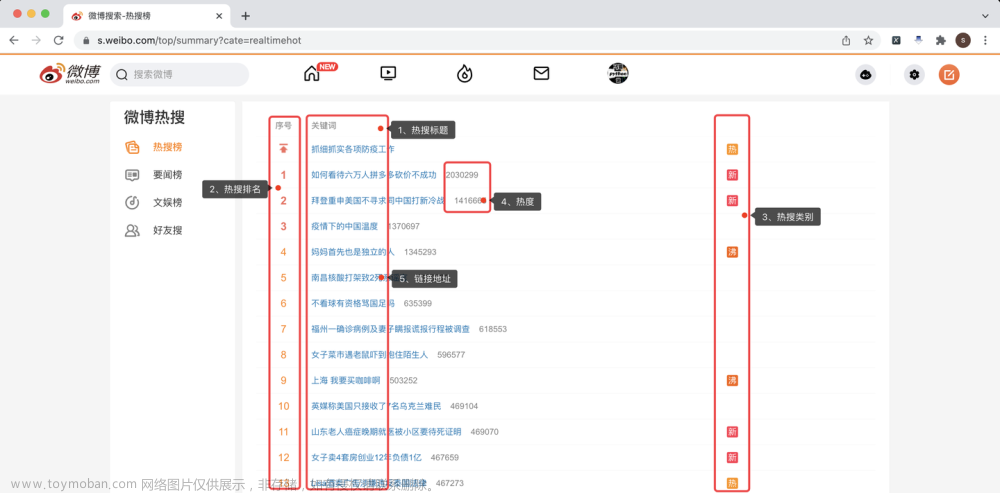
【经典爬虫案例】用Python爬取微博热搜榜!
目录 一、爬取目标 二、编写爬虫代码 2.1 前戏 2.2 获取cookie 2.3 请求页面 2.4 解析页面 2.5 转换热搜类别 2.6 保存结果 2.7 查看结果数据 三、获取完整源码 您好,我是@马哥python说,一名10年程序猿。 本次爬取的目标是: 微博热搜榜 分别爬取每条热搜的: 热搜标题、热搜排名
-
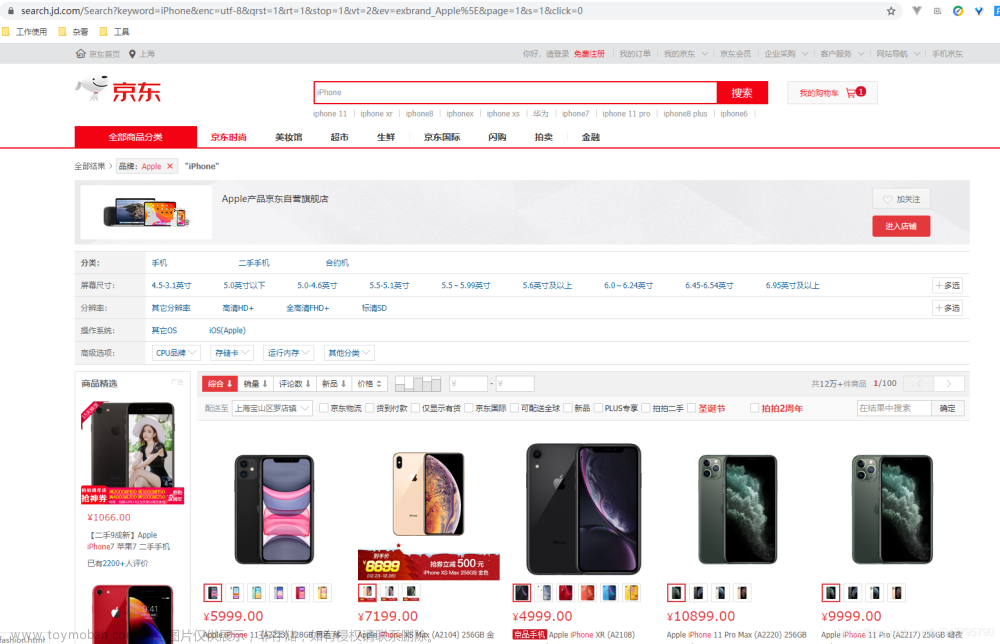
Python爬虫实战:selenium爬取电商平台商品数据
目标 先介绍下我们本篇文章的目标,如图: 本篇文章计划获取商品的一些基本信息,如名称、商店、价格、是否自营、图片路径等等。 准备 首先要确认自己本地已经安装好了 Selenium 包括 Chrome ,并已经配置好了 ChromeDriver 。如果还没安装好,可以参考前面的前置准备。 分析
-
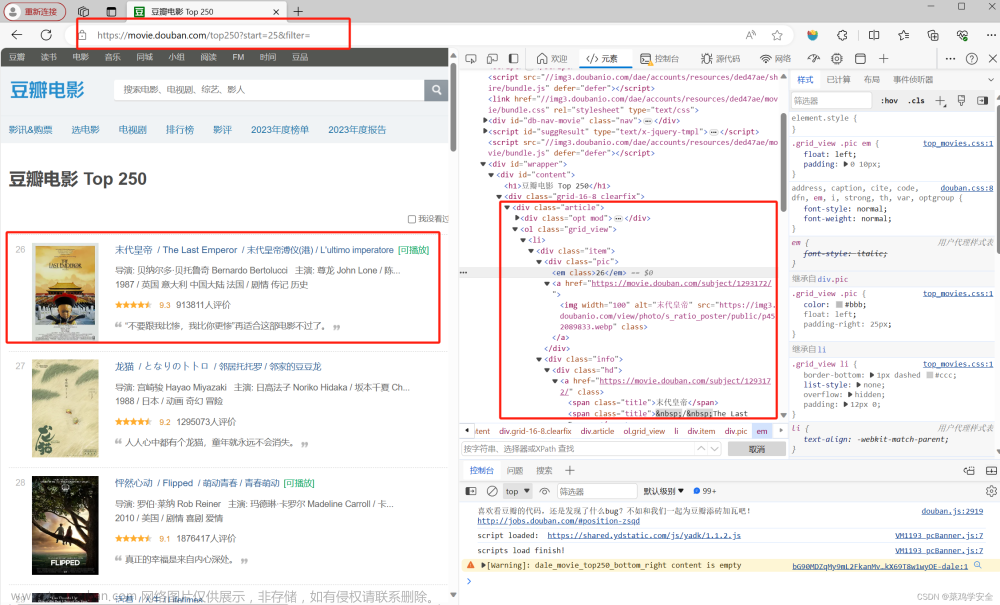
python爬虫小练习——爬取豆瓣电影top250
将爬取的数据导入到表格中,方便人为查看。 三大功能 1,下载所有网页内容。 2,处理网页中的内容提取自己想要的数据 3,导入到表格中 https://www.bilibili.com/video/BV1CY411f7yh/?p=15