python爬虫爬取电影
-
详解爬虫基本知识及入门案列(爬取豆瓣电影《热辣滚烫》的短评 详细讲解代码实现)
目录 前言什么是爬虫? 爬虫与反爬虫基础知识 一、网页基础知识 二、网络传输协议 HTTP(HyperText Transfer Protocol)和HTTPS(HTTP Secure)请求过程的原理? 三、Session和Cookies Session Cookies Session与Cookies的区别与联系 四、Web服务器Nginx 五、代理IP 1、代理IP的原理 2. 分类 3. 获取途
-
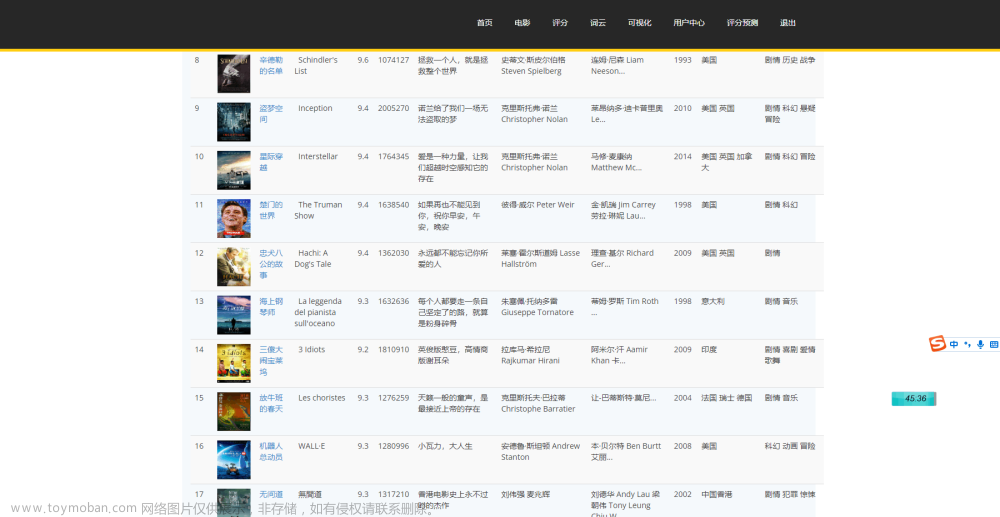
Python爬取豆瓣电影Top 250,豆瓣电影评分可视化,豆瓣电影评分预测系统
博主介绍:✌程序员徐师兄、7年大厂程序员经历。全网粉丝12w+、csdn博客专家、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战✌ 🍅 文末获取源码联系 🍅 👇🏻 精彩专栏推荐订阅👇🏻 不然下次找不到哟 2022-2024年最全的计算机软件毕业设计选
-
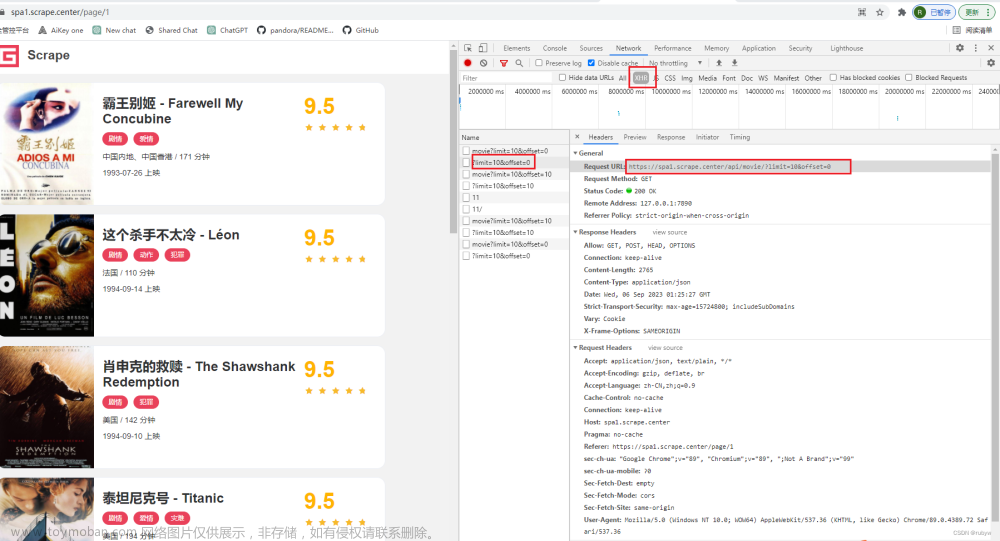
Python爬取电影信息:Ajax介绍、爬取案例实战 + MongoDB存储
