python爬虫爬取网页数据
-
Python实战:用Selenium爬取网页数据
网络爬虫是Python编程中一个非常有用的技巧,它可以让您自动获取网页上的数据。在本文中,我们将介绍如何使用Selenium库来爬取网页数据,特别是那些需要模拟用户交互的动态网页。 Selenium是一个自动化测试工具,它可以模拟用户在浏览器中的操作,比如点击按钮、填写表
-
scrapy爬虫爬取多网页内容
摘要 :此案例是爬取目标网站( https://tipdm.com/ )的 新闻中心 板块的 公司新闻 中所有新闻的标题、发布时间、访问量和新闻的文本内容。 我使用的是 Anaconda prompt 我们使用如下命令创建scrapy项目: scrapy startproject spider_name 爬虫路径 spider_name 是项目的名字 爬虫路径 就是项目
-

六个步骤学会使用Python爬虫爬取数据(爬虫爬取微博实战)
用python的爬虫爬取数据真的很简单,只要掌握这六步就好,也不复杂。以前还以为爬虫很难,结果一上手,从初学到把东西爬下来,一个小时都不到就解决了。 第一步:安装requests库和BeautifulSoup库 在程序中两个库的书写是这样的: 由于我使用的是pycharm进行的python编程。所以
-
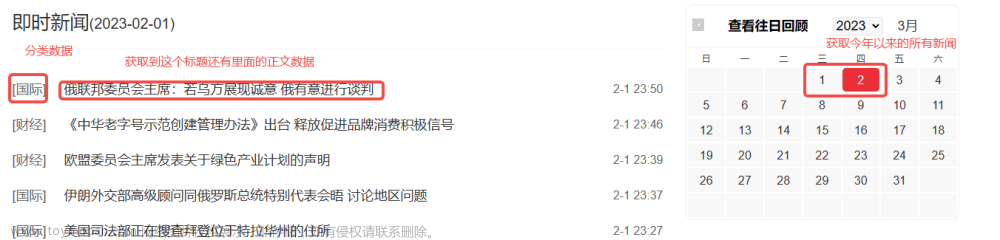
Python爬虫实战——爬取新闻数据(简单的深度爬虫)
又到了爬新闻的环节(好像学爬虫都要去爬爬新闻,没办法谁让新闻一般都很好爬呢XD,拿来练练手),只作为技术分享,这一次要的数据是分在了两个界面,所以试一下深度爬虫,不过是很简单的。 网页url 1.先看看网站网址的规律 发现这部分就是每一天的新闻
-
Python爬虫:如何使用Python爬取网站数据
更新:2023-08-13 15:30 想要获取网站的数据?使用Python爬虫是一个绝佳的选择。Python爬虫是通过自动化程序来提取互联网上的信息。本文章将会详细介绍Python爬虫的相关技术。 在使用Python爬虫之前,我们需要理解网络协议和请求。HTTP是网络传输的重要协议,它是在Web浏览器和
-

Python爬虫—爬取微博评论数据
今日,分享编写Python爬虫程序来实现微博评论数据的下载。 具体步骤如下👇👇👇: Step1 :电脑访问手机端微博_https://m.weibo.cn/_ Step2 :打开一条微博_https://m.weibo.cn/detail/4907031376694279_ Step3 :URL地址中的_49070__31376694279_就是需要爬取的微博ID Step4 :将ID填写到_main_下即可,也支
-
python爬虫实战(1)--爬取新闻数据
想要每天看到新闻数据又不想占用太多时间去整理,萌生自己抓取新闻网站的想法。 使用python语言可以快速实现,调用 BeautifulSoup 包里面的方法 安装BeautifulSoup 完成以后引入项目 定义请求头,方便把请求包装成正常的用户请求,防止被拒绝 定义被抓取的url,并请求加上请求
-
华纳云:Python中如何使用Selenium爬取网页数据
这篇文章主要介绍“Python中如何使用Selenium爬取网页数据”,在日常操作中,相信很多人在Python中如何使用Selenium爬取网页数据问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Python中如何使用Selenium爬取网页数据”的疑惑有所帮助!接下
-

Python爬虫入门:使用selenium库,webdriver库模拟浏览器爬虫,模拟用户爬虫,爬取网站内文章数据,循环爬取网站全部数据。
*严正声明:本文仅限于技术讨论与分享,严禁用于非法途径。 目录 准备工具: 思路: 具体操作: 调用需要的库: 启动浏览器驱动: 代码主体: 完整代码(解析注释): Python环境; 安装selenium库; Python编辑器; 待爬取的网站; 安装好的浏览器; 与浏览器版本相对应的
-

Python商业数据挖掘实战——爬取网页并将其转为Markdown
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家 :https://www.captainbed.cn/z ChatGPT体验地址 在信息爆炸的时代,互联网上的海量文字信息如同无尽的沙滩。然而,其中真正有价值的信息往往埋在各种网页中,需要经过筛选和整理才能被有
-
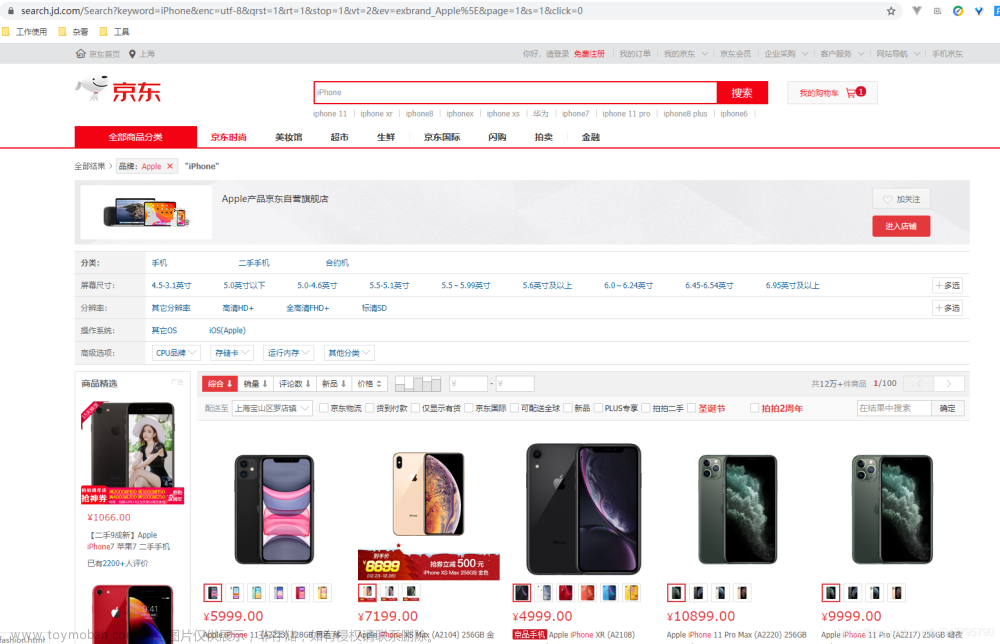
Python爬虫实战:selenium爬取电商平台商品数据