Ajax(Asynchronous JavaScript and XML)是一种用于在Web应用程序中实现异步通信的技术。它允许在不刷新整个网页的情况下,通过在后台与服务器进行数据交换,实时更新网页的一部分。Ajax的主要特点包括: 异步通信: Ajax是异步的,这意味着它可以在不阻塞用户界面的情况下进行
-

Python爬取猫眼电影票房 + 数据可视化
对猫眼电影票房进行爬取,首先我们打开猫眼 接着我们想要进行数据抓包,就要看网站的具体内容,通过按F12,我们可以看到详细信息。 通过两个对比,我们不难发现 User-Agent 和 signKey 数据是变化的(平台使用了数据加密) 所以我们需要对User-Agent与signKey分别进行解密。 通
-

用Python爬取电影数据并可视化分析
🤵♂️ 个人主页:@艾派森的个人主页 ✍🏻作者简介:Python学习者 🐋 希望大家多多支持,我们一起进步!😄 如果文章对你有帮助的话, 欢迎评论 💬点赞👍🏻 收藏 📂加关注+ 目录 一、获取数据 1.技术工具 2.爬取目标 3.字段信息 二、数据预处理 1.加载数据 2.异常值
-
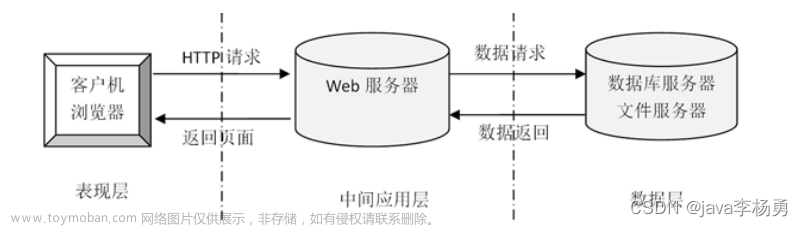
基于Python的电影票房爬取与可视化系统的设计与实现
博主介绍 : ✌ 全网粉丝30W+,csdn特邀作者、博客专家、CSDN新星计划导师、java领域优质创作者,博客之星、掘金/华为云/阿里云/InfoQ等平台优质作者、专注于Java技术领域和毕业项目实战 ✌ 🍅 文末获取源码联系 🍅 👇🏻 精彩专栏 推荐订阅 👇🏻 不然下次找不到哟 java项目