目标 先介绍下我们本篇文章的目标,如图: 本篇文章计划获取商品的一些基本信息,如名称、商店、价格、是否自营、图片路径等等。 准备 首先要确认自己本地已经安装好了 Selenium 包括 Chrome ,并已经配置好了 ChromeDriver 。如果还没安装好,可以参考前面的前置准备。 分析
-
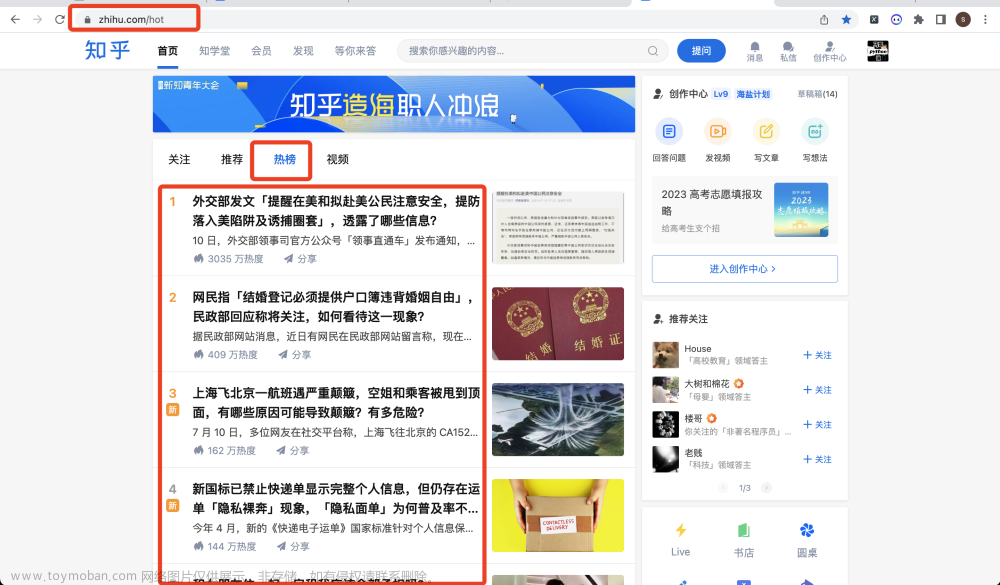
【爬虫案例】用Python爬取知乎热榜数据!
目录 一、爬取目标 二、编写爬虫代码 三、同步讲解视频 3.1 代码演示视频 3.2 详细讲解视频 四、获取完整源码 您好,我是@马哥python说,一名10年程序猿。 本次爬取的目标是:知乎热榜 共爬取到6个字段,包含: 热榜排名, 热榜标题, 热榜链接, 热度值, 回答数, 热榜描述。 用
-
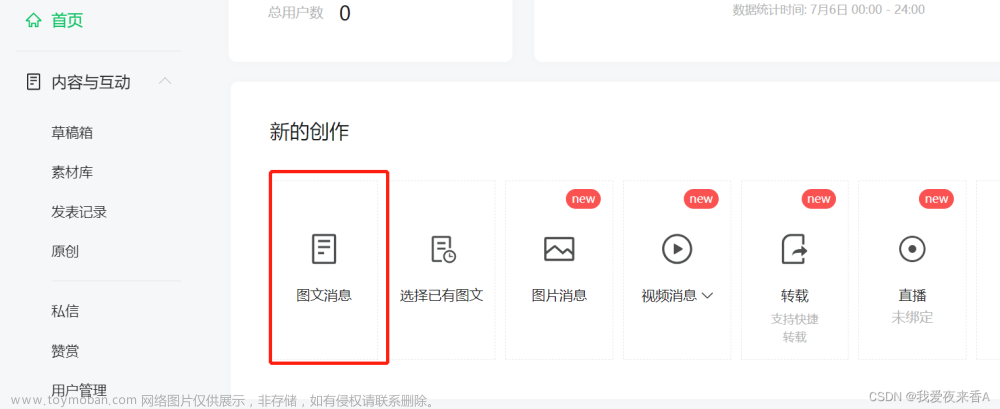
python学习:爬虫爬取微信公众号数据
参考: https://blog.csdn.net/qq_45722494/article/details/120191233 1、登录微信公众平台 这里我注册了个微信公众号 点击图文消息 点击超链接 搜索要爬取的公众号名称 获取appmsg?action… 上述第一步可以获取到cookie、fakeid、token、user_agent等,编辑成wechat.yaml文件,如下所示 代码如下: 因为阅读
-