-
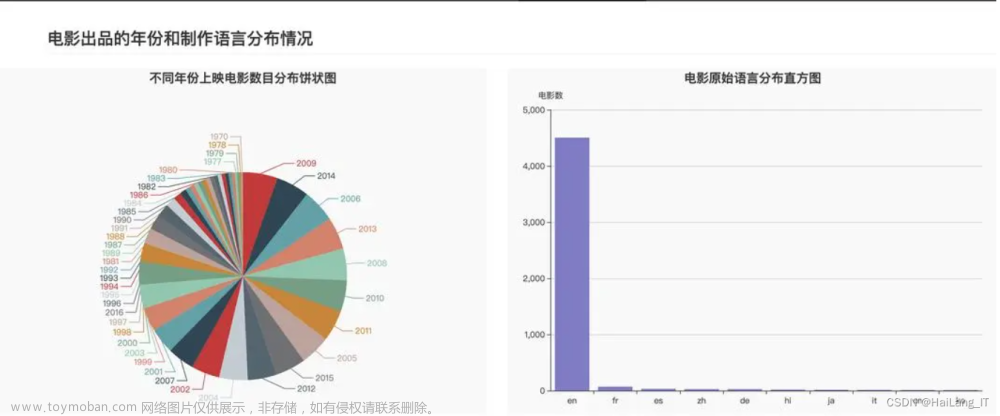
毕业设计-基于大数据的电影爬取与可视化分析系统-python
目录 前言 课题背景和意义 实现技术思路 实现效果图样例 📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学
-
【python】爬取豆瓣电影排行榜TOP250存储到CSV文件中【附源码】
代码首先导入了需要使用的模块:requests、lxml和csv。 如果出现模块报错 进入控制台输入:建议使用国内镜像源 我大致罗列了以下几种国内镜像源: 设置了请求头部信息,以模拟浏览器的请求,函数返回响应数据
-
【python】爬取豆瓣电影排行榜Top250存储到Excel文件中【附源码】
近年来,Python在数据爬取和处理方面的应用越来越广泛。本文将介绍一个基于Python的爬虫程 序,用于抓取豆瓣电影Top250的相关信息,并将其保存为Excel文件。 程序包含以下几个部分: 导入模块:程序导入了 BeautifulSoup、re、urllib.request、urllib
-
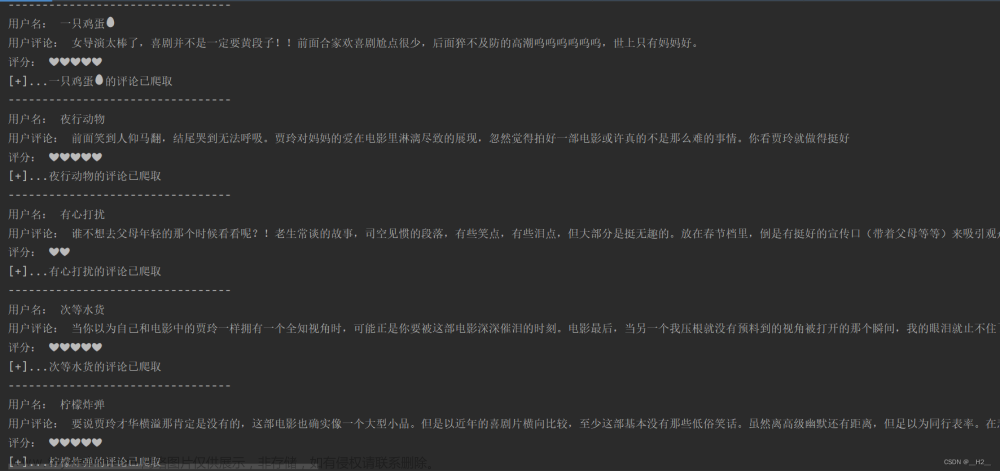
Python爬虫实战——获取电影影评
使用Python爬取指定电影的影评, 注意: 本文 仅用于学习交流 , 禁止用于盈利或侵权行为。 操作系统:windows10 家庭版 开发环境:Pycharm Conmunity 2022.3 解释器版本:Python3.8 第三方库: requests、bs4 需要安装 bs4 和 requests 库 你可以参考我的以下文章获取些许帮助: Python第三方库
-
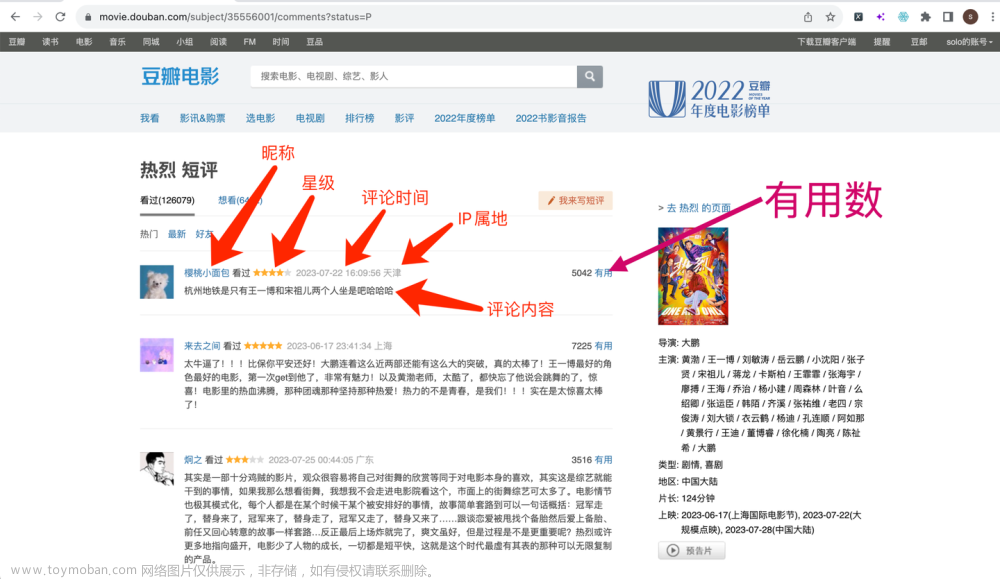
【爬虫实战】用python爬豆瓣电影《热烈》短评
目录 一、爬虫对象-豆瓣电影短评 二、爬取结果 三、爬虫代码讲解 三、演示视频 四、获取完整源码 您好!我是@马哥python说,一名10年程序猿。 今天分享一期爬虫案例,爬取的目标是:豆瓣上任意一部电影的短评(注意:是短评,不是影评!),以《热烈》这部电影为例:
-

六个步骤学会使用Python爬虫爬取数据(爬虫爬取微博实战)
用python的爬虫爬取数据真的很简单,只要掌握这六步就好,也不复杂。以前还以为爬虫很难,结果一上手,从初学到把东西爬下来,一个小时都不到就解决了。 第一步:安装requests库和BeautifulSoup库 在程序中两个库的书写是这样的: 由于我使用的是pycharm进行的python编程。所以
-
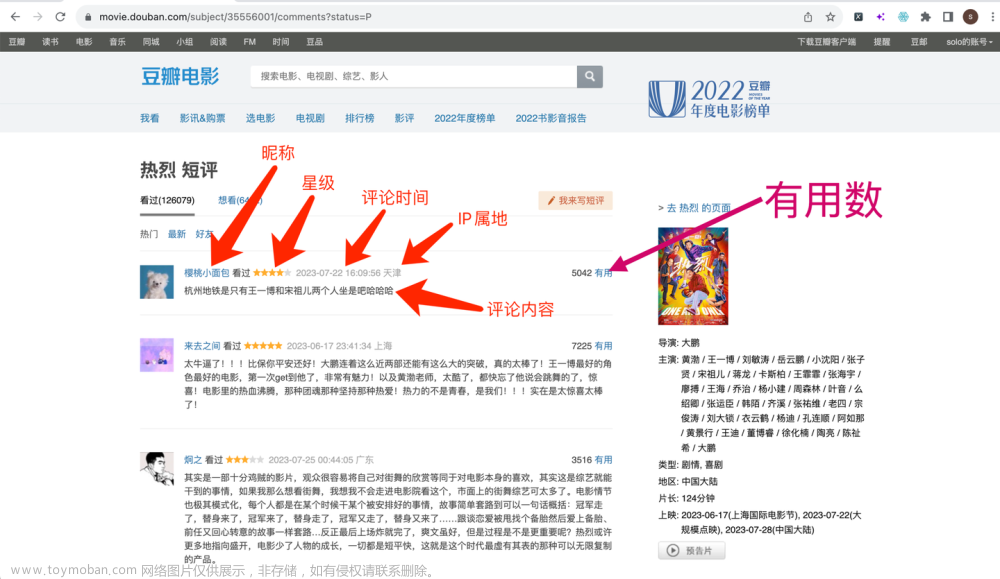
【爬虫实战】用python爬豆瓣电影《热烈》的短评!