【爬虫案例】用Python爬取抖音热榜数据!
目录 一、爬取目标 二、编写爬虫代码 三、同步讲解视频 3.1 代码演示视频 四、获取完整源码 您好,我是@马哥python说,一名10年程序猿。 本次爬取的目标是:抖音热榜 共爬取到50条数据,对应TOP50热榜。含5个字段,分别是: 热榜排名,热榜标题,热榜时间,热度值,热榜标签。
-

Python爬虫:从后端分析为什么你爬虫爬取不到数据
仅仅是小编总结的三点而已,可能不是很全面,如果之后小编了解到新的知识点,可能还会增加的哈! 1. 最简单的爬虫代码 也就是各位最常使用的,直接利用requests模块访问当前网站链接,利用相关解析模块从而获取得到自己想要的数据,如下(利用python爬虫爬取自己csdn个人
-

Python爬虫实战:selenium爬取电商平台商品数据(1)
def index_page(page): “”\\\" 抓取索引页 :param page: 页码 “”\\\" print(‘正在爬取第’, str(page), ‘页数据’) try: url = ‘https://search.jd.com/Search?keyword=iPhoneev=exbrand_Apple’ driver.get(url) if page 1: input = driver.find_element_by_xpath(‘//*[@id=“J_bottomPage”]/span[2]/input’) button = driver.find_element_by_xpath(‘
-
Python爬虫 | 爬取微博和哔哩哔哩数据
目录 一、bill_comment.py 二、bili_comment_pic.py 三、bilibili.py 四、bilihot_pic.py 五、bilisearch_pic.py 六、draw_cloud.py 七、weibo.py 八、weibo_comment.py 九、weibo_comment_pic.py 十、weibo_pic.py 十一、weibo_top.py 十二、weibo_top_pic.py 十三、weibo_top_pie.py 十四、pachong.py 十五、代码文件说明 pachong: b站、
-
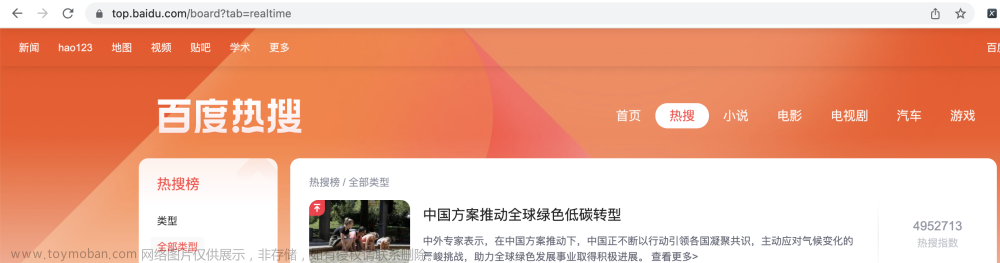
【爬虫案例】用Python爬取百度热搜榜数据!
目录 一、爬取目标 二、编写爬虫代码 三、同步视频讲解 四、完整源码 您好,我是@马哥python说,一名10年程序猿。 本次爬取的目标是:百度热搜榜 分别爬取每条热搜的: 热搜标题、热搜排名、热搜指数、描述、链接地址。 下面,对页面进行分析。 经过分析,此页面有XH
-
如何使用python实现简单爬取网页数据并导入MySQL中的数据库
前言:要使用 Python 爬取网页数据并将数据导入 MySQL 数据库,您需要使用 Requests 库进行网页抓取,使用 BeautifulSoup 库对抓取到的 HTML 进行解析,并使用 PyMySQL 库与 MySQL 进行交互。 以下是一个简单的示例: 1. 安装所需库: ``` ``` 2. 导入所需库: ``` ``` 3. 建立数据库连接:
-
python爬虫爬取中关村在线电脑以及参数数据
python爬虫爬取中关村在线电脑以及参数数据 2.1vsCode 2.2Anaconda version: conda 22.9.0 3.1 代码 解析都在代码里面 3.2 结果展示 这是保存到数据,用json保存的