您好!我是@马哥python说,一名10年程序猿。 今天分享一期爬虫案例,爬取的目标是:豆瓣上任意一部电影的短评(注意:是短评,不是影评!),以《热烈》这部电影为例: 爬取以上6个段,含: 页码, 评论者昵称, 评论星级, 评论时间, 评论者IP属地, 有用数, 评论内容
-

【python爬虫】—图片爬取
从https://pic.netbian.com/4kfengjing/网站爬取图片,并保存 获取待爬取网页 获取所有图片,并下载 爬取结果展示
-
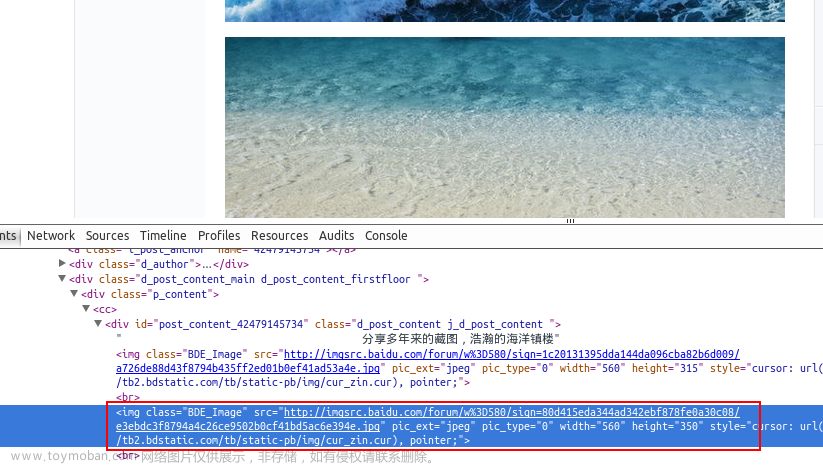
Python爬虫 爬取图片
在我们日常上网浏览网页的时候,经常会看到一些好看的图片,我们就希望把这些图片保存下载,或者用户用来做桌面壁纸,或者用来做设计的素材。 我们最常规的做法就是通过鼠标右键,选择另存为。但有些图片鼠标右键的时候并没有另存为选项,还有办法就通过就是通过
-

【python爬虫】闲鱼爬虫,可以爬取商品
目录 前言 一、介绍 二、爬虫流程 1. 确定并构造URL 2. 发送网络请求 3. 解析HTML并提取数据 4. 保存数据 三、使用代理IP 四、完整代码 五、总结 前言 闲鱼是一个很受欢迎的二手交易平台,但是由于没有开放API,我们需要使用爬虫来获取数据。本文将介绍如何使用Python爬
-

【爬虫】python爬虫爬取网站页面(基础讲解)
👉博__主👈:米码收割机 👉技__能👈:C++/Python语言 👉公众号👈:测试开发自动化【获取源码+商业合作】 👉荣__誉👈:阿里云博客专家博主、51CTO技术博主 👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。 1. 导入必要的库 requests 库用于发送HTTP请
-
【Python 爬虫脚本】Python爬取歌曲
目标:爬取酷狗音乐 右键--检查 进入网络,查看所有请求,事先先清空历史数据 点击刷新,重新进入页面 找到index请求,在预览中可以看到 play_backup_url:\\\"https://webfs.tx.kugou.com/202308251554/97c6fef48119300dd2a238ee8025c521/v2/409ebc56ea4ba76e58d8c89af8d03b6a/KGTX/CLTX001/409ebc56ea4ba76e58d8c89af8d03b6a.
-
python爬虫实战——小说爬取
基于 requests 库和 lxml 库编写的爬虫,目标小说网站域名http://www.365kk.cc/,类似的小说网站殊途同归,均可采用本文方法爬取。 目标网站 :传送门 本文的目标书籍 :《我的师兄实在太稳健了》 “渡劫只有九成八的把握,和送死有什么区别?” 网络爬虫的工作实际上主要分为
-
python 爬虫爬取天气
爬虫5步曲: 1.安装requests and beacutifulsoup4库 2.获取爬虫所需的header 和cookie 3.获取网页,解析网页 4.分析得到的数据简化地址 5.爬取内容,清洗数据 1.安装requestsbeautifulsoup4 pip3 install requests pip3 install beautifulsoup4 2.获取爬虫所需的header 和cookie 打开想爬取的